容器

容器与虚拟机对比图(左边为容器、右边为虚拟机)
容器技术是虚拟化技术的一种,以Docker为例,Docker利用Linux的LXC(LinuX Containers)技术、CGroup(Controll Group)技术和AUFS(Advance UnionFileSystem)技术等,通过对进程和资源加以限制,进行调控,隔离出来一套供程序运行的环境。 我们把这一环境称为“容器”,把构建该“容器”的“只读模板”,称之为“镜像”。
容器是独立的、隔离的,不同容器间不能直接通信,容器与宿主机也是隔离开来的,容器不能直接感知到宿主机的存在,同时宿主机也无法直接窥探容器内部。
虽然容器与宿主机在环境上,逻辑上是隔离的,但容器与宿主机共享内核,容器直接依赖于宿主机Linux系统的内核,这与虚拟机不同,后者是在宿主机的操作系统上,虚拟化一套硬件环境,然后在此环境上运行需要的操作系统。容器技术常用来在宿主机上隔离出环境来部署应用(用容器化技术部署的应用称为 “容器化应用” ),而虚拟机常用来运行一个与宿主机不同的操作系统,从而运行特定的软件。
容器非常轻量级,无论是启动速度,资源占用情况,灵活性等均优于虚拟机。容器的特性给开发生产提供了非常大的便利:
- DevOps理念,开发者可以使用同一个镜像,在开发环境、测试环境和生产环境构建相同的容器,即相同的程序运行环境,这样可以大大减少前期的环境部署时间,可以有效避免由于各个环境不一致而造成的灾难。
- “容器”与“微服务”常是一起出现的一组名词,有了容器技术以后,可以更加方便的部署微服务,例如,可以把评论服务部署到一个容器里,把阅读的服务部署到另一个容器,这样在一个服务崩溃时不至于影响到其它服务,再者,容器启动速度快,可以在极短时间内恢复。
- 很多时候,一些环境、工具需要复用,这时候容器是个很好的选择,我们可以把环境和工具打包成镜像,需要的时候用来构建容器使用。在Docker的镜像仓库上,也有很多官方的或第三方的镜像,这些镜像都是别人已经打包好的工具或者环境,我们只需一条命令,就可以把镜像拉取下来并构建容器启动,免去了自己动手开发部署的麻烦。
Docker技术解析
集群
计算机是独立的,但我们可以通过一系列技术、软件,把分散的算力有效的集中起来,把多台独立的计算机当做一个整体来使用,而且这些计算机实现相同的业务,这就是集群。
分布式
分布式就是把一个系统拆分开来部署到不同机器,与集群相同的是,两者都需要多台服务器,不同点是分布式并不强调实现相同的业务。貌似网上大多数资料,对于集群和分布式的区分,都执着于两者是否实现相同的业务,即不同服务器运行同一份功能就是集群,运行不同功能就是分布式。个人看法是,集群强调的是“集”、“统一的概念”,是物理上的、环境上的概念,只要是多台计算机搞在一起就是集群;而分布式,更多的是描述应用系统的部署方式,把一个系统拆开部署到不同服务器,就是分布式。这里有一篇关于分布式和集群的文章——浅谈集群与分布式的区别
微服务
有必要提一下微服务,使用kubernetes可以更加便捷地部署微服务应用。微服务和分布式都强调“拆”、“分”,但微服务描述的是应用系统的架构,即怎么样把系统拆分,拆成多“微”,这是微服务需要考虑的;而分布式,强调的是“分布”,即系统的部署方式,该怎么把系统的模块分布好,从而提高容灾能力、高可用性。当“微服务”应用部署到一台服务器上,它就是“微服务应用”,当把“微服务”应用的模块分开来部署到不同服务器,那么它也成了“分布式应用”。
关于“集群”、“分布式”、“微服务”三者的联系与区别——微服务,分布式,集群三者区别联系
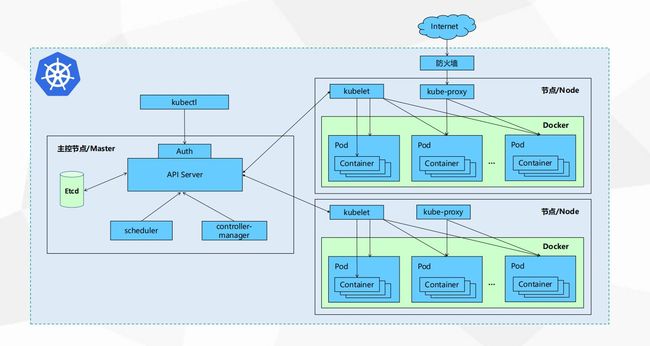
kubernetes
"kubernetes"这个词比较长,常简写成k8s,"8"表示中间的8个字母。k8s是谷歌开源的用于管理 “容器化应用” 和服务的平台,可用于自动部署、扩展和管理“容器化(containerized)应用程序”。可以通过一条命令或一份配置文件实现自动创建容器并部署应用,还提供应用容器的自动化管理功能(自动扩容、自动缩容)。k8s支持搭建集群,因此,k8s也是容器化集群管理平台,它旨在提供“跨主机集群的自动部署、扩展以及运行应用程序容器的平台”,它支持一系列容器工具, 包括Docker等。通过k8s以及容器引擎(Docker或rtk或其它),可以非常方便快速地搭建集群环境。这样部署出来的集群有一个特点——容器化,在集群中部署的应用,都是采用容器化的方式进行部署,即把应用放到容器中运行,至于这个容器是在集群中哪个节点运行,就交由集群管理人员和k8s控制。
通过k8s,能够进行应用的自动化部署和扩缩容,k8s可以根据事先配置好的配置文件,实时监控容器的运行状态,当容器出现问题时,k8s会自动地重建容器,当负载上升时,k8s会自动扩容,创建新的容器。k8s会尽量地维持容器的数量,当容器出现问题不能运行时,它会被删除,同时k8s会新建容器,以满足配置文件指定的容器数量要求。这里说“容器”其实并不恰当,因为k8s的基本调度单位是“pod”,下文会介绍。
以上都是比较笼统的说法,可以用稍微专业一点的术语来描述,k8s根据其特点,可以归纳成如下的功能:
跨主机的自动化容器编排管理平台
k8s以“Pod”为基本单位跨主机管理容器,“Pod”是一组(或一个)容器的集合。k8s监控集群中各个节点(主机)上Pod的健康状态,能够利用用户配置的“控制器”,及时地剔除不健康的Pod,同时创建新的健康的Pod来替代原来的Pod,这整个过程都是自动化的,用户只需配置Pod的“控制器”,其余操作均由k8s系统完成。
Pod“控制器”一般包含“replicas”属性,在介绍该属性前,先引入“副本”的概念——一个Pod可以被复制成多份,每一份可被称之为一个“副本”,这些“副本”除了一些描述性的信息(Pod的名字、uid等)不一样以外,其它信息都是一样的,譬如Pod内部的容器、容器数量、容器里面运行的应用等的这些信息都是一样的,这些副本提供同样的功能。“replicas”属性则指定了特定Pod的副本的数量,当当前集群中该Pod的数量与该属性指定的值不一致时,k8s会采取一些策略去使得当前状态满足配置的要求。
Pod是要被分配到节点(主机)中去运行的,至于要被分配到那个节点去,可以由用户去配置,默认情况下,k8s系统会根据各个节点的资源状况(当前资源的分配情况、资源的最大配额等信息),采取合适的分配策略对Pod进行调度,对资源进行调度。这里的资源是指CPU资源、内存资源等等。微服务部署平台
鉴于k8s有以上所描述的如此优良的特性,使用k8s来部署微服务应用是极佳的,k8s也提供了很多可以实行微服务部署的功能。
可以基于上述的k8s的Pod编排技术,实现微服务的服务编排、服务快速部署。
k8s提供了service的概念,service是对Pod访问方式的抽象,service就是“服务”,service与一组Pod挂钩,Pod实现某些功能,service就是利用Pod的“功能”,利用“Pod”的能动性,对外提供“服务”。service对请求进行路由,负载均衡到它后面与之挂钩的Pod。利用service,可以实现微服务的服务自动发现和路由。
k8s的一些Pod“控制器”可以提供Pod的“滚动更新”功能,如果你的应用升级了,譬如原来应用是v1版本,现在的版本是v2,那么可以通过仅仅一条命令或一份配置文件,让k8s来自动地滚动更新应用。k8s会删除一个v1的Pod,然后新建一个v2的Pod……这样反复交替操作,直至所有v1Pod被v2Pod代替,这样就实现了不停机的应用滚动更新。k8s会保存应用的更新记录,在需要“回滚降级”时,同样可以通过仅仅一条命令或者一个配置文件实现。
服务伸缩。当遇到类似“双十一”这样的时效性的业务需求时,可以充分利用到k8s了。如上面提到的“replicas”属性,该属性可以用来指定Pod的副本数量,当业务量增大时,可以修改该属性值,让k8s创建更多的Pod来处理请求,相应的,当业务量减少时,为了节约资源,可以减少该属性的值。这样就实现了服务的动态伸缩,用户只需修改配置,实际操作交由k8s负责。
更多资料:
一文读懂kubernetes
k8s-整体概述和架构。
干货满满!10分钟看懂Docker和K8S
万维百科kubernetes
k8s基础概念解析
Pod
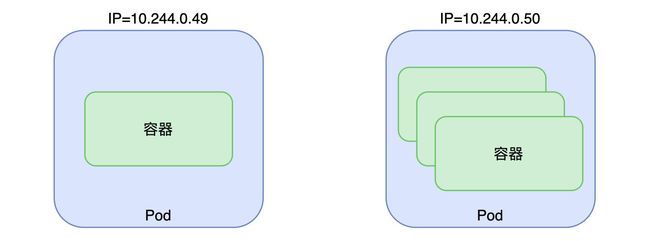
Pod是k8s的基本调度单位,Pod包含一个或一组Container(容器),这些Container共享Pod的IP(k8s中每一个Pod都有各自的IP,这些IP被称作PodIP),所以一个Pod内的Container可以通过localhost+各自的端口进行通信,跨Pod的容器之间的通信,则通过对应的PodIP+端口进行。再次提到,Pod是k8s的基本调度单位,所以要想运行一个Container,必须先为其创建一个Pod。
Pod是容器的运行环境,而我们的应用程序是部署在容器里的,对于k8s的初学者,可以先把Pod简单地看作为应用的运行容器,把Pod看作是应用在k8s上部署的最小单位。
更多资料:
- k8s官方文档Pod部分
Service
PodIP是在集群内部的IP,外网无法访问,相应的,Pod也是不能被外部访问的,Pod只能在集群内部被直接访问,那么如何在外网访问Pod里面部署的网站、应用?那就是上文提到的service。
service是对Pod访问方式的一种抽象。当请求发送给service,service再把请求路由到与之挂钩的Pod。在k8s中,service被用来给Pod暴露(expose)服务,service暴露的服务不仅仅是用来给外网访问,内网也是可以使用的。默认情况下,service被配置为ClusterIp模式,在该模式下,也是只有集群内部的网络才能访问到该service,要想真正的实现外网访问service,需要把service访问方式配置为NodePort或用其它方式(ingress、loadbalancer等)。
service降低了k8s中Pod的耦合度。使用服务的Pod(称为“前端”frontend)和提供服务的Pod(称为“后端”backend)不是耦合在一起的。backend随时会变动(Pod可能因为某些原因被销毁又重建),frontend并不关心它实际上调用哪个backend副本,他只关心service的状态,而backend的状态,则转交给了service去跟踪。
更多资料:
- k8s官方文档Service部分
Node(节点)
一个node,就是k8s集群中的一个服务器,node分为Master Node和Worker Node。
Master Node
顾名思义,Master Node就是集群中的控制中心,负责整个集群的控制、管理。默认情况下,在部署集群时master会被分配一个名为NoSchedule的Taint(污点),这个taint使得master节点不能被调度,也就是说新建Pod时,Pod不会被分配到master节点。
Worker Node
Worker Node用于承载应用的运行,k8s会根据配置文件中的策略,对worker node进行调度,把pod分配到合适的worker node。
CRI(容器运行时接口)
全称"Container-Runtime-Interface",是一个接口,用来操作容器的接口。k8s通过CRI对容器进行操作,创建、启停容器等。安装kubeadm时会自动安装cri-tool。
从v1.6.0起,Kubernetes开始允许使用CRI。默认的容器运行时是Docker。其他的容器运行时有:containerd (containerd 的内置 CRI 插件)、cri-o、frakti、rkt。
CNI(容器网络接口)
全称"Container-Network-Interface",各种网络插件(network-plugin),如flannel、GCE等实现了该接口。cni用于给pod分配ip,用来划分网段,用来分配子网,用来管理k8s集群内部的网络模型。其配置文件里包含"--pod-network-cidr"参数,该参数表示用"cidr"(计算机网络基础的知识)给pod分配ip,参数的数值表示ip的前缀,比如flannel官方配置文件中的默认值为10.244.0.0/16,把10.244.0.0转换成二进制表示,取前面16位,即为给pod分配的ip的前缀。
更多资料:
- k8s官方文档网络部分
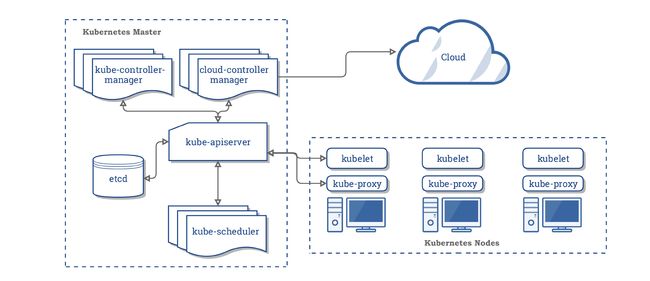
k8s组件简介
Kubectl(集群控制器)
kubectl全称"Kubernetes-Controller",运行于master节点,kubectl更像是“kubernetes-client”,类似于k8s的客户端,是k8s的控制工具,是一个命令行工具,是用户管理k8s集群的接口,负责把用户的指令传给API Server,用于集群中资源的增删查改,注意,kubeclt只是个交互接口,并不负责实际上的资源的增删查改。
在k8s中的所有内容都被抽象为“资源”,如Pod、Service、Node等都是资源。“资源”的实例可以称为“资源对象”,如某个具体的Pod、某个具体的Node。k8s中的资源有很多种,kubectl可以通过配置文件来创建这些“资源对象”,配置文件更像是描述对象“属性”的文件,配置文件格式可以是“JSON”或“YAML”,不过常用的是“YAML”。
更多资料:
- k8s中各种资源和对象的简述
Kubelet(节点代理)
运行在worker节点上,在使用kubeadm初始化集群时,master节点也需要kubelet。Kubelet全称"Kubernetes-Lifecycle-Event-Trigger",也是Kubernetes中最主要的控制器,kubelet被称为"Node Agent",意思是“节点上的代理”。如果说kubectl是决策者,那么kubelet相当于是管理者、执行者;如果说kubectl是总裁,那么kubelet就是各个分公司的总经理。
kubelet的主要工作如下:
pod管理:kubelet会监测本节点上pod、container的健康,出错时会根据配置文件的重启策略,对pod、container进行重启。 kubelet还会定期通过API Server获取本节点上的pod、container状态的期望值,然后调用容器运行时接口,对container进行调度,已达到期望。
资源监控:kubelet监控本节点资源使用情况,定时向master报告,知道整个集群所有节点的资源情况,对于pod的调度和正常运行至关重要。
API Server(网关)
API Server运行在master节点。对于整个k8s集群,可以把kubectl看做前端,看作集群管理员与k8s集群交互的接口。API Server则相当于后端的"Controller",负责对各个组件(包括kubectl)发来的请求进行分发、处理。各个组件都直接与API Server进行通信,也只能与API Server通信。
API Server提供了集群管理的接口,提供了资源的增删查改的接口,这个接口也可以直接说是API(web开发中的“API”)。值得一提的是,这些API都是是RESTful风格的API,这与k8s“万物皆资源”的理念相符。
另外,API Server也作为集群的网关。默认情况,客户端通过API Server对集群进行访问时,客户端需要通过认证,并使用API Server作为访问Node和Pod(以及service)的堡垒和代理/通道。
Etcd(集群信息存储)
运行在Master节点。etcd与zookeeper相似但又不同,在分布式中经常会见到,是一个键值存储仓库,用于配置共享和服务发现。接着上面讲的,etcd相当于后端中的数据库,用于存储集群中的所有状态,包括各个节点的信息,集群中的资源状态等等。etcd的watch机制可以在信息发生变化时,快速的通知集群中相关的组件。
Scheduler(调度器)
运行在Master节点。scheduler组件为容器自动选择运行的主机(node)。依据请求资源的可用性,服务请求的质量等约束条件,scheduler监控还未绑定到node的pod,对其进行绑定。Kubernetes也支持用户自己提供的调度器,Scheduler负责根据调度策略自动将Pod部署到合适Node中,调度策略分为预选策略和优选策略,Pod的整个调度过程分为两步:
1)预选Node:遍历集群中所有的Node,按照具体的预选策略筛选出符合要求的Node列表。如没有Node符合预选策略规则,该Pod就会被挂起,直到集群中出现符合要求的Node。
2)优选Node:预选Node列表的基础上,按照优选策略为待选的Node进行打分和排序,从中获取最优Node。
Controller-Manager(管理控制中心)
运行在Master节点。Controller-Manager用于执行大部分的集群层次的功能,它既执行生命周期功能(例如:命名空间创建和生命周期、事件垃圾收集、已终止垃圾收集、级联删除垃圾收集、node垃圾收集),也执行API业务逻辑(例如:pod的弹性扩容)。控制管理提供自愈能力、扩容、应用生命周期管理、服务发现、路由、服务绑定和提供。Kubernetes默认提供Replication Controller、Node Controller、Namespace Controller、Service Controller、Endpoints Controller、Persistent Controller、DaemonSet Controller等控制器。
Controller-Manager负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
友情链接
- k8s组件
- 在阿里云ECS的Ubuntu环境下部署单节点k8s集群
- 部署k8s的图形化管理平台kubernetes-dashboard