数据生命周期

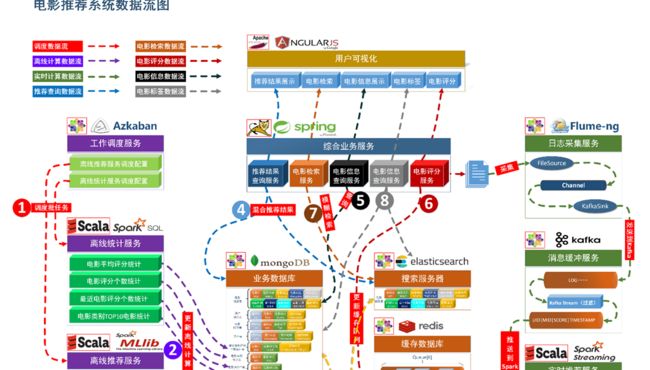
项目系统架构

用户可视化:主要负责实现和用户的交互以及业务数据的展示,主体采用AngularJS2进行实现,部署在Apache服务上。
综合业务服务:主要实现JavaEE层面整体的业务逻辑,通过Spring进行构建,对接业务需求。部署在Tomcat上。
【数据存储部分】
业务数据库:项目采用广泛应用的文档数据库MongDB作为主数据库,主要负责平台业务逻辑数据的存储。
搜索服务器:项目爱用ElasticSearch作为模糊检索服务器,通过利用ES强大的匹配查询能力实现基于内容的推荐服务。
缓存数据库:项目采用Redis作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求。
【离线推荐部分】
离线统计服务:批处理统计性业务采用Spark Core + Spark SQL进行实现,实现对指标类数据的统计任务。
离线推荐服务:离线推荐业务采用Spark Core + Spark MLlib进行实现,采用ALS算法进行实现。
工作调度服务:对于离线推荐部分需要以一定的时间频率对算法进行调度,采用Azkaban进行任务的调度。
【实时推荐部分】
日志采集服务:通过利用Flume-ng对业务平台中用户对于电影的一次评分行为进行采集,实时发送到Kafka集群。
消息缓冲服务:项目采用Kafka作为流式数据的缓存组件,接受来自Flume的数据采集请求。并将数据推送到项目的实时推荐系统部分。
实时推荐服务:项目采用Spark Streaming作为实时推荐系统,通过接收Kafka中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到MongoDB数据库。
项目数据流程
【系统初始化部分】
- 通过Spark SQL将系统初始化数据加载到MongoDB和ElasticSearch中。
【离线推荐部分】
- 通过Azkaban实现对于离线统计服务以离线推荐服务的调度,通过设定的运行时间完成对任务的触发执行。
- 离线统计服务从MongoDB中加载数据,将【电影平均评分统计】、【电影评分个数统计】、【最近电影评分个数统计】三个统计算法进行运行实现,并将计算结果回写到MongoDB中;离线推荐服务从MongoDB中加载数据,通过ALS算法分别将【用户推荐结果矩阵】、【影片相似度矩阵】回写到MongoDB中。
【实时推荐部分】
- Flume从综合业务服务的运行日志中读取日志更新,并将更新的日志实时推送到Kafka中;Kafka在收到这些日志之后,通过kafkaStream程序对获取的日志信息进行过滤处理,获取用户评分数据流【UID|MID|SCORE|TIMESTAMP】,并发送到另外一个Kafka队列;Spark Streaming监听Kafka队列,实时获取Kafka过滤出来的用户评分数据流,融合存储在Redis中的用户最近评分队列数据,提交给实时推荐算法,完成对用户新的推荐结果计算;计算完成之后,将新的推荐结构和MongDB数据库中的推荐结果进行合并。
【业务系统部分】
- 推荐结果展示部分,从MongoDB、ElasticSearch中将离线推荐结果、实时推荐结果、内容推荐结果进行混合,综合给出相对应的数据。
- 电影信息查询服务通过对接MongoDB实现对电影信息的查询操作。
- 电影评分部分,获取用户通过UI给出的评分动作,后台服务进行数据库记录后,一方面将数据推动到Redis群中,另一方面,通过预设的日志框架输出到Tomcat中的日志中。
- 项目通过ElasticSearch实现对电影的模糊检索。
- 电影标签部分,项目提供用户对电影打标签服务。
加载数据
Movies数据集 电影数据表
数据格式:
mid,name,descri,timelong,issue,shoot,language,genres,actors,directors

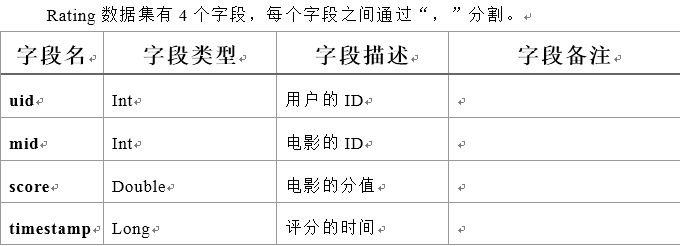
Ratings数据集 用户评分表
数据格式:
userId,movieId,rating,timestamp
Tag数据集 电影标签表
数据格式:
userId,movieId,tag,timestamp

日志管理配置文件
log4j对日志的管理,需要通过配置文件来生效。在src/main/resources下新建配置文件log4j.properties,写入以下内容:
log4j.rootLogger=info, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
数据初始化到MongoDB、ElasticSearch
数据加载程序主体:
为原始数据定义几个样例类,通过SparkContext的textFile方法从文件中读取数据,并转换成DataFrame,再利用Spark SQL提供的write方法进行数据的分布式插入。
在DataLoader/src/main/scala下新建package;
将数据写入MongoDB 写入ElasticSearch
接下来,实现storeDataInMongo方法,将数据写入mongodb中:
同样主要通过Spark SQL提供的write方法进行数据的分布式插入,实现storeDataInES方法:
\MovieRecommendSystem\recommender\DataLoader\src\main\scala\com\xxx\DataLoader\DataLoader.scala