Linux 深入理解inode/block/superblock
档案系统特性
传统的磁盘与档案系统之应用中,一个分割槽就是只能够被格式化成为一个档案系统,所以我们可以说一个filesystem就是一个partition。但是由于新技术的利用,例如我们常听到的LVM与软体磁盘阵列(software raid),这些技术可以将一个分割槽格式化为多个档案系统(例如LVM),也能够将多个分割槽合成一个档案系统(LVM, RAID)!所以说,目前我们在格式化时已经不再说成针对partition来格式化了,通常我们可以称呼一个可被挂载的资料为一个档案系统而不是一个分割槽喔!
那么档案系统是如何运作的呢?这与作业系统的档案资料有关。较新的作业系统的档案资料除了档案实际内容外,通常含有非常多的属性,例如Linux作业系统的档案权限(rwx)与档案属性(拥有者、群组、时间参数等)。 档案系统通常会将这两部份的资料分别存放在不同的区块,权限与属性放置到inode中,至于实际资料则放置到data block区块中。另外,还有一个超级区块(superblock)会记录整个档案系统的整体信息,包括inode与block的总量、使用量、剩余量等。
每个inode 与block 都有编号,至于这三个资料的意义可以简略说明如下:
- superblock:记录此filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及档案系统的格式与相关信息等;
- inode:记录档案的属性,一个档案占用一个inode,同时记录此档案的资料所在的block 号码;
- block:实际记录档案的内容,若档案太大时,会占用多个block 。
由于每个inode 与block 都有编号,而每个档案都会占用一个inode ,inode 内则有档案资料放置的block 号码。因此,我们可以知道的是,如果能够找到档案的inode 的话,那么自然就会知道这个档案所放置资料的block 号码, 当然也就能够读出该档案的实际资料了。这是个比较有效率的作法,因为如此一来我们的磁盘就能够在短时间内读取出全部的资料, 读写的效能比较好啰。
我们将inode 与block 区块用图解来说明一下,如下图所示,档案系统先格式化出inode 与block 的区块,假设某一个档案的属性与权限资料是放置到inode 4 号(下图较小方格内),而这个inode 记录了档案资料的实际放置点为2, 7, 13, 15 这四个block 号码,此时我们的作业系统就能够据此来排列磁盘的读取顺序,可以一口气将四个block 内容读出来!那么资料的读取就如同下图中的箭头所指定的模样了。 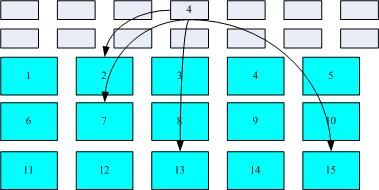
这种资料存取的方法我们称为索引式档案系统(indexed allocation)。那有没有其他的惯用档案系统可以比较一下啊?有的,那就是我们惯用的U盘(快闪记忆体),U盘使用的档案系统一般为FAT格式。FAT这种格式的档案系统并没有inode存在,所以FAT没有办法将这个档案的所有block在一开始就读取出来。每个block号码都记录在前一个block当中,他的读取方式有点像底下这样:
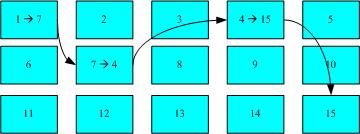
上图中我们假设档案的资料依序写入1->7->4->15号这四个block 号码中, 但这个档案系统没有办法一口气就知道四个block 的号码,他得要一个一个的将block 读出后,才会知道下一个block 在何处。如果同一个档案资料写入的block 分散的太过厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的资料, 因此磁盘就会多转好几圈才能完整的读取到这个档案的内容!
常常会听到所谓的『碎片整理』吧? 需要碎片整理的原因就是档案写入的block太过于离散了,此时档案读取的效能将会变的很差所致。 这个时候可以透过碎片整理将同一个档案所属的blocks汇整在一起,这样资料的读取会比较容易啊! 想当然尔,FAT的档案系统需要三不五时的碎片整理一下,那么Ext2是否需要磁盘重整呢?
由于Ext2 是索引式档案系统,基本上不太需要常常进行碎片整理的。但是如果档案系统使用太久, 常常删除/编辑/新增档案时,那么还是可能会造成档案资料太过于离散的问题,此时或许会需要进行重整一下的。
Linux 的EXT2 档案系统(inode)
inode的内容在记录档案的权限与相关属性,至于block区块则是在记录档案的实际内容。而且档案系统一开始就将inode与block规划好了,除非重新格式化(或者利用resize2fs等指令变更档案系统大小),否则inode与block固定后就不再变动。但是如果仔细考虑一下,如果我的档案系统高达数百GB时,那么将所有的inode与block通通放置在一起将是很不智的决定,因为inode与block的数量太庞大,不容易管理。
为此,因此Ext2 档案系统在格式化的时候基本上是区分为多个区块群组(block group) 的,每个区块群组都有独立的 inode/block/superblock 系统。感觉上就好像我们在当兵时,一个营里面有分成数个连,每个连有自己的联络系统, 但最终都向营部回报连上最正确的信息一般!这样分成一群群的比较好管理啦!整个来说,Ext2 格式化后有点像底下这样:
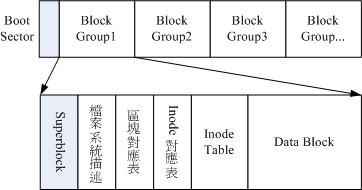
在整体的规划当中,档案系统最前面有一个开机磁区(boot sector),这个开机磁区可以安装开机管理程式,这是个非常重要的设计,因为如此一来我们就能够将不同的开机管理程式安装到个别的档案系统最前端,而不用覆盖整颗磁盘唯一的MBR,这样也才能够制作出多重开机的环境啊!至于每一个区块群组(block group)的六个主要内容说明如后:
data block (资料区块)
data block是用来放置档案内容资料地方,在Ext2档案系统中所支持的block大小有1K, 2K及4K三种而已。在格式化时block的大小就固定了,且每个block都有编号,以方便inode的记录啦。不过要注意的是,由于block大小的差异,会导致该档案系统能够支持的最大磁盘容量与最大单一档案容量并不相同。因为block大小而产生的Ext2档案系统限制如下:
| Block 大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一档案限制 | 16GB | 256GB | 2TB |
| 最大档案系统总容量 | 2TB | 8TB | 16TB |
除此之外Ext2 档案系统的block 还有什么限制呢?有的!基本限制如下:
- 原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
- 每个block 内最多只能够放置一个档案的资料;
- 承上,如果档案大于block 的大小,则一个档案会占用多个block 数量;
- 承上,若档案小于block ,则该block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
inode table (inode 表格)
基本上,inode记录的档案资料至少有底下这些:
- 该档案的存取模式(read/write/excute);
- 该档案的拥有者与群组(owner/group);
- 该档案的容量;
- 该档案建立或状态改变的时间(ctime);
- 最近一次的读取时间(atime);
- 最近修改的时间(mtime);
- 定义档案特性的旗标(flag),如SetUID…;
- 该档案真正内容的指向(pointer);
inode 的数量与大小也是在格式化时就已经固定了,除此之外inode 还有些什么特色呢?
- 每个inode 大小均固定为128 bytes (新的ext4 与xfs 可设定到256 bytes);
- 每个档案都仅会占用一个inode 而已;
- 承上,因此档案系统能够建立的档案数量与inode 的数量有关;
- 系统读取档案时需要先找到inode,并分析inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容。
我们粗略来分析一下EXT2 的inode / block 与档案大小的关系好了。inode 要记录的资料非常多,但偏偏又只有128bytes 而已, 而inode 记录一个block 号码要花掉4byte ,假设我一个档案有400MB 且每个block 为4K 时, 那么至少也要十万笔block 号码的记录呢!inode 哪有这么多可记录的信息?为此我们的系统很聪明的将inode 记录block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。这是啥?我们将inode 的结构画一下好了。 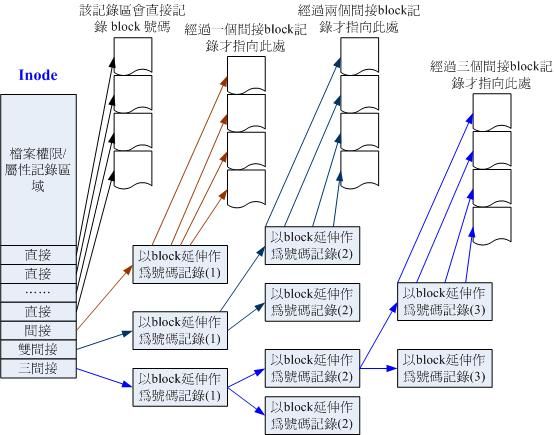
这样子inode 能够指定多少个block 呢?我们以较小的1K block 来说明好了,可以指定的情况如下:
- 12个直接指向: 12*1K=12K
由于是直接指向,所以总共可记录12笔记录,因此总额大小为如上所示; - 间接: 256*1K=256K
每笔block号码的记录会花去4bytes,因此1K的大小能够记录256笔记录,因此一个间接可以记录的档案大小如上; - 双间接: 256*256*1K=256 2 K
第一层block会指定256个第二层,每个第二层可以指定256个号码,因此总额大小如上; - 三间接: 256*256*256*1K=256 3 K
第一层block会指定256个第二层,每个第二层可以指定256个第三层,每个第三层可以指定256个号码,因此总额大小如上; - 总额:将直接、间接、双间接、三间接加总,得到12 + 256 + 256*256 + 256*256*256 (K) = 16GB
Superblock (超级区块)
记录的信息主要有:
- block 与inode 的总量;
- 未使用与已使用的inode / block 数量;
- block 与inode 的大小(block 为1, 2, 4K,inode 为128bytes 或256bytes);
- filesystem 的挂载时间、最近一次写入资料的时间、最近一次检验磁盘(fsck) 的时间等档案系统的相关信息;
- 一个valid bit 数值,若此档案系统已被挂载,则valid bit 为0 ,若未被挂载,则valid bit 为1 。
一般来说, superblock的大小为1024bytes。相关的superblock讯息我们等一下会以dumpe2fs指令来呼叫出来观察喔!
此外,每个block group 都可能含有superblock 喔!但是我们也说一个档案系统应该仅有一个superblock 而已,那是怎么回事啊?事实上除了第一个block group 内会含有superblock 之外,后续的block group 不一定含有superblock , 而若含有superblock 则该superblock 主要是做为第一个block group 内superblock 的备份咯,这样可以进行superblock的救援呢!
Filesystem Description (档案系统描述说明)
这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock, bitmap, inodemap, data block)分别介于哪一个block号码之间。这部份也能够用dumpe2fs来观察的。
block bitmap (区块对照表)
如果你想要新增档案时总会用到block 吧!那你要使用哪个block 来记录呢?当然是选择『空的block 』来记录新档案的资料啰。那你怎么知道哪个block 是空的?这就得要透过block bitmap 的辅助了。从block bitmap 当中可以知道哪些block 是空的,因此我们的系统就能够很快速的找到可使用的空间来处置档案啰。
同样的,如果你删除某些档案时,那么那些档案原本占用的block 号码就得要释放出来, 此时在block bitmap 当中相对应到该block 号码的标志就得要修改成为『未使用中』啰!这就是bitmap 的功能。
inode bitmap (inode 对照表)
这个其实与block bitmap 是类似的功能,只是block bitmap 记录的是使用与未使用的block 号码, 至于inode bitmap 则是记录使用与未使用的inode 号码啰!
dumpe2fs: 查询Ext 家族superblock 信息的指令
[root@study ~]# dumpe2fs [-bh]装置档名
选项与参数:
-b :列出保留为坏轨的部分(一般用不到吧!?)
-h :仅列出superblock 的资料,不会列出其他的区段内容!
范例:鸟哥的一块1GB ext4档案系统内容
[root@study ~]# blkid <==这个指令可以叫出目前系统有被格式化的装置
/dev/vda1: LABEL="myboot" UUID="ce4dbf1b-2b3d-4973-8234-73768e8fd659" TYPE="xfs" /dev/vda2: LABEL="myroot" UUID="21ad8b9a-aaad-443c-b732-4e2522e95e23" TYPE="xfs" /dev/vda3: UUID="12y99K-bv2A-y7RY-jhEW-rIWf-PcH5-SaiApN" TYPE="LVM2_member" /dev/vda5: UUID="e20d65d9-20d4-472f-9f91-cdcfb30219d6" TYPE="ext4" <==看到ext4了! [root@study ~]# dumpe2fs /dev/vda5 dumpe2fs 1.42.9 (28-Dec-2013) Filesystem volume name: #档案系统的名称(不一定会有) Last mounted on: <not available> #上一次挂载的目录位置 Filesystem UUID: e20d65d9-20d4-472f-9f91-cdcfb30219d6 Filesystem magic number: 0xEF53 #上方的UUID为Linux对装置的定义码 Filesystem revision #: 1 (dynamic) #下方的features为档案系统的特征资料 Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize Filesystem flags: signed_directory_hash Default mount options: user_xattr acl #预设在挂载时会主动加上的挂载参数 Filesystem state: clean #这块档案系统的状态为何,clean是没问题 Errors behavior: Continue Filesystem OS type: Linux Inode count: 65536 # inode的总数 Block count: 262144 # block的总数 Reserved block count: 13107 #保留的block总数 Free blocks: 249189 #还有多少的block可用数量 Free inodes: 65525 #还有多少的inode可用数量 First block: 0 Block size: 4096 #单个block的容量大小 Fragment size: 4096 Group descriptor size: 64 ....(中间省略).... Inode size: 256 # inode的容量大小!已经是256了喔! ....(中间省略).... Journal inode: 8 Default directory hash: half_md4 Directory Hash Seed: 3c2568b4-1a7e-44cf-95a2-c8867fb19fbc Journal backup: inode blocks Journal features: (none) Journal size: 32M # Journal日志式资料的可供纪录总容量 Journal length: 8192 Journal sequence: 0x00000001 Journal start: 0 Group 0: (Blocks 0-32767) #第一块block group位置 Checksum 0x13be, unused inodes 8181 Primary superblock at 0, Group descriptors at 1-1 #主要superblock的所在喔! Reserved GDT blocks at 2-128 Block bitmap at 129 (+129), Inode bitmap at 145 (+145) Inode table at 161-672 (+161) # inode table的所在喔! 28521 free blocks, 8181 free inodes, 2 directories, 8181 unused inodes Free blocks: 142-144, 153-160, 4258-32767 #底下两行说明剩余的容量有多少 Free inodes: 12-8192 Group 1: (Blocks 32768-65535) [INODE_UNINIT] #后续为更多其他的block group喔! ....(底下省略).... #由于资料量非常的庞大,因此鸟哥将一些信息省略输出了!上表与你的萤幕会有点差异。 # 前半部在秀出supberblock 的内容,包括标头名称(Label)以及inode/block的相关信息 # 后面则是每个block group 的个别信息了!您可以看到各区段资料所在的号码! # 也就是说,基本上所有的资料还是与block 的号码有关就是了!很重要! 至于block group 的内容我们单纯看Group0 信息好了。从上表中我们可以发现:
- Group0 所占用的block 号码由0 到32767 号,superblock 则在第0 号的block 区块内!
- 档案系统描述说明在第1 号block 中;
- block bitmap 与inode bitmap 则在129 及145 的block 号码上。
- 至于inode table 分布于161-672 的block 号码中!
- 由于(1)一个inode 占用256 bytes ,(2)总共有672 - 161 + 1(161本身) = 512 个block 花在inode table 上, (3)每个block 的大小为4096 bytes(4K)。由这些数据可以算出inode 的数量共有512 * 4096 / 256 = 8192 个inode 啦!
- 这个Group0 目前可用的block 有28521 个,可用的inode 有8181 个;
- 剩余的inode 号码为12 号到8192 号。
与目录树的关系
由前一小节的介绍我们知道在Linux系统下,每个档案(不管是一般档案还是目录档案)都会占用一个inode ,且可依据档案内容的大小来分配多个block给该档案使用。那么目录与档案在档案系统当中是如何记录资料的呢?基本上可以这样说:
目录
当我们在Linux下的档案系统建立一个目录时,档案系统会分配一个inode与至少一块block给该目录。其中,inode记录该目录的相关权限与属性,并可记录分配到的那块block号码;而block则是记录在这个目录下的档名与该档名占用的inode号码资料。
如果想要实际观察root 家目录内的档案所占用的inode 号码时,可以使用ls -i 这个选项来处理:
[root@study ~]# ls -li total 8 53735697 -rw-------. 1 root root 1816 May 4 17:57 anaconda-ks.cfg 53745858 -rw-r--r--. 1 root root 1864 May 4 18:01 initial-setup-ks .cfg而由这个目录的block 结果我们现在就能够知道, 当你使用『 ll / 』时,出现的目录几乎都是1024 的倍数,为什么呢?因为每个block 的数量都是1K, 2K, 4K 嘛!
[root@study ~]# ll -d / /boot /usr/sbin /proc /sys
dr-xr-xr-x. 17 root root 4096 May 4 17:56 / <== 1个4K block dr-xr- xr-x. 4 root root 4096 May 4 17:59 /boot <== 1个4K block dr-xr-xr-x. 155 root root 0 Jun 15 15:43 /proc <==这两个为记忆体内资料,不占磁盘容量 dr-xr-xr-x. 13 root root 0 Jun 15 23:43 /sys dr-xr-xr-x. 2 root root 16384 May 4 17:55 /usr/sbin <== 4个4K block
档案:
当我们在Linux 下的ext2 建立一个一般档案时, ext2 会分配一个inode 与相对于该档案大小的block 数量给该档案。例如:假设我的一个block 为4 Kbytes ,而我要建立一个100 KBytes 的档案,那么linux 将分配一个inode 与25 个block 来储存该档案!但同时请注意,由于inode 仅有12 个直接指向,因此还要多一个block 来作为区块号码的记录喔!
目录树读取:
我们提到『新增/删除/更名档名与目录的w权限有关』!那是因为档名是记录在目录的block当中,因此当我们要读取某个档案时,就务必会经过目录的inode与block ,然后才能够找到那个待读取档案的inode号码,最终才会读到正确的档案的block内的资料。
由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的inode 号码,此时就能够得到根目录的inode 内容,并依据该inode 读取根目录的block 内的档名资料,再一层一层的往下读到正确的档名。举例来说,如果我想要读取/etc/passwd 这个档案时,系统是如何读取的呢?
[root@study ~]# ll -di / /etc /etc/passwd 128 dr-xr-x r-x . 17 root root 4096 May 4 17:56 / 33595521 drwxr-x r-x . 131 root root 8192 Jun 17 00:20 /etc 36628004 -rw-r-- r-- . 1 root root 2092 Jun 17 00:20 /etc/passw该档案的读取流程为(假设读取者身份为dmtsai 这个一般身份使用者):
- /的inode:
透过挂载点的信息找到inode号码为128的根目录inode,且inode的权限属性允许我们可以读取该block的内容(有r与x) ; - /的block:
经过上个步骤取得block的号码,并找到该内容有etc/目录的inode号码(33595521); - etc/的inode:
读取33595521号inode得知dmtsai具有r与x的权限,因此可以读取etc/的block内容; - etc/的block:
经过上个步骤取得block号码,并找到该内容有passwd档案的inode号码(36628004); - passwd的inode:
读取36628004号inode得知dmtsai具有r的权限,因此可以读取passwd的block内容; - passwd的block:
最后将该block内容的资料读出来。