【火炉炼AI】机器学习025-自动估算集群数量-DBSCAN算法
(本文所使用的Python库和版本号: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2 )
在前面的文章【火炉炼AI】机器学习024-无监督学习模型的性能评估--轮廓系数中,我们自己定义了一个通用型函数,用于为 K-means算法寻找最佳的K值,这个函数虽然有效,但是却不高效,这是一个非常耗时的过程。而DBSCAN算法却是一个快速的,高效的自动评估集群数量的算法。
1. DBSCAN算法简介
DBSCAN,即Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法,是一种很经典的密度聚类算法,前面我们讲到的K-means算法只适用于凸样本集,而此处的DBSCAN算法不仅适用于凸样本集,也适用于非凸样本集,看来其应用范围要比K-means方法大得多。
DBSCAN是一种基于密度的聚类算法,其假定类别可以通过样本分布的紧密程度决定,同一个类别的样本,他们之间是紧密相连的,即,在该类别任意样本周围不远处一定有同类别的样本存在。
DBSCAN是基于一组邻域来描述样本集的紧密程度的,参数(ϵ, MinPts)用来描述邻域的样本分布紧密程度。其中,ϵ描述了某一样本的邻域距离阈值,MinPts描述了某一样本的距离为ϵ的邻域中样本个数的阈值。
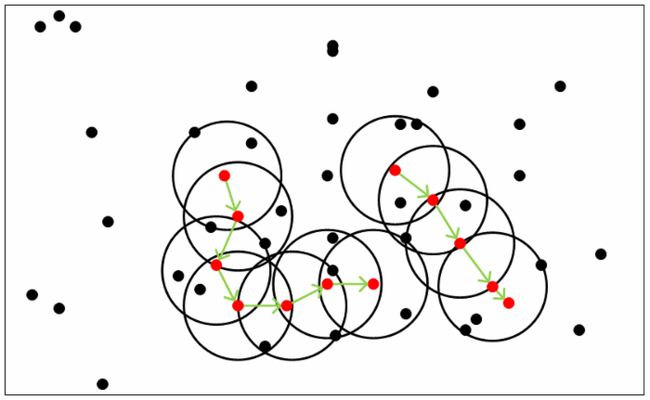
上面是聚类思想的说明图,图中的MinPts=5,即参数ϵ=5,红色的点都是核心对象,因为这些点的ϵ邻域至少有5个样本,而黑色的点就是非核心对象。所有这些红色的核心对象密度直达的样本在以红色核心对象为中心的超球体内,如果不在该超球体内,则不能密度直达。图中绿色箭头连起来的核心对象组成了密度可达的样本序列,在这些密度可达的样本序列的ϵ-邻域内所有的样本相互都是密度相连的。有密度可达关系导出的最大密度相连的样本集合,即为我们最终聚类的一个类别,或者说一个簇。
那么怎么才能找到这样的簇样本集合呢?DBSCAN使用的方法很简单,它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇。一直运行到所有核心对象都有类别为止。
DBSCAN算法的优点在于:
1, 相对于K-means算法,其不需要输入类别数K。
2,当然其最大的优势是可以发现任意形状的聚类簇,而不是像K-means,一般仅仅适用于凸样本集。而DBSCAN不仅适用于凸样本集,还适用于非凸样本集。所以这一算法可以对任意形状的稠密数据集进行聚类。
3,可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
4,聚类结果没有偏倚,而相对的,K-means算法对初始值很敏感。
当然,DBSCAN算法也有一些缺点,主要在于:
1,如果样本集的密度不均匀,聚类间距差相差很大,聚类质量较差,这时用DBSCAN算法并不合适。
2,如果样本集较大,聚类收敛的时间会较长,此时可以对搜索最近邻时建立的KD数或者球树进行规模限制来改进。
3,调参相对于K-means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,领域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
以上部分内容来源于DBSCAN密度聚类算法,在此表示感谢。
2. 构建简单的DBSCAN模型
和其他聚类算法一样,构建DBSCAN模型非常简单,sklearn中已经集成了这种算法,我们直接调用即可。由于这是初步尝试构建该模型,故而我们随便指定构建参数,以后可以继续优化这些参数。
# 定义一个DBCSCAN模型,并用数据集训练它
from sklearn.cluster import DBSCAN
model=DBSCAN(eps=0.5,min_samples=5) # 此处的参数是随便指定
model.fit(dataset)
# 使用轮廓系数评估模型的优虐
from sklearn.metrics import silhouette_score
si_score=silhouette_score(dataset,model.labels_)
print('si_score: {:.4f}'.format(si_score))
-------------------------------------输---------出--------------------------------
si_score: 0.5134
--------------------------------------------完-------------------------------------
########################小**********结###############################
1,构建DBSCAN模型非常简单,sklearn已经封装好了这种算法,我们只需直接调用即可。
2,在构建DBSCAN模型时,需要指定eps参数和min_samples参数,这些参数需要后期优化,此处我们只是随便指定。
#################################################################
3. DBSCAN模型参数的优化
前面在构建模型时,我们是随机的指定eps参数,但是这样肯定不利于模型的最佳性能的发挥,我们需要对eps参数进行优化,获取最优eps值。以下是代码:
# 在定义DBSCAN时,往往我们很难知道最优的eps参数,
# 故而可以通过遍历得到最优值
def get_optimal_eps(dataset,eps_list):
'''get optimal eps param for DBSCAN
params:
dataset: the whole dataset.
eps_list: must be in np.linspace() format or list format.
return:
three values:optimal eps value,
optimal model with optimal eps
silhouette_scores of all candidate eps.
'''
scores=[]
models=[]
for eps in eps_list:
model=DBSCAN(eps=eps,min_samples=5).fit(dataset)
labels=model.labels_
label_num=len(np.unique(labels))
if label_num>1: # 需要判断label种类,因为如果只有一个label,silhouette_score报错
scores.append(silhouette_score(dataset,model.labels_))
models.append(model)
else:
scores.append(0)
models.append(None)
optimal_id=scores.index(max(scores))
return eps_list[optimal_id],models[optimal_id],scores
optimal_eps, optimal_model,scores=get_optimal_eps(dataset,np.linspace(0.3, 1.7, num=15))
print('optimal eps: {:.4f}, \ncandidate eps: {}, \nscores: {}'.format(optimal_eps,np.linspace(0.3,1.7,15),scores))
-------------------------------------输---------出--------------------------------
[0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7]
optimal eps: 0.8000,
candidate eps: [0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7],
scores: [0.12865164017329436, 0.3593618148137507, 0.5134143263329637, 0.616532168834258, 0.6321600450689241, 0.6366395861050828, 0.5141678956134529, 0.5629298661962946, 0.5629298661962946, 0.5629298661962946, 0, 0, 0, 0, 0]
--------------------------------------------完-------------------------------------
由于DBSCAN模型有核心样本和异常样本这一说法,故而我们要使用该模型将核心样本和异常样本找出来。如下是代码:
# 上述函数得到了最佳eps参数和该最佳参数下的最佳模型,我们可以从该最佳模型中得到一些属性
labels=optimal_model.labels_
label_num=len(np.unique(labels))
# 但是有标记为-1的样本
# 这些样本是没有分配集群的样本,被认为是异常点。
if -1 in labels:
label_num-=1 # 需要减一个类别,减去异常点
print('clusters num: ',label_num) # 最佳模型划分的簇群数量,
# print(labels)
# DBSCAN模型中可以得到核心样本的数据点坐标
# 首先获取核心样本的坐标索引
core_index=optimal_model.core_sample_indices_
# print(core_index)
mask_core=np.zeros(labels.shape,dtype=np.bool)
mask_core[model.core_sample_indices_]=True
# print(mask_core)
这一段代码首先根据labels的种类判断DBSCAN把该数据集划分为几个簇群,由于有异常样本的存在,故而需要减去一个类别。然后用该模型得到核心样本的坐标索引,打印出来后就可以看到这些样本的具体坐标。
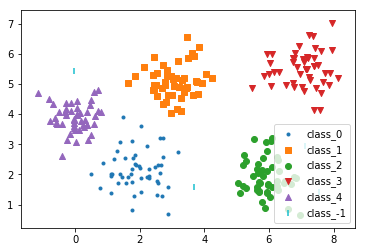
上图中可以看到最后一个类别是class_-1,即为异常样本所在的位置,图中是用小竖线的标记表示。这些异常样本不属于其他任何一个簇群,所以由此可以看到DBSCAN可以自动避免异常的离群样本点的干扰,这也是该算法的一个重要优势所在。
########################小**********结###############################
1,此处我自己定义了一个优化eps参数的函数,这是一个比较通用型的调参函数,可以用于其它任何数据集的参数选择。
2,DBSCAN模型和K-means模型的不同之处在于,得到的模型中含有核心样本点,非核心样本,异常样本这几类数据点,其中异常点不属于任何一种簇群,故而这种算法可以避免异常点的干扰,这是其优势之一。
#################################################################
注:本部分代码已经全部上传到(我的github)上,欢迎下载。
参考资料:
1, Python机器学习经典实例,Prateek Joshi著,陶俊杰,陈小莉译