第二章 高效排序算法
- 第二章 高效排序算法
- 一、快速排序
-
- 基本思想
-
- 快速排序图示
- 一次划分
-
- C 语言实现
-
- Java 语言实现
-
- 算法分析
- 1> 时间复杂度
- 2> 空间复杂度
- 3> 算法稳定性
-
- 二、堆排序
-
- 什么是堆?
- 堆的图示
-
- 堆调整
- 堆调整图示
-
- 建堆
- 建堆图示
-
- 堆排序基本思想
- 堆排序图示
-
- C 语言实现
-
- Java 语言实现
-
- 算法分析
- 1> 时间复杂度
- 2> 空间复杂度
- 3> 算法稳定性
-
- 三、归并排序
-
- 基本思想
-
- 归并排序图示
-
- C 语言实现
-
- Java 语言实现
-
- 算法分析
- 1> 时间复杂度
- 2> 空间复杂度
- 3> 算法稳定性
-
- 四、基数排序算法
-
- 什么是基数排序?
-
- 基本思想
-
- 基数排序的算法实现图示
-
- C 语言实现
-
- Java 语言实现
-
- 算法分析
- 1> 时间复杂度
- 2> 空间复杂度
- 3> 算法稳定性
-
- 五、各种排序算法的比较
- 六、参考资料
- 一、快速排序
一、快速排序
快速排序 是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了分治法(Divide-and-ConquerMethod)。
1. 基本思想
1.先从数列中随机取出一个数作为基准数(Pivot 枢轴),通常是当前序列的第一个元素;
2.接着,进行一次划分过程:将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边(即:将该数字放在排序后的目标位置上);
3.再对左右区间重复第二步,直到各区间只有一个数。
2. 快速排序图示
一次划分

注: 继续分别对 a[0..1] 和 a[3..4] 进行划分,以此类推,直至完成全部排序。
3. C 语言实现
// 在数组元素 a[low...high] 上的一次划分
int partition(int a[], int low, int high)
{
int pivot = a[low]; // 取区间中的第一个元素作为枢轴
while (low < high) // 当下标 low < high 时,循环
{
// 当a[high] 大于枢轴时,说明a[high] 本来就在枢轴右侧,所以 high 向下移动
while (low < high && a[high] > pivot)
{
high--;
}
// 此时,a[high] 小于pivot,所以,应放在左侧
a[low] = a[high];
// 当a[low] 小于枢轴时,说明a[low] 本来就在枢轴左侧,所以 low 向上移动
while (low < high && a[low] < pivot)
{
low++;
}
// 此时,a[low] 大于pivot,所以,应放在右侧
a[high] = a[low];
}
// 此时,low == high,这就是枢轴的目标位置
a[low] = pivot;
return low; // 返回枢轴的位置
}
// 在数组元素 a[low...high] 上进行排序
void QSort(int a[], int low, int high)
{
if (low < high)
{
// 在数组元素 a[low...high] 上划分并返回 pivot 的位置
int mid = partition(a, low, high);
// 递归调用 QSort,继续在 a[low...mid-1] 上进行划分
QSort(a, low, mid - 1);
// 递归调用 QSort,继续在 a[mid+1...high] 上进行划分
QSort(a, mid + 1, high);
}
}
// 快速排序
void quickSort(int a[], int n)
{
// 在数组 a 的区间 a[0...n-1] 上排序
QSort(a, 0, n - 1);
}
4. Java 语言实现
// 快速排序,详细解释见 C 语言版
public void quickSort(int[] a) {
qsort(a, 0, a.length - 1);
}
// 对区间 a[low..high] 上的元素进行排序
private void qsort(int[] a, int low, int high) {
if (low < high) {
int mid = partition(a, low, high);
qsort(a, low, mid - 1);
qsort(a, mid + 1, high);
}
}
// 在区间 a[low..high] 上进行一次划分
private int partition(int[] a, int low, int high) {
int pivot = a[low];
while (low < high) {
while (low < high && pivot < a[high]) {
high--;
}
a[low] = a[high];
while (low < high && pivot > a[low]) {
low++;
}
a[high] = a[low];
}
a[low] = pivot;
return low;
}
5. 算法分析
1> 时间复杂度
快速排序一次划分的时间复杂度为:O(n)
平均情况下,一次快排需要进行划分次数的时间复杂度为:O(logn)
因此,
- 平均情况下,快速排序的复杂度为:O(nlogn)
- 最坏情况下,快排的时间复杂度为:O(n^2)
- 快排是所有排序算法中,平均性能最好的;并且,可以证明不会再有更快的算法了。
2> 空间复杂度
快排使用了递归,利用栈存储函数状态,平均情况下,空间复杂度为:O(logn)
3> 算法稳定性
快速排序是 不稳定的。
我们简单举个例子,对于序列:8, 4, 24, 12, 8*,进行第一次划分时,我们即看到,8* 和 8 的顺序将会颠倒。
二、堆排序
1. 什么是堆?
堆: n个关键字序列Kl,K2,…,Kn 当满足如下性质之一时,称为(Heap):
- ki <= k2i 且 ki <= k2i+1 (1≤i≤ n/2),此时,称为小顶堆;
- ki >= k2i 且 ki >= k2i+1 (1≤i≤ n/2),此时,称为大顶堆;
- 其中,ki 相当于二叉树的非叶子结点,k2i 则是左子节点,k2i+1 是右子节点
(看不懂,没关系,看下图)
堆的图示
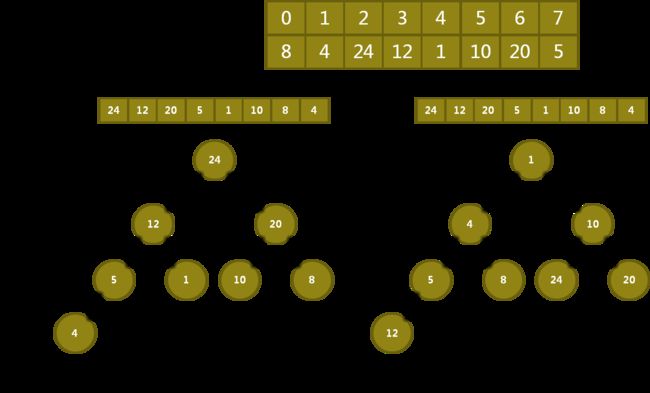
说明:
- 将数组元素按层次排列构造完全二叉树,可得, k2i+1 是 k2i 的左子节点,k2i+2 是 k2i 右子节点;
- 对于大顶堆,从数组来看,每个节点 i,其关键字 ki 均大于节点 k2i 和 k2i + 1;从树结构来看,所有的节点均大于其子节点;
- 对于小顶堆,从数组来看,每个节点 i,其关键字 ki 均小于节点 k2i 和 k2i + 1;从树结构来看,所有的节点均小于其子节点;
2. 堆调整
堆调整: 假设现在有一个序列,除了顶部元素以外,都符合堆的定义,把该序列调整为堆的过程就称为堆调整。堆调整是堆排序算法的 核心。
堆调整图示
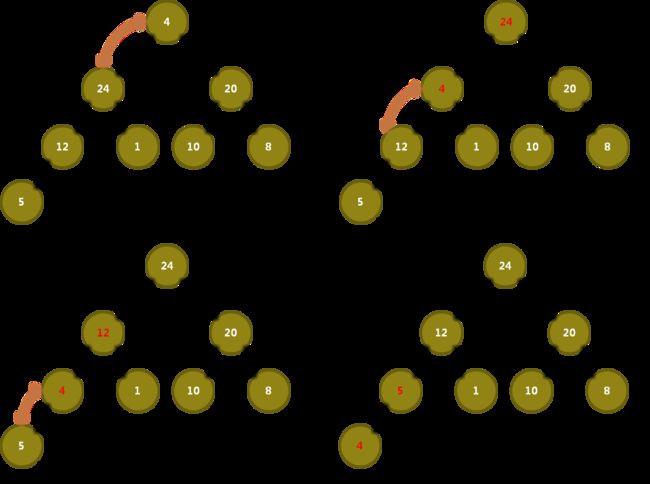
3. 建堆
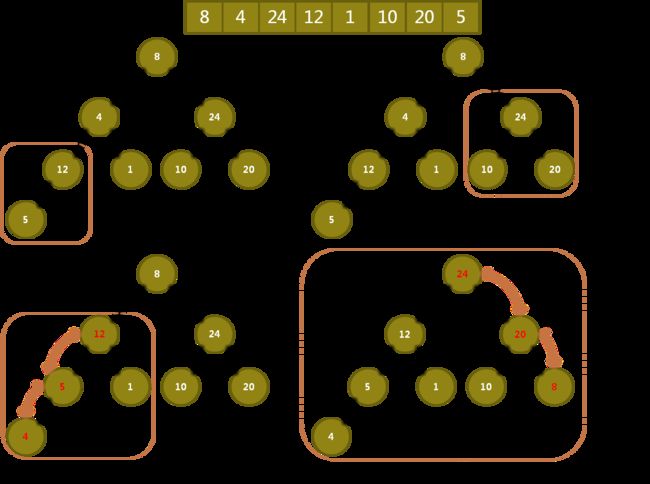
对于一个无序序列,如何构造出一个堆?
建堆就是一个不断进行堆调整的过程,如下所示:
基本思想:
- 从第 i = (n - 1) / 2 个元素(此元素必是最后一个节点的父节点)开始,在区间 a[(n-1)/2 .. (n-1)] 上进行堆调整;
- 接着,从第 i = (n - 1) / 2 - 1 个元素开始,在区间 a[(n-1)/2 - 1 .. (n-1)] 上进行堆调整;
- 以此类推,直到 i = 0,就构造出了一个堆
建堆图示
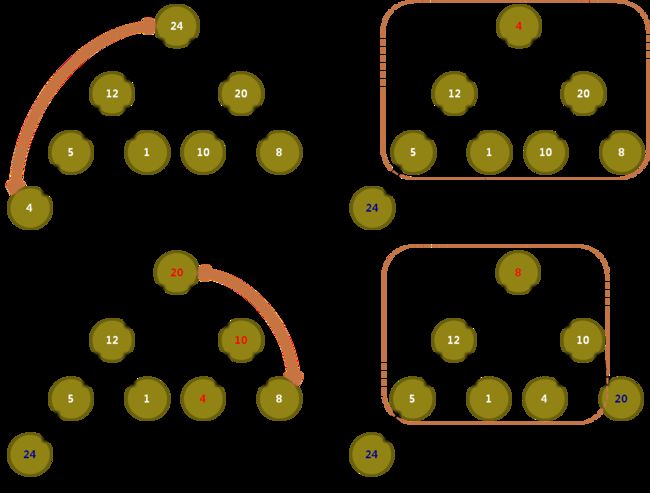
4. 堆排序基本思想
- 对序列
a[0..(n - 1)]进行建堆操作(比如:大顶堆);- 将
a[0]和a[n - 1]交换;- 对序列
a[0..(n - 2)]进行堆调整;- 将
a[0]和a[n - 2]交换;- 以此类推,直到整个序列有序。
堆排序图示

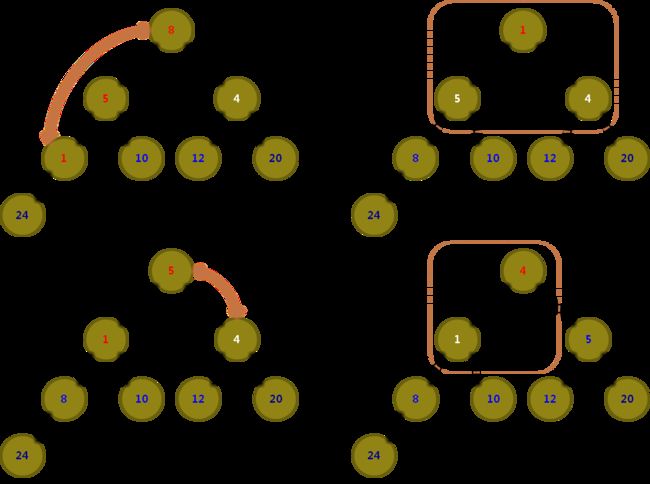
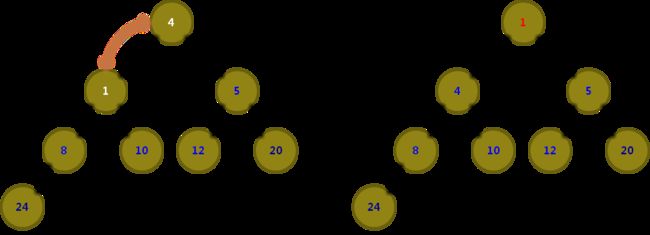
5. C 语言实现
// 堆调整算法
// 输入:数组 a,
// top : 当前需要调整的堆的顶部位置
// max : 堆的下界
// 数组元素 a[top...max] 原本是一个大顶堆,现顶部 a[top] 被修改,可能破坏了堆属性
// 输出:无
// 功能:堆调整,将 a[top...max] 调整为一个堆
// 2 * i + 1 是 i 的左子树
// 2 * i + 2 是 i 的右子树
void HeapAdjust(int a[], int top, int max)
{
// 让 tv 存储当前堆顶元素
int tv = a[top], i = 0;
// i 指向当前堆顶的左子树
for (i = top * 2 + 1; i <= max; i = i * 2 + 1)
{
// 如果左子树小于右子树,i++,让 i 指向右子树,即:i 指向最大的那个子树
if(i < max && a[i] < a[i + 1])
{
i++;
}
// 如果当前堆顶元素大于等于最大子树,则表示现在就是堆结构,退出
if(tv >= a[i])
{
break;
}
// 如果当前堆顶元素小于最大子树,将最大子树放入当前堆顶
a[top] = a[i];
// 让 top 指向最大子树,下次循环,将从最大子树开始继续调整
top = i;
}
// 调整完毕,把最初的堆顶元素放到正确的位置
a[top] = tv;
}
// 输入:数组 a
// 输出:无
// 功能:将数组 a 中元素按升序排列
void HeapSort(int a[], int n)
{
int i = 0, tmp = 0;
printf("堆排序:");
// 建堆
for (i = (n - 1) / 2; i >= 0; i--)
{
HeapAdjust(a, i, n - 1);
}
// 堆排序
for (i = n - 1; i > 0; i--)
{
tmp = a[0];
a[0] = a[i];
a[i] = tmp;
HeapAdjust(a, 0, i - 1);
}
}
6. Java 语言实现
// 详细分析,见 C 语言版
public void heapSort(int[] a) {
if (a == null || a.length == 0) {
return;
}
// 建堆
for (int i = (a.length - 1) / 2; i >= 0; i--) {
heapAdjust(a, i, a.length - 1);
}
for (int i = a.length - 1; i > 0; i--) {
int tmp = a[0];
a[0] = a[i];
a[i] = tmp;
heapAdjust(a, 0, i - 1);
}
}
// 堆调整
private void heapAdjust(int[] a, int top, int max) {
int tv = a[top];
for (int i = top * 2 + 1; i <= max; i = 2 * i + 1) {
if (i < max && a[i] < a[i + 1]) {
i++;
}
if (tv >= a[i]) {
break;
}
a[top] = a[i];
top = i;
}
a[top] = tv;
}
7. 算法分析
1> 时间复杂度
- 堆排序一次堆调整的时间复杂度为:O(logn);
- 构造堆大约需要 n/2 次堆调整;排序时,没输出一个堆顶元素,都需要进行一次堆调整,这样算来需要进行 n - 1 次堆调整;因此,共需要进行 3n/2 - 1 次堆调整;
- 综合来看,堆排序的时间复杂度是:O(nlogn);即使在最坏的情况下,堆排序的时间复杂度也是:O(nlogn)。
2> 空间复杂度
堆排序只额外增加了一个存储空间 tmp,用于交换数据。因此,空间复杂度是:O(1)。
3> 算法稳定性
堆排序是 不稳定的。
三、归并排序
1. 基本思想
1.先将序列看成是 n 个长度为 1 的有序序列,将相邻的有序表成对归并,归并 是指将 2 个有序序列合并成一个有序序列,得到 n / 2 个长度为 2 的有序表;
2.接着,将这些有序序列再次归并,得到 n / 4 个长度为 4 的有序序列;
3.如此反复下去,最后得到一个长度为 n 的有序序列。
2. 归并排序图示

3. C 语言实现
// 借助数组 b,
// 将数组 a 中的有序序列 a[s...m-1] 和 a[m...e] 合并成有序序列 a[s...e]
void Merge(int a[], int b[], int s, int m, int e)
{
// i 指向序列 a[s...m-1] 的起始位置;j 指向序列 a[m..e] 的起始位置;k 指向序列 b[s...e] 的起始位置
int i = s, j = m, k = s;
// 当序列 a[s...m-1] 和序列 a[m...e] 都没有结束时循环
while(i < m && j <= e)
{
// 如果 a[i] < a[j],则把 b[k] = a[i];否则,b[k] = a[j];
if(a[i] < a[j])
{
b[k++] = a[i++];
} else
{
b[k++] = a[j++];
}
}
// 如果序列 a[s...m-1] 没有结束,把剩余部分追加到数组 b 中
while(i < m)
{
b[k++] = a[i++];
}
// 如果序列 a[m...e] 没有结束,把剩余部分追加到数组 b 中
while(j <= e)
{
b[k++] = a[j++];
}
// 把数组 b 中的元素 b[s...e] 复制到 a[s...e] 中
for(k = s; k <= e; k++)
{
a[k] = b[k];
}
}
// 借助数组 b, 将数组元素 a[s...e] 排序
void MSort(int a[], int b[], int s, int e)
{
int m = 0;
// 递归结束条件:当 s < e 时,递归,否则,结束递归
if(s < e)
{
// 计算区间的中间位置 m
m = (s + e) / 2;
// 递归调用,对 a[s...m] 进行归并排序
MSort(a, b, s, m);
// 递归调用,对 a[m+1...e] 进行归并排序
MSort(a, b, m + 1, e);
// 将数组 a 中的有序序列 a[s...m] 和 a[m+1...e] 合并成有序序列 a[s...e]
Merge(a, b, s, m + 1, e);
}
}
// 将数组 a 中的元素按升序排列
void MergeSort(int a[], int n)
{
// 申请额外空间 t 作为数组 b
int* t =(int*)malloc(sizeof(int) * n);
// 对 a[0...(n - 1)] 进行归并排序
MSort(a, t, 0, n - 1);
if(t != NULL)
{
// 释放临时空间
free(t);
t = NULL;
}
}
4. Java 语言实现
// 归并排序,详细解释见 C 语言版
public void mergeSort(int[] a) {
int[] b = new int[a.length];
msort(a, b, 0, a.length - 1);
}
// 将区间 a[s..e] 上的元素进行归并
private void msort(int[] a, int[] b, int s, int e){
if(s < e){
int m = (s + e) / 2;
msort(a, b, s, m);
msort(a, b, m + 1, e);
merge(a, b, s, m + 1, e);
}
}
// 合并数组
private void merge(int[] a, int[] b, int s, int m, int e){
int i = s, j = m, k = s;
while(i < m && j <= e){
if(a[i] < a[j]){
b[k++] = a[i++];
} else{
b[k++] = a[j++];
}
}
while(i < m){
b[k++] = a[i++];
}
while(j <= e){
b[k++] = a[j++];
}
for (k = s; k <= e; k++) {
a[k] = b[k];
}
}
5. 算法分析
1> 时间复杂度
- 归并排序一次归并的时间复杂度为:O(n);
- 归并排序大约要进行 O(logn) 次归并操作;
- 综合来看,归并排序的时间复杂度是:O(nlogn);即使在最坏的情况下,归并排序的时间复杂度也是:O(nlogn)。
2> 空间复杂度
归并排序额外增加了一倍的存储空间,用于存储归并结果。因此,空间复杂度是:O(n)。
3> 算法稳定性
归并排序是 稳定的。
注: 由于归并排序的良好特性,所以,在 Java 中,内置排序函数采用的算法就是归并排序。
四、基数排序算法
1. 什么是基数排序?
基数排序是一种和前述方法完全不同的排序方法。
- 前述方法主要是通过关键字间的比较和移动记录这两种操作,而基数排序不需要进行关键字间的比较;
- 基数排序是一种多关键字排序方式;
- 基数排序是借助“分配” 和 “收集” 两种操作对单逻辑关键字进行排序的一种内部排序方法。
上面的叙述是否比较抽象?下面我们通过一个例子来理解基数排序。
2. 基本思想
如何对序列:08, 04, 24, 12, 01, 10, 20, 05 进行基数排序?
- 由于数字在 0 <= K <= 99 范围内,可以把每一个十进制位数看成一个关键字,即可认为 K 由两个关键字 (K0, K) 组成,其中 K0 是十位数,K1 是个位数;这两个关键字的优先级是不同的,我们知道,十位数比个位数优先,换句话说,十位数是第一关键字,个位数是第二关键字;
-
首先,准备标号为 [0~9] 的十个桶,按照 K1 (个位)进行分配,如下所示;分配完后,我们将结果连接起来,称为“收集”,这样,就得到了一个按照第二关键字排列的序列;
 按照第二关键字排序
按照第二关键字排序 -
然后,根据上次分配的结果,继续按照 K0 (十位)进行分配,如下所示;分配完后,再进行“收集”,在按照第二关节字排序的基础上,我们得到按照第一关键字排列的序列,即:最终结果。
 按照第一关键字排序
按照第一关键字排序
说明:
- 如上面示例所示,先按照个位分配,再按照十位分配,这称为:LSD(Least Significant Digit first) 最低位优先;也可以反过来分配,称之为:MSD(Most Significant Digit first) 最高位优先,不过,此时,必须将序列逐层分割成若干子序列,然后对各子序列分别进行排序。
- 由于每次都需要将元素分配到 “桶” 中,所以,基数排序又称为 “桶排序”(bin sort 或 bucket sort);
- 基数排序中的 “基数” 指的是桶的个数,对于十进制数字来说,基数就是 10。
3. 基数排序的算法实现图示
-
首先,将原始数据存入静态链表 List 中,静态链表是一个数组,其中元素称为节点,节点由 2 部分组成:数据和下个节点的引用(数组下标)。List 的第一个元素是头节点,不存储数据,它的下一个节点引用第一个节点。初始时,原始数据排成一个顺序的静态链表;
 初始化静态链表
初始化静态链表 准备 2 个包含 10 个节点指针(或引用)的数组 f 和 e,用来作为桶头和桶尾;分配时,让 f[i] 指向第 i 个桶的桶头元素,桶中的节点依次连接,最后,让 e[i] 指向第 i 个桶的桶尾元素;回收时,只需让前桶的尾指向后桶的头即可连接在一起;
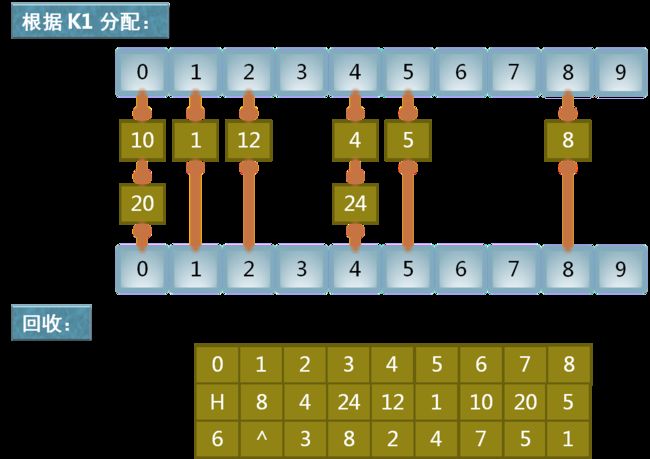
-
按照第一关键字进行分配和回收,重用数组 f 和 e。
 按照第一关键字进行分配和回收
按照第一关键字进行分配和回收
4. C 语言实现
#define MAX_NUM_OF_KEY 2 // 关键字个数
#define RADIX 10 // 基数
#define MAX_SPACE 10000 // 静态链表最大空间
typedef struct{
int keys[MAX_NUM_OF_KEY]; // 关键字数组
int next;
} Cell; // 节点结构
typedef struct{
Cell r[MAX_SPACE];
int keyNum; // 当前关键字个数
int recNum; // 链表当前长度
} List; // 定义 List 类型
typedef int Bucket[RADIX]; // 桶头或桶尾数组类型
// 分配:对序列 r[],按照第 i 个关键字进行分配
// r : 序列头部元素
// i : 表示第几个关键字
// f : 桶头数组指针
// e : 桶尾数组指针
void Distribute(Cell r[], int i, Bucket *f, Bucket *e)
{
int j = 0, p = 0;
// 初始化桶头为 0
for(j = 0; j < RADIX; j++)
{
(*f)[j] = 0;
}
// 遍历静态链表中所有节点,进行分配操作
for(p = r[0].next; p; p = r[p].next)
{
// 根据当前关键字获取桶位置
j = r[p].keys[i];
// 判断桶头是否为空
if(!(*f)[j])
{ // 如果桶头为空,则让桶头指向当前节点
(*f)[j] = p;
} else
{ // 如果桶头不为空,则让桶中当前最后节点指向当前节点
r[(*e)[j]].next = p;
}
// 让桶尾指向当前节点
(*e)[j] = p;
}
}
// 收集:将桶中元素依次首尾相连,放入静态链表 r 中
// r : 序列头部元素
// i : 表示第几个关键字
// f : 桶头
// e : 桶尾
void Collect(Cell r[], int i, Bucket *f, Bucket *e)
{
int j = 0, t = 0;
// 找第一个非空桶
for(j = 0; !(*f)[j]; j++);
// 让头节点 r[0].next 指向第一个非空桶中的第一个元素
r[0].next = (*f)[j];
// 让 t 指向第一个非空桶的最后一个元素
t = (*e)[j];
// j 小于桶数时循环
while(j < RADIX)
{ // 找下一个非空桶
for(j++; j < RADIX && !(*f)[j]; j++);
if(j < RADIX && (*f)[j])
{ // 如果找到下一个非空桶,让上一个节点指向当前桶的头节点
r[t].next = (*f)[j];
// 让 t 指向当前非空桶的最后一个元素
t = (*e)[j];
}
}
// 将最后一个元素的下一个元素置 0
r[t].next = 0;
}
// 基数排序
void RadixSort(List *L)
{
int i = 0;
Bucket f, e;
// 对每个关键字,按照关键字重要性递增顺序,分别进行一次分配和收集操作
for(i = L->keyNum - 1; i >= 0; i--)
{
Distribute(L->r, i, &f, &e);
Collect(L->r, i, &f, &e);
}
}
// 初始化静态链表,让节点依次相连
void Init(List *L)
{
int i = 0;
// 构造元素静态链表
for(i = 0; i < L->recNum; i++)
{ // 每个节点都指向下一个节点
L->r[i].next = i + 1;
}
// 最后一个节点的下一个节点为 0,表示结束
L->r[L->recNum].next = 0;
}
// 显示静态链表中数据
void Show(List *L)
{
int i = 0, j = 0;
for(i = L->r[0].next; i; i = L->r[i].next)
{
for(j = 0; j < L->keyNum; j++)
{
printf("%d", L->r[i].keys[j]);
}
printf(", ");
}
printf("\n");
}
// 测试
int main()
{
List list;
int i = 0;
// 初始化静态链表的关键字个数和数据元素个数
list.keyNum = 2;
list.recNum = 8;
// 对每个数据元素,初始化第一关键字和第二关键字
list.r[1].keys[0] = 0;
list.r[1].keys[1] = 8;
list.r[2].keys[0] = 0;
list.r[2].keys[1] = 4;
list.r[3].keys[0] = 2;
list.r[3].keys[1] = 4;
list.r[4].keys[0] = 1;
list.r[4].keys[1] = 2;
list.r[5].keys[0] = 0;
list.r[5].keys[1] = 1;
list.r[6].keys[0] = 1;
list.r[6].keys[1] = 0;
list.r[7].keys[0] = 2;
list.r[7].keys[1] = 0;
list.r[8].keys[0] = 0;
list.r[8].keys[1] = 5;
// 初始化静态链表
Init(&list);
// 显示原始数据
Show(&list);
// 基数排序
RadixSort(&list);
// 显示排序后数据
Show(&list);
return 0;
}
5. Java 语言实现
public class RadixList {
class Cell{
Integer e; // 数据元素
int next; // 下一个元素的引用
}
public static final int RADIX = 10;
private List list;
private int keyNum; // 关键字个数
private int[] f; // 桶头
private int[] e; // 桶尾
public RadixList() {
f = new int[RADIX];
e = new int[RADIX];
list = new ArrayList| ();
add(0); // 插入头节点
}
public int size(){
return list.size();
}
// 向静态链表插入一个元素
public void add(Integer data){
Cell cell = new Cell();
cell.e = data;
if(list.size() == 0) {
list.add(cell);
return;
}
Cell last = list.get(list.size() - 1);
list.add(cell);
last.next = list.size() - 1; // 让先前的最后一个元素指向新节点
// 计算插入元素的位数,即:关键字个数
int high = 0;
int tmp = data;
while(tmp > 0){
high++;
tmp /= 10;
}
if(high > keyNum){
keyNum = high;
}
}
// 排序
public void sort(){
for(int i = 0; i < keyNum; i++){
distribute(i);
collect(i);
}
}
// 分配:按照第 i 个关键字分配
private void distribute(int i){
for(int k = 0; k < f.length; k++){
f[k] = 0;
}
Cell head = list.get(0);
for(int c = head.next; c > 0; c = list.get(c).next){
int bit = getBit(list.get(c).e, i);
if(f[bit] > 0){
list.get(e[bit]).next = c;
} else{
f[bit] = c;
}
e[bit] = c;
}
}
// 收集
private void collect(int i){
int k = 0;
for(; f[k] == 0; k++); // 获取第一个非空桶
list.get(0).next = f[k];
int t = e[k];
while(k < RADIX){
for(k++; k < RADIX && f[k] == 0; k++); // 获取下一个非空桶
if(k < RADIX && f[k] > 0){
list.get(t).next = f[k];
t = e[k];
}
}
list.get(t).next = 0;
}
public void show(){
for(int c = list.get(0).next; c > 0; c = list.get(c).next){
System.out.print(list.get(c).e + ", ");
}
System.out.println();
}
// 求数字 n 的第 i 位数字, 0 表示个位
private static int getBit(int n, int i){
if(n == 0){
return 0;
}
int k = 0, r = 0;
while(k <= i){
r = n % 10;
n /= 10;
k++;
}
return r;
}
public static void main(String[] args) {
RadixList radixList = new RadixList();
radixList.add(8);
radixList.add(4);
radixList.add(24);
radixList.add(12);
radixList.add(1);
radixList.add(10);
radixList.add(20);
radixList.add(5);
System.out.println("排序前:");
radixList.show();
radixList.sort();
System.out.println("排序后:");
radixList.show();
}
}
| | 6. 算法分析
1> 时间复杂度
设待排序列为 n 个记录,d 个关键码,关键码的取值范围为 radix;
- 一趟分配时间复杂度为:O(n);
- 一趟收集时间复杂度为:O(radix);
- 共进行 d 趟分配和收集。
进行链式基数排序的整体时间复杂度为:O(d * (n+radix))
2> 空间复杂度
需要 2 * radix 个指向队列的辅助空间,所以空间复杂度为:O(radix)
3> 算法稳定性
基数排序是 稳定的。
简单说明一下,首先,按照原始顺序进行分配,收集后得到的结果中,相同关键字仍然按照原始顺序排列,以后的分配也是如此,即:分配的过程不会改变相同关键字的顺序。
五、各种排序算法的比较
| 排序算法 | 平均时间复杂度 | 最坏情况时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|
| 冒泡排序 | O(n^2) | O(n^2) | O(1) | 稳定 |
| 简单选择排序 | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 直接插入排序 | O(n^2) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 快速排序 | O(nlogn) | O(n^2) | O(logn) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 基数排序 | O(d * (n+radix)) | O(d * (n+radix)) | O(radix) | 稳定 |
注:
- 通常时间复杂度为:O(n^2) 的算法都是稳定的,除了简单选择排序和希尔排序;
- 通常时间复杂度为:O(nlogn) 的算法都是不稳定的,除了归并排序;
六、参考资料
- 算法动画:http://jsdo.it/norahiko/oxIy/fullscreen