![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第1张图片](http://img.e-com-net.com/image/info10/e3a5775ea3c64295ac82d605507c4314.jpg)
本文介绍的论文是:《Modeling and Simultaneously Removing Bias via Adversarial Neural Networks》
前面已经有几篇关于消除CTR预估中位置偏置信息的介绍,如华为的PAL、youtube的shallow tower、以及将位置信息作为输入特征的方法。但对于样本中可能存在的偏置信息,上述的方法都没有解决,而本文提出的对抗学习框架,不仅解决了一般的位置偏置,还能够消除样本特征中的偏置信息,一起来学习一下吧。
1、背景
对于搜索广告的排序,往往是基于对于广告点击率的预估以及广告主的出价(bid)来决定的。但是用于训练点击率预估模型的样本中,往往存在一定的偏置信息。
在训练点击率预估模型时,许多特征属于统计特征,比如搜索关键词和广告的交叉点击率。对于经常展示的关键词/广告对来说,这类特征比较丰富且置信,但是对于不经常展示或者从未展示过的关键词/广告对来说,这类信息非常稀疏且不置信,模型对这些关键词/广告的信息不能充分学习,很难将这些关键词/广告对的展示位置进行提前。
同时,当CTR模型进行更新时,所使用的数据往往是在线上应用前一版模型而收集到的。新的数据和模型更容易学到这些展示位置靠前的关键词/广告对的信息,这种情形文中称为“Feedback Loop”,此时我们的训练所使用的数据,是存在一定偏置信息的。
这种偏置信息的存在,大都集中于位置偏置,即不同的展示位置对于CTR的影响不同,越靠前位置展示的广告,点击率会偏高。因此有必要在模型训练的过程中消除这些信息。
关于位置偏置信息的消除,前面几篇论文中已经提到过几种方法了,简单回顾一下:
位置信息作为特征
![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第2张图片](http://img.e-com-net.com/image/info10/86b51dbb6e4a4c378717897e85c38642.jpg)
华为PAL框架
![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第3张图片](http://img.e-com-net.com/image/info10/5bf3df0cf0b94db4b0d1750fcc0f5a60.jpg)
Youtube Shallow-Tower
![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第4张图片](http://img.e-com-net.com/image/info10/960f7f045bb54639901ca6fd33e7e299.jpg)
但上面几种方法虽然在一定程度上解决了位置偏置信息,但是样本中的偏置信息没有解决,举个简单的例子,比如某用户和某个品类的点击率交叉特征,这个特征本身也是存在偏置的,有可能某种品类的展示位置靠前导致了用户对于这种品类的商家点击率特别高。
本文提出的对抗学习框架,不仅解决了一般的位置偏置信息,还能够消除样本特征中的偏置信息,一起来学习一下吧。
2、对抗学习框架
2.1 框架介绍
对抗学习(Adversarial Neural Network)的框架如下图所示:
![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第5张图片](http://img.e-com-net.com/image/info10/613fa1ec59c04aed900908962a91b555.jpg)
模型一共包含四个部分,BaseNet、Bypass Net、Prediction Net和Bias Net。
对于ByPass Net,输入是该样本对应位置的点击率b,定义为P(y|Position = p) 。通过参数ΘBY得到输出ZBY,这里类似于youtube的shallow tower,但输入特征只有一个该位置的点击率。
再看看另一侧,输入是特征X,输入特征首先经过Base Net,对应参数为ΘA,得到输出ZA。
得到ZA之后,会经过两个Net,第一个是Bias Net,对应的参数为ΘB,该网络的输出为该样本对应的位置预测点击率,前面说了,由于Feedback Loop的存在,输入特征中是存在一定的偏置信息,那么基于这些特征,是可以学习到一定的偏置信息的。
第二个是Prediction Net,对应的参数为ΘY,得到输出ZY。
2.2 对抗训练过程
接下来我们介绍下对抗训练的过程,主要分为两步。
首先看看对于Bias Net的训练。这一步我们固定其他几个网络的参数,只更新Bias Net的参数ΘB,对应的损失函数为:
![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第6张图片](http://img.e-com-net.com/image/info10/ccec721c7faa42b2b5143c6afe562c87.jpg)
这里我们期望Bias Net能对Base Net得到的输出,能够准确得到其中包含的偏置信息。
当Bias Net训练一轮之后,保持ΘB不变,再训练剩下的网络参数ΘA、ΘY和ΘBY,此时的损失为:
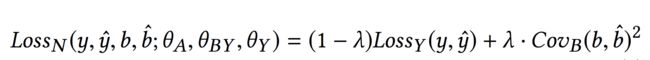
可以看到,损失的第一部分是logloss:
![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第7张图片](http://img.e-com-net.com/image/info10/103cc6a975f9435b86db6369f91243e2.jpg)
第二部分是将此时Base Net所得到的输出,输入到参数固定的Bias Net中,所得到的预测值,和实际样本的位置点击率b的协方差的平方:
![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第8张图片](http://img.e-com-net.com/image/info10/496cbd7418c946af86615bee894b52e7.jpg)
当二者完全不相关时,第二部分的损失是最小的。
好了,对抗学习的思路是如何体现的呢?这里简单说下我的理解。Bias Net相当于GAN中的D,剩余三部分可以看作是G。我们期望Bias Net能够准确识别输入中的偏置信息,而通过剩余三部分的训练,期望Base Net输出的ZA能够骗过Bias Net,如果无法骗过Bias Net,那么Bias Net得到的输出和实际样本的位置点击率b的协方差的平方会比较大,导致整个G的损失增大。如果能够骗过Bias Net,使Bias Net得到的输出和实际样本的位置点击率b的协方差尽可能接近0,那么此时可以认为Base Net输出的ZA中偏置信息基本被消除了。
基于上述介绍,整个对抗网络的训练过程如下:
![推荐系统遇上深度学习(七十三)-[微软]通过对抗训练消除位置偏置信息_第9张图片](http://img.e-com-net.com/image/info10/dc2db60f092544f5a2dbfd936d70ae57.jpg)
2.3 线上应用
那么在线上应用时,只运用Base Net、Prediction Net和Bypass Net。而Bypass Net的输入设置为位置1的位置点击率。
3、实验结果
有关实验结果,论文中使用的是仿真实验的方式,这里就不再细讲,感兴趣的同学可以看下原论文。