分布式锁
1 什么是分布式锁?
在讨论分布式锁之前,我们先假设一个业务场景:
1.1 业务场景
在电商系统中,用户购买商品需要扣减库存,一般扣库存有两种方式:
下单减库存
优点:用户体验好,下单成功,库存直接扣减,用户支付不会出现库存不足。
缺点:用户一直不付款,这个商品的库存就会被占用,其他人无法购买。
支付减库存
优点:不会导致库存被恶意锁定,对商家有利。
缺点:用户体验不好,用户支付时可能商品库存不足了,会导致交易失败。
那么,我们一般为了用户体验,会采用下单减库存,为了解决下单减库存的缺陷,会创建一个定时任务,定时去清理超时未支付的订单。
这个定时任务主要包含以下步骤:
- 查询超时未支付的订单,获取订单中的商品信息。
- 修改未支付订单的状态,改为取消。
- 恢复订单中商品扣减的库存。

如果我们给订单服务搭建一个 100 个节点的超时订单检查服务集群,那么就会同时有 100 个定时任务触发并执行,设想一下这样的场景:
- 订单服务 A 和 B 同时执行了步骤 1。
- 它们返回了同样的商品和订单信息。
- 订单服务 A 执行了步骤 2 和 3。
- 订单服务 B 执行了步骤 2 和 3。 商品库存再次被增加。
因为任务的并发执行,出现了线程安全问题,商品库存被增加多次。
为什么需要分布式锁
对于线程安全问题,传统的方法是给对线程操作的资源代码加锁。

理想状态下,加了锁以后,在当前订单服务执行时,其他订单需要等待当前服务完成业务后才能执行,这样就避免了线程安全的问题。实际上这样并不能解决问题。
1.2.1 线程锁
我们通常使用的 synchronized 和 Lock 都是线程锁,对同一个 JVM 进程内的多个线程有效。因为锁的本质是在内存中存放一个标记,记录获取锁的线程是谁,这个标记对每个线程都可见。
因此,锁生效的前提是:
互斥:锁的标记只有一个线程可以获取。
共享:标记对所有线程可见。
然而我们启动了多个订单服务,就是多个 JVM,内存中的锁显然是不共享的。为了解决这个问题,能够保证各个订单服务能够共享内存的锁,分布式锁就派上用场了。
1.2.2 分布式锁
分布式锁将锁的标记变为进程可见,保证这个任务同一时刻只能被多个进程中的某一个执行,那么这就是一个分布式锁。
分布式锁有多种实现方式,基本原理类似,只要满足如下要求即可:
- 多进程可见
- 互斥:同一时刻只能有一个进程获得锁,执行任务后释放锁。
- 可重入(可选):同一个任务再次获取锁时不会死锁。
- 阻塞锁(可选):获取失败时,具备重试机制,尝试再次获取锁。
- 高并发,高可用(可选)。
常见的实现方案包括:基于数据库实现,基于 Redis 实现,基于 Zookeeper 实现。
2 Redis 实现分布式锁
2.1 基本实现
我们先关注其中的两个必要条件:
- 多进程可见
- 互斥,锁可以释放
1) Redis 本身就是基于 JVM 之外的,因此满足多进程可见的要求。
2) 互斥,互斥是说只有一个进程能获取锁标记,这个我们可以基于 Redis 的 setnx 指令来实现。setnx 是 set when not exist 的意思。当多次执行 setnx 命令时,只有第一次执行能成功,返回1,其余均返回0。
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> SETNX lock 001
(integer) 1
127.0.0.1:6379> get lock
"001"
127.0.0.1:6379> SETNX lock 002
(integer) 0
127.0.0.1:6379> get lock
"001"多个进程对同一个 key 进行 setnx 操作,只有一个会成功,满足了互斥的需求。
3) 释放锁
释放锁其实只需要把锁的 key 删除即可,使用 del 指令。不过还需要思考一个问题,如果我们的服务器突然宕机,那么这个锁是不是就永远无法删除了那?
为了避免服务器宕机引起的锁无法释放的问题,我们可以再获取锁的时候,给锁加一个有效时间,超时自动释放,避免了锁永远不释放的问题。
SETNX 指令没有设置时间的功能,因此需要使用 set 指令,然后结合 set 的 NX 和 PX 参数来完成。
EX:过期时长,单位是秒。PX:过期时长,单位是毫秒。NX:等同与 SETNX。
127.0.0.1:6379> set lock 001 NX EX 30
OK
127.0.0.1:6379> set lock 002 NX EX 30
nil (第二次执行失败)
127.0.0.1:6379> ttl lock
(integer) 12
127.0.0.1:6379> get lock
"001"
127.0.0.1:6379>
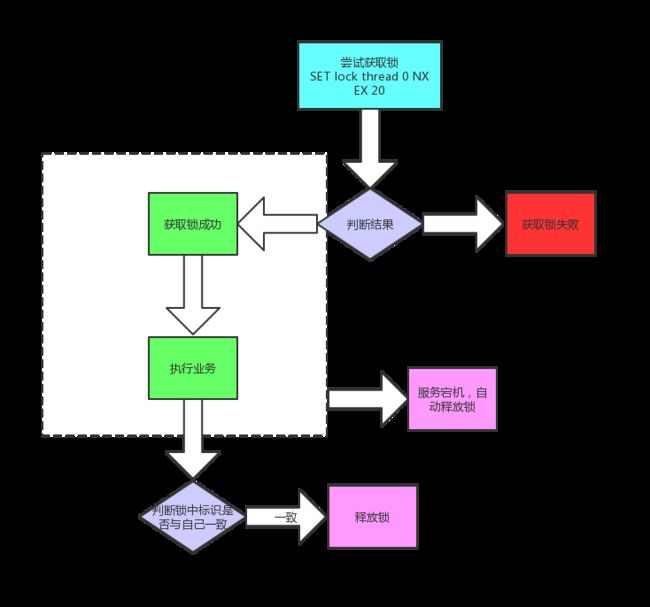
步骤:
- 通过 set 命令设置锁
- 判断返回结果是否 OK。
- Nil,失败,结束或者重试(自旋锁)
- OK,获取成功
- 执行业务
- 释放锁
- 异常情况,服务宕机,超时自动释放锁。
2.2 互斥性
上面的版本中,会有一定的安全问题。
- 3个进程,A,B 和 C 在执行任务,并争抢锁,此时 A 获得了锁,并设置自动释放锁时间为 10s。
- A 开始执行业务,因为时间较长,超过了10s,此时锁被自动释放了。
- B 抢到锁开始执行,此时 A 执行完毕,删除锁,于是 B 刚得到的锁又被释放了,而 B 的业务其实还在执行。
- C 获得了锁,开始执行。
问题出现了,B 和 C 同时获取到了锁,违反了互斥性。其实问题就是当前线程删除了其他线程的锁。
那么如何判断当前获取的锁是不是自己的锁那?
可以在 set 锁时,存入当前线程的唯一标识,删除之前判断一下这个标识是不是自己的,如果不是自己的,就不要删除。
2.3 重入性
如果我们在获取锁以后,执行代码的过程中,再次尝试获取锁,执行 setnx 肯定会失败,因为锁已经存在了。这样可能会导致死锁,这样的锁就是不可重入的。
重入锁
可重入锁,也叫所递归锁,指的是在同一个线程内,外层函数获得锁之后,内层递归函数仍然可以获取到该锁。同一个线程再次进入到同步代码块时,可以使用自己已获取到的锁。
实现:
- 获取锁:首先尝试获取锁,如果获取失败,判断这个锁是否是自己的,如果是则允许再次获取,而且必须记录重复获取锁的次数。
- 释放锁:释放锁不能直接删除了,因为锁是可重入的,如果锁进入了多次,在最内层直接删除锁,导致外部的业务在没有锁的情况下执行,会有安全问题。因此必须获取累计的重入次数,释放时减去重入次数,如果减到了 0,则可以删除锁。
因此,存储在锁中的信息就必须包含:key,线程标识,可重入次数,需要使用 hash 结构。
- EXISTS key:判断一个 key 是否存在。
- HEXISTS key field:判断一个 hash 的 field 是否存在。
- HSET key field value:给一个 hash 的 field 值增加指定数值。
- HINCRBY key field increment:给一个 hash 的 field 值增加指定数值。
- EXPIRE key seconds: 给一个 key 设置过期时间。
- DEL key:删除指定 key。

假设我们设置的锁的 key 为 lock, hashKey 为当前线程的 id:“threadID”,锁自动释放的时间为 20 秒。
获取锁的步骤:
- 判断 lock 是否存在
EXISTS lock- 存在,说明有获取获取锁了,下面判断是不是自己的锁
- 判断当前线程的 id 座位 hashKey 事发后存在
HEXISTS lock threadId - 不存在,说明锁已经有了,且不是自己获取的,获取锁失败,结束。
- 存在,说明锁是自己的,重入次数 +1,
HINCRBY lock threadId 1, 去到步骤 3。
- 判断当前线程的 id 座位 hashKey 事发后存在
-
- 不存在,说明可以获取锁,
HSET key threadId 1。
- 不存在,说明可以获取锁,
-
- 设置锁的自动释放时间,
EXPIRE lock 20。
- 设置锁的自动释放时间,
- 存在,说明有获取获取锁了,下面判断是不是自己的锁
释放锁的步骤:
- 判断当前线程 id 作为 hashkey 是否存在:
HEXISTS lock threadId。- 不存在,说明锁已经失效,结束
- 存在,说明锁还在,重入次数减一:
HINCRBY lock threadId -1,获取新的重入次数。
- 判断重入次数是否为0:
- 为 0,说明锁全部释放,删除 key,
DEL Lock。 - 大于 0,说明锁还在使用,重置有效时间:
EXPIRE lock 20。
- 为 0,说明锁全部释放,删除 key,
2.4 Lua 脚本
上面探讨的实现方案都需要多行 redis 命令才能实现,这时我们就需要考虑原子性的问题,如果不能保证原子性,整个过程的问题还是很大的。
Redis 中使用 Lua 脚本来保证原子性。
执行 Lua 脚本
EVAL script numkeys key [key ...] arg [arg ...]
summary: Execute a lua script server side
since: 2.6.0- script:脚本内容,或者脚本地址。
- numkeys:脚本中用到的 key 的数量,接下来 numkeys 个参数会作为 key 参数,剩下的作为 arg 参数。
- key: 作为 key 的参数,会被存入脚本环境中的 KEYS 数组,角标从 1 开始。
- arg: 其他参数,会被存入脚本环境中的 ARGV 数组,角标从 1 开始。
缓存 Lua 脚本
SCRIPT LOAD script
summary: Load the specified lua script into the script cache.
since: 2.6.0将一段脚本缓存起来,生成一个 SHA1 值并返回,作为脚本字典的 key,方便下次使用,参数 script 就是脚本内容或者地址。
127.0.0.1:6379>
127.0.0.1:6379> SCRIPT LOAD "return 'hello world!'"
"absd9sd9fsdjdkfjs9ds0d0r1klj1209i"
127.0.0.1:6379>此处返回的 absd9sd9fsdjdkfjs9ds0d0r1klj1209i 就是脚本缓存后得到 sha1 值。
执行缓存脚本
EVALSHA sha1 numkeys key[key ...] arg[arg ...]
summary: Execute a lua script server side
since: 2.6.0与 EVAL 类似,执行一段脚本,区别是通过脚本的 sha1 值,去脚本缓存中查找,然后执行。
Lua 基本语法
1)变量声明
局部变量,使用 local 关键字即可:
local a = 1232)打印结果
print('hello world')3)条件控制
if()
then
....
else if()
then
....
else
.....
end 4)循环语句
while(ture)
do
print('')
end 5)Lua 调用 Reids 指令
当我们在 Redis 中允许 Lua 脚本时,有一个内置变量 redis,并且具备两个函数:
- redis.call("命令名称","参数1","参数2"......), 执行指定的 redis 命令,遇到错误会直接返回错误。
- redis.pcall("命令名称","参数1","参数2"......), 执行指定的 redis 命令,遇到错误会以 Lua 表的形式返回。
例如:
redis.call('SET','num','123');运行这段 Lua 脚本的含义就是执行 Redis 命令:set num 123。
我们编写 Lua 脚本时并不希望把 set 后面的 key 和 value 写死,而是可以由调用脚本的人来指定,把 key 和 value 作为参数传入脚本执行。Lua 脚本中使用内置变量来接收用户传入的 key 和 arg 参数。
- KEYS: 用来存放 key 参数。
- ARGV:用来存放 key 以外的参数。
我们在脚本中可以从数组中根据角标取出用户传入的参数。
reids.call('SET',KEYS[1],ARGV[1])编写分布式锁脚本
1) 普通互斥锁
-- 判断锁是否是自己的
if(redis.call('GET',KEYS[1]) == ARGV[1]) then
-- 是则删除锁
return redis.call('DEL',KEYS[1])
end
-- 不是则直接返回
return 02) 可重入锁
获取锁:
local key = KEYS[1]; --锁的 key
local threadId = ARGV[1]; -- 线程唯一标识
local releaseTime = ARGV[2]; -- 锁的自动释放时间
if(reids.call('exists', key) == 0) then --判断是否存在
redis.call('hset',key,threadId,'1'); -- 不存在,获取锁,设置重入次数
reids.call('expired',key,releaseTime); -- 设置有效期
return 1; -- 返回结果
end;
if(redis.call('hexists',key,threadId) == 1) then -- 锁已经存在,判断 threadId 是否是自己的
redis.call('hincrby',key,threadId,'1'); -- 是自己,获取锁,重入次数加1。
redis.call('expired',key,releaseTime); -- 设置有效期
return 1; -- 返回结果
end;
retun 0; -- 走到这里,说明获得锁的线程不是自己,获取锁失败释放锁:
local key = KEYS[1]; --锁的 key
local threadId = ARGV[1]; -- 线程唯一标识
local releaseTime = ARGV[2]; -- 锁的自动释放时间
if(redis.call('HEXISTS',key,threadId) == 0) then -- 判断当前锁是否被自己持有
return nil; --如果不是自己,则直接返回
end;
local count = reis.call('HINCRBY',key,threadId,-1); --是自己的锁,则重入次数减一
if(count > 0) then
redis.call('EXPIRE',key,releaseTime);
return nil;
else
reids.call('DEL',key); -- 等于0署名可以释放锁,直接删除
return nil;
end; Zookeeper 实现分布式锁
Zookeeper 是一种提供配置管理,分布式协同以及命名的中心化服务。
Zookeeper 包含一系列的节点,叫做 znode,好像文件系统一样,每一个 znode 表示一个目录。znode 有一些特性:
- 有序节点:加入当前父节点为 /lock, 我们可以在这个父节点下面创建子节点,生成子节点的序号可以是有序的。
- 临时节点:客户端可以建立一个临时节点,在会话结束或者超时后,zookeeper 会自动删除该节点。
- 事件监听:在读取数据时,我们可以同时对节点设置监听事件,当节点数据或者结构发生变化时,zookeeper 会通知客户端。
Zookeeper 分布式锁的落地方案:
- 使用 zookeeper 的临时节点和有序节点,每个线程获取锁就是在 zookeeper 创建一个临时有序节点,比如在 /lock/ 目录下。
- 创建节点成功后,获取 /lock 目录下所有临时节点,在判断当前线程创建的节点是否是所有节点的序号的最小节点。
- 如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
- 如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点一个事件监听。比如当前线程获取到的节点序号为 /lock/003, 则对 /lock/002 添加一个事件监听。
- 如果锁释放了,会唤醒下一个序号的节点,然后重新执行第三步,判断是否自己是序号最小的节点。
来看看 Zookeeper 是否满足分布式锁的一些特性:
- 互斥:因为只有一个最小节点,因此满足互斥性。
- 锁释放:使用 Zookeeper 可以有效解决锁无法释放的问题,因为在创建锁的时候,客户端会在 ZK 中创建一个临时节点,一但客户端获取到锁后突然挂掉,这个临时节点会自动删除,其他客户端就可以再次获得锁。
- 阻塞锁,使用 Zookeeper 可以实现阻塞的锁,客户端可以通过创建顺序节点,并且在节点上绑定监听,一旦节点有变化,Zookeeper 会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就可以获取到锁,便可以执行业务逻辑了。
- 可重入,使用 Zookeeper 也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息写入到节点中,下次想要获取锁的时候和当前最小节点中的数据对比一下就可以了。如果和自己的信息一样,那么自己可以直接获取到锁,如果不一样就在创建一个临时的顺序节点,参与排队。
- 高可用:使用 Zookeeper 可以有效低解决单点问题,ZK 是集群部署的。
- 高性能:Zookeeper 集群是满足强一致性的,因此牺牲一些性能,与 Redis 相比略显不足。
总结
Redis 实现:实现比较简单,性能最高,但是可靠性难以维护。
Zookeeper:实现最简单,可靠性最高,性能比 Redis 低。
下一章我们会对市面上成熟的分布式锁框架进行介绍,并且会将这一章的代码进行完善和测试。