分析淘宝PDP
让我们先看个图, Taobao的PDP(Product Detail Page)页.
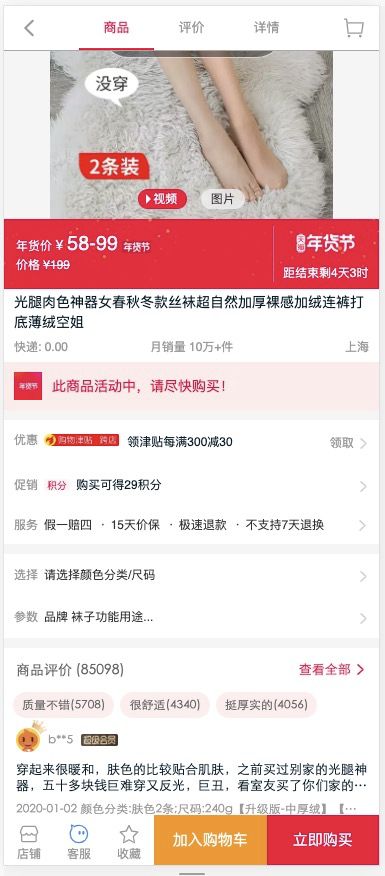
打开Chrome Network面板, 让我们来看taobao是怎么加载这个页面数据的. 根据经验, 一般是异步加载的, 要么是XHR,要么就是js(jsonp), 你应该很快可以找到
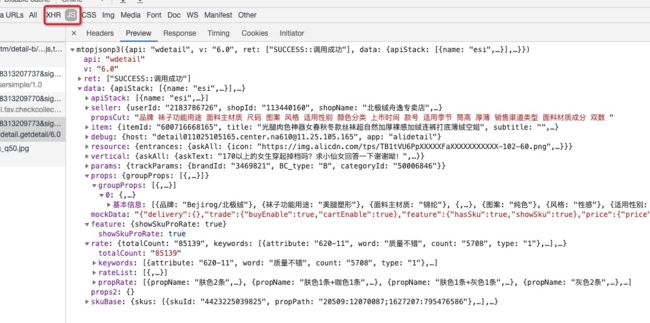
还能看到这个接口的性能
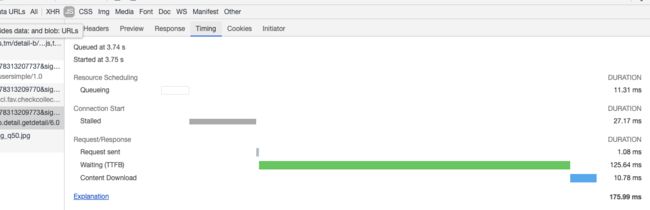
神奇的是, taobao竟然在一次请求中拉下了整个PDP页的完整数据, 而且服务端处理耗时不到125ms
首先, 这么做有什么好处?
- 前后端开发对接简单
- 在一次网络连接中尽可能多的传输数据(数据大小要不影响用户体验, 一般不会超过300kb), 减少建立连接的次数和请求头浪费的流量.
然后, 这又是怎么做到的呢?
你可能会说缓存, 但你要知道, 这样一个对电商极为重要的页面, 绝对涉及到了非常多的团队, 比如:
- 商品团队
- 卖家团队
- 评价团队
- 订单团队
- 会员团队
- 优惠团队
- 问答团队
- 推荐团队
- 物流系统
- etc/等等
即使每个团队的数据全都是缓存的, 你一个个去拿, 要在125ms内拿完也不容易. 而且作为跟钱相关的页面, 部分数据必须保证绝对实时有效, 能用缓存的地方不多. 怎么办, 如果是你, 你会怎么做? 离线打标? 数据预热? etc..
此时, 并行调用不失为一种好办法.
分析一下这个页面, 你会发现, 每一个模块除了属于同一个商品(入参相同), 其实各个模块的数据之间, 并没有依赖性, 完全可以并行去获取.
并行就没有问题了吗?
并行获取数据, 可以提高我们的接口性能. 但也会引入一些问题, 如:
- 依赖的项可能很多, 怎么使代码简洁清晰?
- 依赖关系很可能是一个有向图, 如果做到有向图中的每个节点都可以并行执行?
- 异步处理后, 超时怎么处理? 业务代码抛出异常了怎么处理?
- 依赖关系如果有死循环怎么办?
- 异步之后, ThreadLocal中的内容怎么处理? 一些基于ThreadLocal实现的Context不work怎么办?
- 事务被线程隔离了怎么办?
- 如何监控每一次异步执行, 每个节点的性能?
下面, 我们来讨论下如何简单\易用\高效的并行获取数据; 如何解决上述异步问题.
常见的并行方式
假如你现在需要用户的基础信息\博客列表\粉丝列表 3份数据. 哪么你有哪些方式可以并行获取呢?
Java ThreadPool并行
最简单原始的办法, 直接使用Java提供了的线程池和Future机制.
public User getUserDataByParallel(Long userId) throws InterruptedException, ExecutionException {
ExecutorService executorService = Executors.newFixedThreadPool(3);
CountDownLatch countDownLatch = new CountDownLatch(3);
Future userFuture = executorService.submit(() -> {
try{
return userService.get(userId);
}finally {
countDownLatch.countDown();
}
});
Future> postsFuture = executorService.submit(() -> {
try{
return postService.getPosts(userId);
}finally {
countDownLatch.countDown();
}
});
Future> followersFuture = executorService.submit(() -> {
try{
return followService.getFollowers(userId);
}finally {
countDownLatch.countDown();
}
});
countDownLatch.await();
User user = userFuture.get();
user.setFollowers(followersFuture.get());
user.setPosts(postsFuture.get());
return user;
} Spring的异步并行
我们知道, Spring支持@Async注解, 可以方便的实现异步, 并且支持获取返回值. 参考: https://www.baeldung.com/spring-async#2-methods-with-return-type
@Async实现的原理实际是在Bean的代理类的方法中, 拦截方法调用, 向taskExecutor Bean中提交Callable任务. 原理跟自己用Java ThreadPool写其实区别不大.
那么要用Spring Async实现上述功能. 首先需要修改下面3个方法的返回值, 并且修改返回值类型, 并为方法添加 @Async注解
class UserServiceImpl implements UserService {
@Async
public Future get(Long userId) {
// ... something
}
}
class PostServiceImpl implements PostService {
@Async
public Future getPosts(Long userId) {
// ... something
}
}
class FollowServiceImpl implements FollowService {
@Async
public Future getFollowers(Long userId) {
// ... something
}
} 并行获取3份用户数据然后聚合, 代码如下:
public User getUserDataByParallel(Long userId) throws InterruptedException, ExecutionException {
Future userFuture = userService.get(userId);
Future> postsFuture = postService.getPosts(userId);
Future> followersFuture = followService.getFollowers(userId);
User user = whileGet(userFuture);
user.setFollowers(whileGet(followersFuture));
user.setPosts(whileGet(postsFuture));
return user;
}
private T whileGet(Future future) throws ExecutionException, InterruptedException {
while(true) {
if (future.isDone()) {
break;
}
}
return future.get();
} 这里使用自旋去获取异步数据. 当然你也可以像前面那样, 传递一个闭锁(CountDownLatch)到Service中去, 然后让主调线程在一个闭锁上面等待.
并行结合DI(依赖注入)
上面2种方式的确能实现功能, 但首先, 它们都很不直观, 而且没有处理前面讲到的异步问题, 一旦出现超时\异常\ThreadLocal, 代码可能不会按照你预期的方式工作. 那有没有更简单方便可靠的方法呢?
试想这样一种方式, 如果你需要的数据, 都可以通过方法入参自动并行获取, 然后传递给你, 那是不是很方便? 就像这样:
@Component
public class UserAggregate {
@DataProvider("userWithPosts")
public User userWithPosts(
@DataConsumer("user") User user,
@DataConsumer("posts") List posts,
@DataConsumer("followers") List followers) {
user.setPosts(posts);
user.setFollowers(followers);
return user;
}
} 这里的@DataConsumer声明了你要异步获取的数据id. @DataProvider声明了这个方法提供数据, 并且id为userWithPosts.
或者你不想写这样一个Aggregate类, 你不需要复用, 你想直接创建一个"匿名Provider". 那么你可以直接在任何地方像下面这样调用拿结果
User user = dataBeanAggregateQueryFacade.get(
Collections.singletonMap("userId", 1L),
new Function3,List, User>() {
@Override
public User apply(@DataConsumer("user") User user,
@DataConsumer("posts") List posts,
@DataConsumer("followers") List followers) {
user.setPosts(posts);
user.setFollowers(followers);
return user;
}
});
Assert.notNull(user,"user not null");
Assert.notNull(user.getPosts(),"user posts not null"); 这里的Function3接收4个泛型参数, 最后一个User表示返回值类型, 前3个参数依次对应apply方法的3个入参类型. 项目预定义了Function2-Function5, 支持不超过5个参数, 如果你需要更多参数, 可以编写一个接口(FunctionInterface), 继承MultipleArgumentsFunction接口即可.
很显然
- 每一个
@DataConsumer只会对应一个@DataProvider. - 一个
@DataProvider可能被多个@DataConsumer消费 . - 一个
@DataProvider通过多个@DataConsumer依赖上多个@DataProvider.
你不用care底层如何实现. 只有在你有定制化的需求时, 才去关心一些配置参数. 去扩展一些能力.
实现原理

- 在Spring启动之时, 扫描应用中的
@DataProvider和@DataConsumer注解. 分析记录下依赖关系(有向非连通图), 并且记录好@DataProvider和Spring Bean的映射关系. - 当进行查询时, 从已经记录好的依赖关系中拿出依赖树, 使用线程池和闭锁(CountLatchDown), 递归异步调用孩子节点对应的Bean方法, 拿到结果后作为入参注入当前节点 (近似广度优先, 但因为并行的原因, 节点的访问顺序是不确定的).
- 在发起递归调用前, 传入进一个map, 用来存放查询参数, 方法中没有
@DataConsumer注解的入参, 将从此map中取值. @DataProvider和@DataConsumer注解可以支持一些参数, 用来控制超时时间\异常处理方式\是否幂等缓存等等.
怎么解决并行/异步后引入的新问题
超时怎么控制 ?
@DataProvider 注解支持 timeout 参数, 用来控制超时. 实现原理是通过闭锁的超时等待方法.
java.util.concurrent.CountDownLatch#await(long, java.util.concurrent.TimeUnit)异常怎么处理 ?
对异常提供两种处理方式: 吞没或者向上层抛出.
@DataConsumer 注解支持exceptionProcessingMethod 参数, 用来表示这个Consumer想怎么处理Provider抛出的异常.
当然, 也支持在全局维度配置. 全局配置的优先级低于(<)Consumer配置的优先级.
依赖关系有死循环怎么办 ?
Spring Bean初始化, 因为Bean创建和Bean属性赋值分了两步走, 因此可以用所谓的"早期引用"解决循环依赖的问题.
但如果你循环依赖的Bean, 依赖关系定义在构造函数入参上, 那么是没法解决循环依赖的问题的.
同理, 我们通过方法入参, 异步注入依赖数据, 在方法入参没有变化的情况下, 也是无法结束死循环的. 因此必须禁止循环依赖.
那么问题变为了怎么禁止循环依赖. 或者说, 怎么检测有向非联通图中的循环依赖, 两个办法:
- 带染色的DFS遍历: 节点入栈访问前, 先标记节点状态为"访问中", 之后递归访问孩子节点, 递归完成后, 将节点标记为"访问完成". 如果在DFS递归过程中, 再次访问到"访问中"的节点, 说明有环.
- 拓扑排序: 把有向图的节点排成一个序列, 不存在索引号较高的节点指向索引号较低的节点, 表示图存在拓扑排序. 拓扑排序的实现方法是, 先删除入度为0的节点, 并将领接节点的入度 - 1, 直到所有节点都被删除. 很显然, 如果有向图中有环, 那么环里节点的入度不可能为0 , 那么节点不可能删完. 因此, 只要满足节点未删完 && 不存在入度为0的节点, 那么一定有环.
这里我们用领接表+DFS染色搜索, 来实现环的检查
private void checkCycle(Map> graphAdjMap) {
Map visitStatusMap = new HashMap<>(graphAdjMap.size() * 2);
for (Map.Entry> item : graphAdjMap.entrySet()) {
if (visitStatusMap.containsKey(item.getKey())) {
continue;
}
dfs(graphAdjMap,visitStatusMap,item.getKey());
}
}
private void dfs(Map> graphAdjMap,Map visitStatusMap, String node) {
if (visitStatusMap.containsKey(node)) {
if(visitStatusMap.get(node) == 1) {
List relatedNodes = new ArrayList<>();
for (Map.Entry item : visitStatusMap.entrySet()) {
if (item.getValue() == 1) {
relatedNodes.add(item.getKey());
}
}
throw new IllegalStateException("There are loops in the dependency graph. Related nodes:" + StringUtils.join(relatedNodes));
}
return ;
}
visitStatusMap.put(node,1);
log.info("visited:{}", node);
for (String relateNode : graphAdjMap.get(node)) {
dfs(graphAdjMap,visitStatusMap,relateNode);
}
visitStatusMap.put(node,2);
} ThreadLocal怎么处理?
许多的框架都使用了ThreadLocal来实现Context来保存单次请求中的一些共享数据, Spring也不例外.
众所周知, ThreadLocal实际是访问Thread中一个特殊Map的入口. ThreadLocal只能访问当前Thread的数据(副本), 如果跨越了线程, 是拿不到到其他ThreadLocalMap的数据的.
解决方法

如图
- 在当前线程提交异步任务前, 将当前线程ThreadLocal执行的数据"捆绑"到任务实例中
- 当任务开始执行时, 从任务实例中取出数据, 恢复到当前异步线程的ThreadLocal中
- 当任务结束后, 清理当前异步线程的ThreadLocal.
这里, 我们先定义一个接口, 来描述这3个动作
public interface AsyncQueryTaskWrapper {
/**
* 任务提交之前执行. 此方法在提交任务的那个线程中执行
*/
void beforeSubmit();
/**
* 任务开始执行前执行. 此方法在异步线程中执行
* @param taskFrom 提交任务的那个线程
*/
void beforeExecute(Thread taskFrom);
/**
* 任务执行结束后执行. 此方法在异步线程中执行
* 注意, 不管用户的方法抛出何种异常, 此方法都会执行.
* @param taskFrom 提交任务的那个线程
*/
void afterExecute(Thread taskFrom);
}为了让我们定义的3个动作起作用. 我们需要重写一下 java.util.concurrent.Callable#call方法.
public abstract class AsyncQueryTask implements Callable {
Thread taskFromThread;
AsyncQueryTaskWrapper asyncQueryTaskWrapper;
public AsyncQueryTask(Thread taskFromThread, AsyncQueryTaskWrapper asyncQueryTaskWrapper) {
this.taskFromThread = taskFromThread;
this.asyncQueryTaskWrapper = asyncQueryTaskWrapper;
}
@Override
public T call() throws Exception {
try {
if(asyncQueryTaskWrapper != null) {
asyncQueryTaskWrapper.beforeExecute(taskFromThread);
}
return execute();
} finally {
if (asyncQueryTaskWrapper != null) {
asyncQueryTaskWrapper.afterExecute(taskFromThread);
}
}
}
/**
* 提交任务时, 业务方实现这个替代方法
*
* @return
* @throws Exception
*/
public abstract T execute() throws Exception;
} 接下来, 向线程池提交任务时, 不再直接提交Callable匿名类实例, 而是提交AsyncQueryTask实例. 并且在提交前触发 taskWrapper.beforeSubmit();
AsyncQueryTaskWrapper taskWrapper = new CustomAsyncQueryTaskWrapper();
// 任务提交前执行动作.
taskWrapper.beforeSubmit();
Future future = executorService.submit(new AsyncQueryTask你要做什么?
你只需要定义一个类, 实现这个接口, 并将这个类加到配置文件中去.
@Slf4j
public class CustomAsyncQueryTaskWrapper implements AsyncQueryTaskWrapper {
/**
* "捆绑" 在任务实例中的数据
*/
private Long tenantId;
private User user;
@Override
public void beforeSubmit() {
/* 提交任务前, 先从当前线程拷贝出ThreadLocal中的数据到任务中 */
log.info("asyncTask beforeSubmit. threadName: {}",Thread.currentThread().getName());
this.tenantId = RequestContext.getTenantId();
this.user = ExampleAppContext.getUser();
}
@Override
public void beforeExecute(Thread taskFrom) {
/* 任务提交后, 执行前, 在异步线程中用数据恢复ThreadLocal(Context) */
log.info("asyncTask beforeExecute. threadName: {}, taskFrom: {}",Thread.currentThread().getName(),taskFrom.getName());
RequestContext.setTenantId(tenantId);
ExampleAppContext.setLoggedUser(user);
}
@Override
public void afterExecute(Thread taskFrom) {
/* 任务执行完成后, 清理异步线程中的ThreadLocal(Context) */
log.info("asyncTask afterExecute. threadName: {}, taskFrom: {}",Thread.currentThread().getName(),taskFrom.getName());
RequestContext.removeTenantId();
ExampleAppContext.remove();
}
}添加配置使TaskWapper生效.
io.github.lvyahui8.spring.task-wrapper-class=io.github.lvyahui8.spring.example.wrapper.CustomAsyncQueryTaskWrapper怎么监控每一次的异步调用?
解决办法
我们先把一次查询, 分为以下几个生命周期
- 查询任务初次提交 (querySubmitted)
- 某一个Provider节点开始执行前 (queryBefore)
- 某一个Provider节点执行完成后 (queryAfter)
- 查询全部完成 (queryFinished)
- 查询异常 (exceptionHandle)
转换成接口如下
public interface AggregateQueryInterceptor {
/**
* 查询正常提交, Context已经创建
*
* @param aggregationContext 查询上下文
* @return 返回为true才继续执行
*/
boolean querySubmitted(AggregationContext aggregationContext) ;
/**
* 每个Provider方法执行前, 将调用此方法. 存在并发调用
*
* @param aggregationContext 查询上下文
* @param provideDefinition 将被执行的Provider
*/
void queryBefore(AggregationContext aggregationContext, DataProvideDefinition provideDefinition);
/**
* 每个Provider方法执行成功之后, 调用此方法. 存在并发调用
*
* @param aggregationContext 查询上下文
* @param provideDefinition 被执行的Provider
* @param result 查询结果
* @return 返回结果, 如不修改不, 请直接返回参数中的result
*/
Object queryAfter(AggregationContext aggregationContext, DataProvideDefinition provideDefinition, Object result);
/**
* 每个Provider执行时, 如果抛出异常, 将调用此方法. 存在并发调用
*
* @param aggregationContext 查询上下文
* @param provideDefinition 被执行的Provider
* @param e Provider抛出的异常
*/
void exceptionHandle(AggregationContext aggregationContext, DataProvideDefinition provideDefinition, Exception e);
/**
* 一次查询全部完成.
*
* @param aggregationContext 查询上下文
*/
void queryFinished(AggregationContext aggregationContext);
}在Spring应用启动之初, 获取所有实现了AggregateQueryInterceptor接口的Bean, 并按照Order注解排序, 作为拦截器链.
至于拦截器如何执行. 很简单, 在递归提交查询任务时, 插入执行一些钩子(hook)函数即可. 涉及到的代码很多, 就不贴在这里, 感兴趣的可以去github clone代码查看.
你要做什么?
你可以实现一个拦截器, 在拦截器中输出日志, 监控节点执行状态(耗时, 出入参), 如下:
@Component
@Order(2)
@Slf4j
public class SampleAggregateQueryInterceptor implements AggregateQueryInterceptor {
@Override
public boolean querySubmitted(AggregationContext aggregationContext) {
log.info("begin query. root:{}",aggregationContext.getRootProvideDefinition().getMethod().getName());
return true;
}
@Override
public void queryBefore(AggregationContext aggregationContext, DataProvideDefinition provideDefinition) {
log.info("query before. provider:{}",provideDefinition.getMethod().getName());
}
@Override
public Object queryAfter(AggregationContext aggregationContext, DataProvideDefinition provideDefinition, Object result) {
log.info("query after. provider:{},result:{}",provideDefinition.getMethod().getName(),result.toString());
return result;
}
@Override
public void exceptionHandle(AggregationContext aggregationContext, DataProvideDefinition provideDefinition, Exception e) {
log.error(e.getMessage());
}
@Override
public void queryFinished(AggregationContext aggregationContext) {
log.info("query finish. root: {}",aggregationContext.getRootProvideDefinition().getMethod().getName());
}
}项目地址
最后, 再次贴一下项目地址: . spring-boot-data-aggregator
欢迎拍砖, 欢迎star, 欢迎使用