
人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(1):开篇
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(5):前置准备(四)数据库基础
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(7):HTTP 基础
小白学 Python 爬虫(8):网页基础
小白学 Python 爬虫(9):爬虫基础
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(19):Xpath 基操
小白学 Python 爬虫(20):Xpath 进阶
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
小白学 Python 爬虫(24):2019 豆瓣电影排行
小白学 Python 爬虫(25):爬取股票信息
小白学 Python 爬虫(26):为啥买不起上海二手房你都买不起
小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
小白学 Python 爬虫(30):代理基础
小白学 Python 爬虫(31):自己构建一个简单的代理池
小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
小白学 Python 爬虫(39): JavaScript 渲染服务 Scrapy-Splash 入门
小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
引言
前面我们介绍了使用 Scrapy 对接 Selenium 来抓取由 JavaScript 动态渲染的网页,那么除了这种方式,是否还有其他的解决方案?
答案当然是肯定的,前面我们同样介绍了 Splash 这个 JavaScript 动态渲染服务,本篇文章,我们就来介绍如何使用 Scrapy 对接 Splash 抓取由 JavaScript 动态渲染的网页。
示例
准备
首先需确保已经正确安装 Splash 服务,同时包括 Scrapy-Splash 库,还没有安装的同学,可以参考前面的文章 「小白学 Python 爬虫(39): JavaScript 渲染服务 Scrapy-Splash 入门」 进行安装。
新建项目
本篇内容还是新建一个新的 Scrapy 项目,并且命名为 scrapy_splash_demo ,命令如下:
scrapy startproject scrapy_splash_demo记得找一个自己喜欢的目录,最好是纯英文目录。
然后新建一个 Spider ,命令如下:
scrapy genspider jd www.jd.com本篇的示例嘛还是使用之前 Splash 的示例,毕竟本文的内容主要是介绍 Scrapy 如何对接 Splash ,当然另一个更主要的原因是小编也比较懒嘛~~~
配置
这里的配置可以参考官方的 Github 仓库,链接:https://github.com/scrapy-plugins/scrapy-splash 。
首先先在 settings.py 中添加 Splash 服务的地址,因为小编这里使用的是本地的服务,所以直接就配置了本地的链接。
SPLASH_URL = 'http://localhost:8050/'如果 Splash 服务是在远端的服务器上运行的,那么这里就应该配置远端服务器的地址,如 Splash 服务是运行在远端的 172.16.15.177 上的,那么需要的配置就是:
SPLASH_URL = 'http://172.16.15.177:8050/'接下里需要配置几个 DOWNLOADER_MIDDLEWARES ,如下:
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}我们还需要配置一个 SPIDER_MIDDLEWARES ,如下:
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}接下来,需要配置一个去重的 Python 类 SplashAwareDupeFilter ,如下:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'我们还需要配置一个 Cache 存储的 SplashAwareFSCacheStorage ,如下:
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'接下来,我们就可以开始搞事情了。
发送请求
上面我们已经将该配置的都配置完成了,这里我们可以直接使用 SplashRequest 对象并传递相应的参数, Scrapy 会将此请求转发给 Splash ,Splash 将页面加载渲染,渲染完成后再将结果传递回来,这时的 Response 就是经过 Splash 渲染的结果了,这里直接交给 Spider 解析就好了。
我们先来看下官方的示例,如下:
yield SplashRequest(url, self.parse_result,
args={
# optional; parameters passed to Splash HTTP API
'wait': 0.5,
# 'url' is prefilled from request url
# 'http_method' is set to 'POST' for POST requests
# 'body' is set to request body for POST requests
},
endpoint='render.json', # optional; default is render.html
splash_url='', # optional; overrides SPLASH_URL
slot_policy=scrapy_splash.SlotPolicy.PER_DOMAIN, # optional
) 这里直接构造了一个 SplashRequest 对象,前两个参数是目标 URL 以及回调的方法,另外我们可以通过 args 传递一些参数,如等待的时间,这个示例中是 0.5 。
更多的说明还是参考官方 Github 仓库,地址:https://github.com/scrapy-plugins/scrapy-splash 。
或者我们也可以使用 scrapy.Request , Splash 相关的配置通过 meta 配置就好了,接着看一个官方的示例,如下:
yield scrapy.Request(url, self.parse_result, meta={
'splash': {
'args': {
# set rendering arguments here
'html': 1,
'png': 1,
# 'url' is prefilled from request url
# 'http_method' is set to 'POST' for POST requests
# 'body' is set to request body for POST requests
},
# optional parameters
'endpoint': 'render.json', # optional; default is render.json
'splash_url': '', # optional; overrides SPLASH_URL
'slot_policy': scrapy_splash.SlotPolicy.PER_DOMAIN,
'splash_headers': {}, # optional; a dict with headers sent to Splash
'dont_process_response': True, # optional, default is False
'dont_send_headers': True, # optional, default is False
'magic_response': False, # optional, default is True
}
}) 这两种发送 Request 请求的方式是相同的,选哪个都可以。
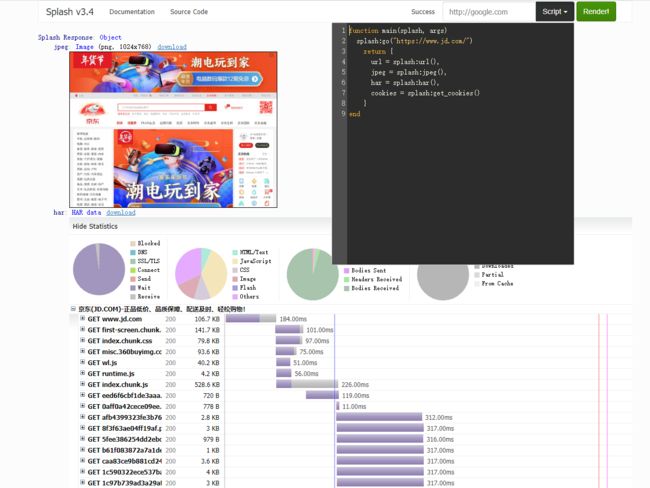
本篇文章中使用的 Lua 脚本还是之前文章中的脚本,具体 Lua 脚本内容如下:
function main(splash, args)
splash:go("https://www.jd.com/")
return {
url = splash:url(),
jpeg = splash:jpeg(),
har = splash:har(),
cookies = splash:get_cookies()
}
end结果如下:
接下来,我们在 Spider 中使用 SplashRequest 对接 Lua 脚本就好了,事情就是这么简单,如下:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
lua_script = """
function main(splash, args)
splash:go(args.url)
return {
url = splash:url(),
jpeg = splash:jpeg(),
har = splash:har(),
cookies = splash:get_cookies()
}
end
"""
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['www.jd.com']
start_urls = ['http://www.jd.com/']
def start_requests(self):
url = 'https://www.jd.com/'
yield SplashRequest(url=url, callback=self.parse)
def parse(self, response):
self.logger.debug(response.text)Spider 写好了以后可以使用命令运行这个爬虫了,命令如下:
scrapy crawl jd具体的结果小编这里就不贴了,只是简单的将响应回来的数据已日志的形式打印出来了,不过如果仔细观察打出来的数据,可以看到原来由 JavaScript 动态渲染的部分也打印出来了,说明我们的 Scrapy 对接 Splash 实战成功。
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
示例代码-Github
示例代码-Gitee