数据来源
Python爬虫爬取了智联招聘关键词:【Python】、全国30个主要城市的搜索结果,总职位条数:18326条(行),其中包括【职位月薪】、【公司链接】、【工作地点】、 【岗位职责描述】等14个字段列,和一个索引列【ZL_Job_id】共计15列。数据存储在本地MySql服务器上,从服务器上导出json格式的文件,再用Python进行数据读取分析和可视化。
Python学习交流圈:906407826 欢迎加入学习交流海量资料免费拿
入门、进阶、项目等资料自取
数据简单清洗:
1.首先在终端中打开输入ipython --pylab。在Ipython的shell界面里导入常用的包numpy、pandas、matplotlib.pyplot。用pandas的read_json()方法读取json文件,并转化为用df命名的DataFrame格式文件。(DataFrame格式是Pandas中非常常用且重要的一种数据存储格式、类似于Mysql和Excel中的表。)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_json('/Users/zhaoluyang/Desktop/Python_全国JSON.json')
#查看df的信息
df.info()
df.columns

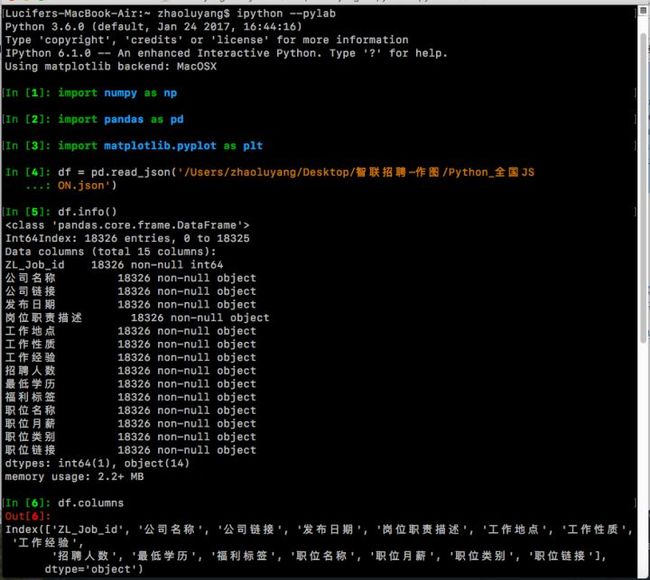
可以看到读取的df格式文件共有15列,18326行,pandas默认分配了索引值从0~18325。还有一点值得注意的:全部的15列都有18326个非空值,因为当初写爬虫代码时设置了, 如果是空值,譬如:有一条招聘信息其中【福利标签】空着没写,那么就用字符串代替,如“found no element”。
2.读取JSON文件时pandas默认分配了从0开始的索引,由于文件'ZL_Job_id'列中自带索引,故将其替换!替换后,用sort_index()给索引重新排列。
df.index = df['ZL_Job_id']#索引列用'ZL_Job_id'列替换。
del(df['ZL_Job_id'])#删除原文件中'ZL_Job_id'列。
df_sort = df.sort_index()#给索引列重新排序。
df = df_sort
df[['工作地点','职位月薪']].head(10)
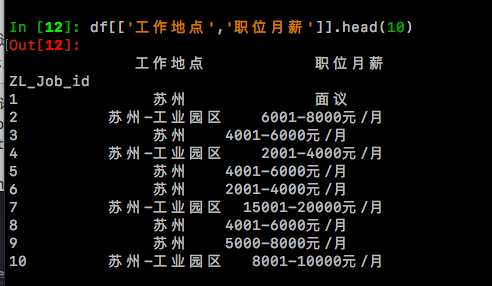
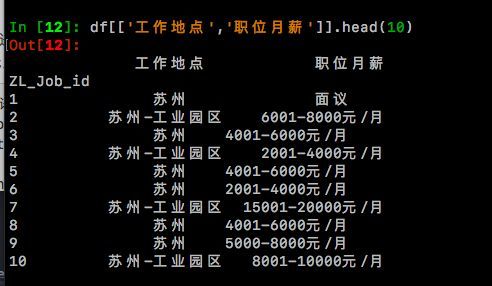
3.下面,将进行【职位月薪】列的分列操作,新增三列【bottom】、【top】、【average】分别存放最低月薪、最高月薪和平均月薪。 其中try语句执行的是绝大多数情况:职位月薪格式如:8000-10000元/月,为此需要对【职位月薪】列用正则表达式逐个处理,并存放至三个新列中。 处理后bottom = 8000,top = 10000,average = 9000. 其中不同语句用于处理不同的情况,譬如【职位月薪】=‘面议’、‘found no element’等。对于字符形式的‘面议’、‘found no element’ 处理后保持原字符不变,即bottom = top = average = 职位月薪。
q1,q2,q3,q4用来统计各个语句执行次数.其中q1统计职位月薪形如‘6000-8000元/月’的次数;q2统计形如月收入‘10000元/月以下’;q3代表其他情况如‘found no element’,‘面议’的次数;q4统计失败的特殊情况。
import re
df['bottom'] = df['top'] = df['average'] = df['职位月薪']
pattern = re.compile('([0-9]+)')
q1=q2=q3=q4=0
for i in range(len(df['职位月薪'])):
item = df['职位月薪'].iloc[i].strip()
result = re.findall(pattern,item)
try:
if result:
try:
#此语句执行成功则表示result[0],result[1]都存在,即职位月薪形如‘6000-8000元/月’
df['bottom'].iloc[i],df['top'].iloc[i] = result[0],result[1]
df['average'].iloc[i] = str((int(result[0])+int(result[1]))/2)
q1+=1
except:
#此语句执行成功则表示result[0]存在,result[1]不存在,职位月薪形如‘10000元/月以下’
df['bottom'].iloc[i] = df['top'].iloc[i] = result[0]
df['average'].iloc[i] = str((int(result[0])+int(result[0]))/2)
q2+=1
else:
#此语句执行成功则表示【职位月薪】中并无数字形式存在,可能是‘面议’、‘found no element’
df['bottom'].iloc[i] = df['top'].iloc[i] = df['average'].iloc[i] = item
q3+=1
except Exception as e:
q4+=1
print(q4,item,repr(e))
for i in range(100):#测试一下看看职位月薪和bottom、top是否对的上号
print(df.iloc[i][['职位月薪','bottom','top','average']])#或者df[['职位月薪','bottom','top','average']].iloc[i]也可
df[['职位月薪','bottom','top','average']].head(10)
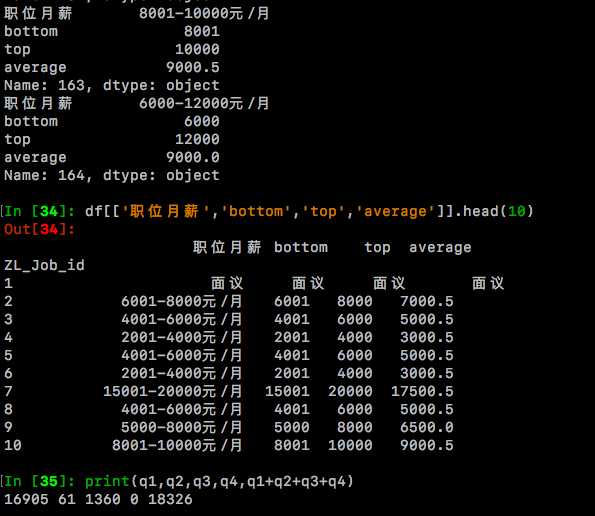
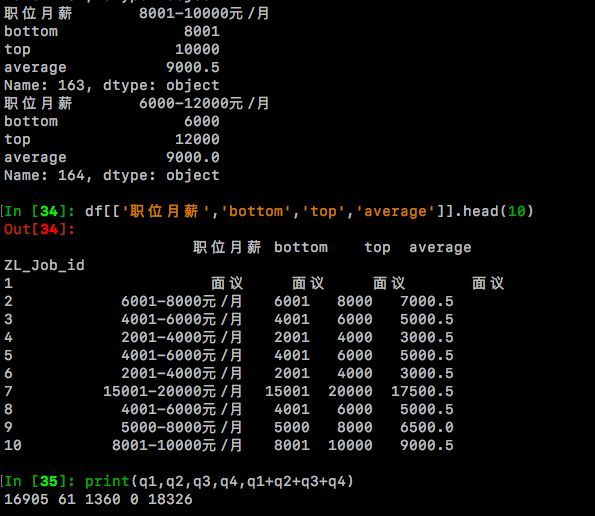
经过检查,可以发现【职位月薪】和新增的bottom、top、average列是能对的上。其中形如‘6000-8000元/月’的有16905条、形如‘10000元以下’的 有61条、'found no element'和'面议'加起来有1360条,总数18326条,可见是正确的。
4.进行【工作地点】列的处理,新增【工作城市】列,将工作地点中如‘苏州-姑苏区’、‘苏州-工业园区’等统统转化为‘苏州’存放在【工作城市】列。
df['工作城市'] = df['工作地点']
pattern2 = re.compile('(.*?)(\-)')
df_city = df['工作地点'].copy()
for i in range(len(df_city)):
item = df_city.iloc[i].strip()
result = re.search(pattern2,item)
if result:
print(result.group(1).strip())
df_city.iloc[i] = result.group(1).strip()
else:
print(item.strip())
df_city.iloc[i] = item.strip()
df['工作城市'] = df_city
df[['工作地点','工作城市']].head(20)
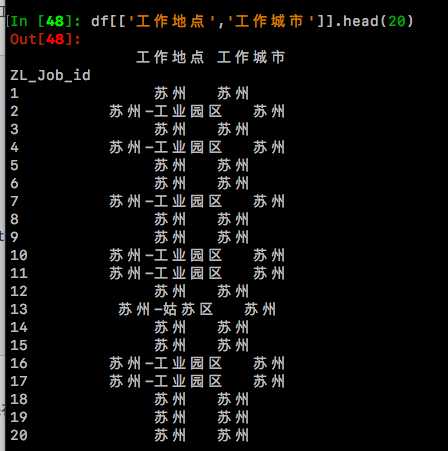

检查一下,没有错误,可以进行下一步的操作了!
数据分析和可视化
从可读性来看,应该是先进行数据清洗,然后进行分析及可视化,但是实际过程中,往往是交织在一起的, 所有下面让我们一步步来,完成所有的清洗、分析和可视化工作。除了具体的公司和职位名称以外,我们还比较关心几个关键词: 平均月薪、工作经验、工作城市、最低学历和岗位职责描述,这里岗位职责描述以后会用python分词做词云图,所以目前筛选出 【平均月薪】、【工作经验】、【工作城市】、【最低学历】这四个标签,这些标签可以两两组合产生各种数据。譬如我想知道各个城市的招聘数量分布情况, 会不会大部分的工作机会都集中在北上广深?是不是北上广深的平均工资也高于其他城市?我想知道Python这个关键词的18000多条招聘数据中 对学历的要求和对工作经验的要求,以及它们分别占比多少?我还想知道平均月薪和工作经验的关系?最低学历和平均月薪的关系? 和上一篇(Execel篇)类似,不同的是,这次我们完全用Python实现同样的操作。
1.各个城市职位数量及分布
根据猜想,北上广深,一定占据了Python这个关键词下大部分的工作机会,会不会符合28定律?20%的城市占据了80%的岗位? 有可能!我们先用df.工作城市.value_counts()看一下究竟有多少个城市,以及他们各自有多少条工作数据?
df.工作城市.value_counts()#等价于df['工作城市'].value_counts()
#再用count()来看一下统计出来的城市数量
df.工作城市.value_counts().count()
type(df.工作城市.value_counts())#用type()查看下类型。
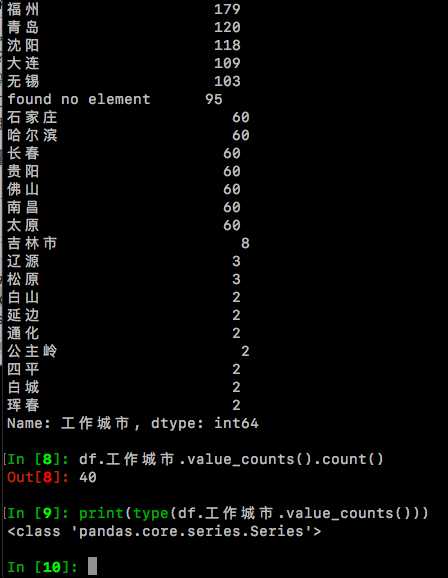
可以看到,明明设置的是搜索30个城市,怎么变成了40?像延边、珲春、白山。。。。是什么鬼?想了一下,这些城市是搜索关键词城市‘吉林市’时,自动冒出来的;还有95个‘found no element’,是这些职位链接本身就没有填写工作城市,为了避免干扰,要把他们统统替换成空值。用df_工作城市 = df['工作城市'].replace()
#将原来df['工作城市']列中选定的字段替换成空值nan
df_工作城市 = df['工作城市'].replace(['found no element','松原','辽源','珲春','白山','公主岭','白城','延边','四平','通化'],np.nan)
#查看替换后各个城市职位计数
df_工作城市.value_counts()
#查看替换后城市所包含的职位总数;查看替换后的城市数量,是否等于30.
df_工作城市
#将新的[df_工作城市]列添加到df表中,留作备用
df['df_工作城市'] = df_工作城市

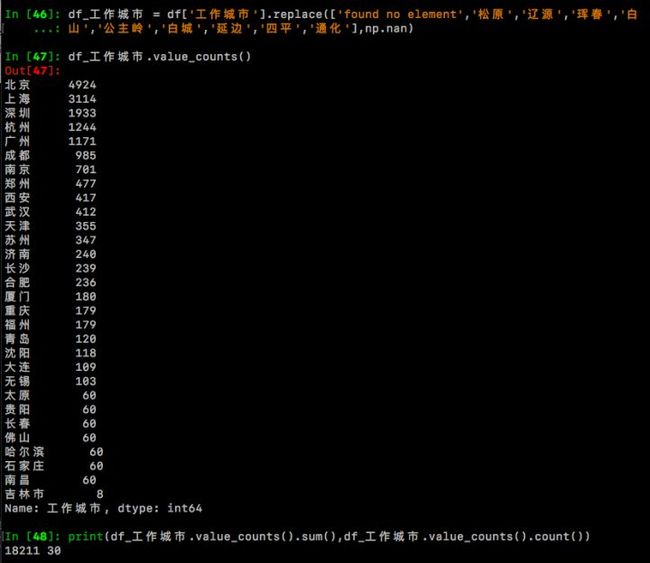
看了一下,没有问题,现在df_工作城市中筛选出了30个城市,合计18211条职位数据。 为了数据完整性,df表保持原样,我们用df_工作城市直接操作,进行下一步的可视化。先直接上代码和图,再一一解释下。
fig1 = plt.figure(1,facecolor = 'black')#设置视图画布1
ax1 = fig1.add_subplot(2,1,1,facecolor='#4f4f4f',alpha=0.3)#在视图1中设置子图1,背景色灰色,透明度0.3(figure.add_subplot 和plt.suplot都行)
plt.tick_params(colors='white')#设置轴的颜色为白色
df_工作城市.value_counts().plot(kind='bar',rot=0,color='#ef9d9a')#画直方图图
#设置图标题,x和y轴标题
title = plt.title('城市——职位数分布图',fontsize=18,color='yellow')#设置标题
xlabel = plt.xlabel('城市',fontsize=14,color='yellow')#设置X轴轴标题
ylabel = plt.ylabel('职位数量',fontsize=14,color='yellow')#设置Y轴轴标题
#设置说明,位置在图的右上角
text1 = ax1.text(25,4500,'城市总数:30(个)',fontsize=12, color='cyan')#设置说明,位置在图的右上角
text2 = ax1.text(25,4000,'职位总数:18326(条)',fontsize=12, color='cyan')
text3 = ax1.text(25,3500,'有效职位:18211(条)',fontsize=12, color='red')
#添加每一个城市的坐标值
for i in range(len(list_1)):
ax1.text(i-0.3,list_1[i],str(list_1[i]),color='yellow')
#可以用plt.grid(True)添加栅格线
#可以用下面语句添加注释箭头。指向上海,xy为坐标值、xytext为注释坐标值,facecolor为箭头颜色。
#arrow = plt.annotate('职位数:3107', xy=(1,3107), xytext=(3, 4000),color='blue',arrowprops=dict(facecolor='blue', shrink=0.05))
ax2 = fig1.add_subplot(2,1,2)#设置子图2,是位于子图1下面的饼状图
#为了方便,显示前8个城市的城市名称和比例、其余的不显示,用空字符列表替代,为此需要构造列表label_list和一个空字符列表['']*23。
x = df_工作城市.value_counts().values#x是数值列表,pie图的比例根据数值占整体的比例而划分
label_list = []#label_list是构造的列表,装的是前8个城市的名称+职位占比。
for i in range(8):
t = df_工作城市.value_counts().values[i]/df_工作城市.value_counts().sum()*100
city = df_工作城市.value_counts().index[i]
percent = str('%.1f%%'%t)
label_list.append(city+percent)
#labels参数原本是与数值对应的标签列表,此处30个城市过多,所以只取了前8个城市显示。
#explode即饼图中分裂的效果explode=(0.1,1,1,。。)表示第一块图片显示为分裂效果
labels = label_list + ['']*22
explode = tuple([0.1]+[0]*29)
plt.pie(x,explode=explode,labels=labels,textprops={'color':'yellow'})
#可加参数autopct='%1.1f%%'来显示饼图中每一块的比例,但是此处30个城市,如果全显示的话会非常拥挤不美观,所以只能手动通过labels参数来构造。
#若要显示标准圆形,可以添加:plt.axis('equal')
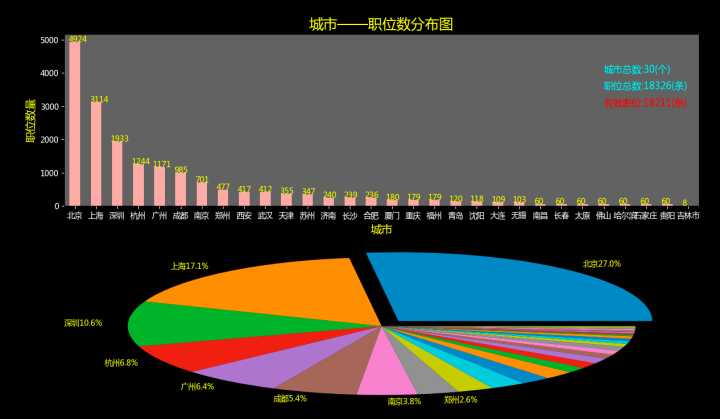

可以看见,这个曲线下降的弧度还是挺美的,北上深杭广5个城市占据了超过60%以上的职位数。其中北京当之无愧的占据了四分之一的Python工作数量,不愧为帝都。 上海以3107条职位排名第二,可见上海虽然经济超越北京,在互联网环境和工作机遇方面还需努力!深圳作为中国的科技中心,排名第三我是没疑问的,杭州竟然超过广州排名第四!不过也可以想到,阿里巴巴、百草味等等电商产业带动了整个杭州的互联网文化!
【北上深杭广】+成都、南京、郑州,这8个城市占据了全国30座城市中,近80%的工作机会!剩下的22个城市合起来只占据了20%,果然,是基本符合28定律的。。。
2.工作经验-职位数量及分布
Python虽然是一名比较老的语言,但是在人们的印象中火起来也就最近几年,Python相关的工作对于【工作经验】是怎样要求的呢?让我们来看看!
df.工作经验.value_counts()#统计【工作经验】下各个字段的累计和

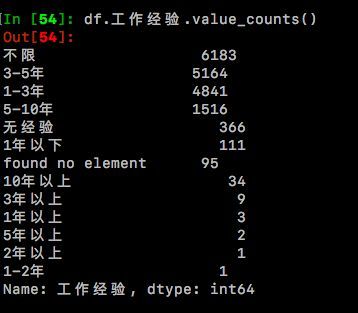
可以看见出现了一些很数字少量的字段譬如“5年以上”,“2年以上”,“1-2年”,“1年以上”等,这些标签下职位的数量都在10以内,不太具备统计意义,所以我们作图的时候不想让他们出现,必须筛选掉。 下面我们还是通过同样的步骤来清除掉此类数据。
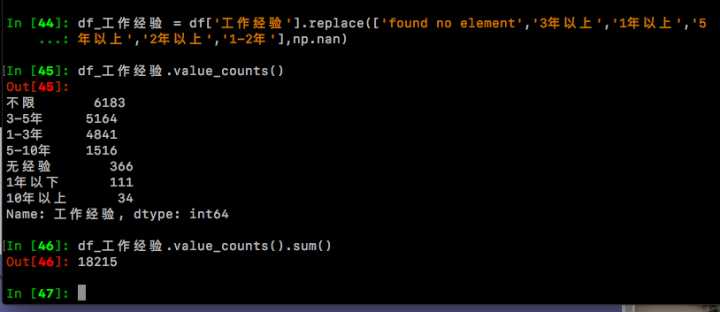
= df['工作经验'].replace(['found no element','3年以上','1年以上','5年以上','2年以上','1-2年'],np.nan)
df_工作经验.value_counts()
df_工作经验.value_counts().sum()
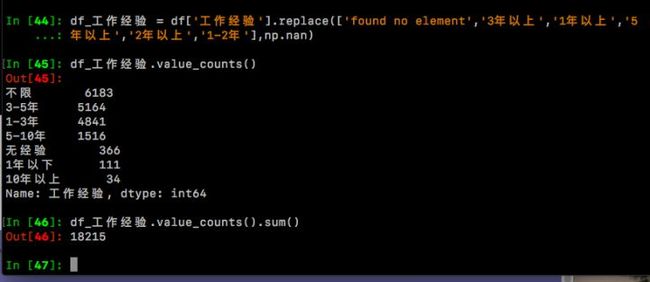
现在,可以进行下一步可视化了,还是做2张图:直方图和饼图。通过这两张图可以直观地看到这么多职位中对不同工作经验的要求占比,好做到心里有数!
fig2 = plt.figure(2,facecolor = 'black')
ax2_1 = fig2.add_subplot(2,1,1,facecolor='#4f4f4f',alpha=0.3)
plt.tick_params(colors='white')
df_工作经验.value_counts().plot(kind = 'bar',rot = 0,color='#7fc8ff')
title = plt.title('工作经验——职位数分布图',fontsize = 18,color = 'yellow')
xlabel = plt.xlabel('工作经验',fontsize = 14,color = 'yellow')
ylabel = plt.ylabel('职位数量',fontsize = 14,color = 'yellow')
plt.grid(True)
text1_ = ax2_1.text(5,5600,'城市总数:30(个)',fontsize=12, color='yellow')
text2 = ax2_1.text(5,4850,'职位总数:18326(条)',fontsize=12, color='yellow')
text3 = ax2_1.text(5,4100,'有效职位:18215(条)',fontsize=12, color='cyan')
#设置子图2,是位于子图1下面的饼状图
ax2_2 = fig2.add_subplot(2,1,2)
#x是数值列表,pie图的比例根据数值占整体的比例而划分
x2 = df_工作经验.value_counts().values
labels = list(df_工作经验.value_counts().index[:5])+ ['']*2
explode = tuple([0.1,0.1,0.1,0.1,0.1,0.1,0.1])
plt.pie(x2,explode=explode,labels=labels,autopct='%1.1f%%',textprops={'color':'yellow'})
plt.axis('equal')#显示为等比例圆形
#设置图例,方位为右下角
legend = ax2_2.legend(loc='lower right',shadow=True,fontsize=12,edgecolor='cyan')
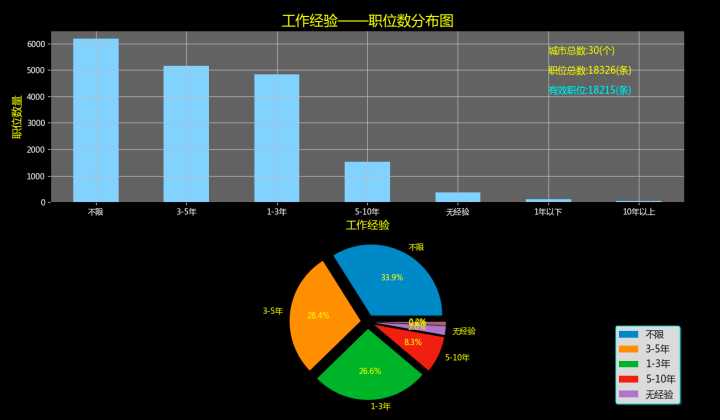
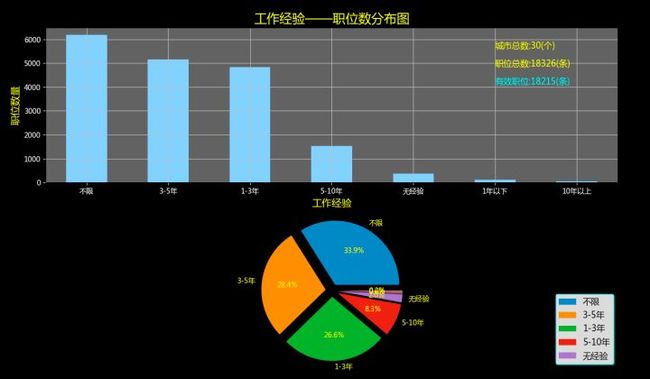
总共得到18215条职位。从直方图里可以明显看出工作机会集中在'不限'、'1-3年'、'3-5年', 其中工作经验要求3年以下的(【无经验】+【不限】+【1年以下】+【1-3年】)合计11501条职位,占比超过63%,看来即使是初入门者,大家的机会也还是有不少的! (PS:最后,在df表中添加一列'df_工作经验',以后筛选时就可以直接用了,df['df_工作经验']=df_工作经验)
3.工作经验-平均月薪
这个嘛,大家闭着眼都能想到!肯定是工作经验越久的拿钱越多了!再猜猜?无经验的和5-10年经验的收入差距有多大?这个,嘿嘿就不好猜了,让我们来看看吧!
1.第一步,要想统计工作经验和平均月薪的关系,那么我们先看看df中对应的列df.工作经验和df.average。之前我们构造了一列df_工作经验,把df.工作经验中几个样本容量小于10的值和‘found no element’全筛选掉了,故df_工作经验还能继续使用。现在,让我们看看df.average的信息。
df.average.value_counts()
可以看到,其中有1265个值是‘面议’,有95个值是‘found no element’,这些值需要替换成空值,不然会影响下一步工资的计算。
df_平均月薪 = df['average'].replace(['面议','found no element'],np.nan)
2.好了,第一步的简单数据清洗完成了,我们可以思考下一步了,现在我们想要得到的是不同工作经验字段下的平均月薪
A. 首先我需要把df_工作经验和df_平均月薪这两列元素放在一起,构造一个DataFrame用于存放df_工作经验和df_平均月薪这两列元素,且方便进一步的groupby操作。
B. 其次我需要把df_平均月薪列根据df_工作经验进行分组(用groupby),分组后我可以求得df_工作经验下各个字段的月薪的计数、最大值最小值、累加和、平均值等一系列数据。
C. 当然此处我只需要平均值。对分组后的grouped用mean()方法,就可以轻松统计分组内各项的平均值了。
df3=pd.DataFrame(data={'工作经验':df['df_工作经验'],'平均月薪':df_平均月薪})
df3.info()
grouped3 = df3['平均月薪'].groupby(df3['工作经验'])
grouped3.mean()

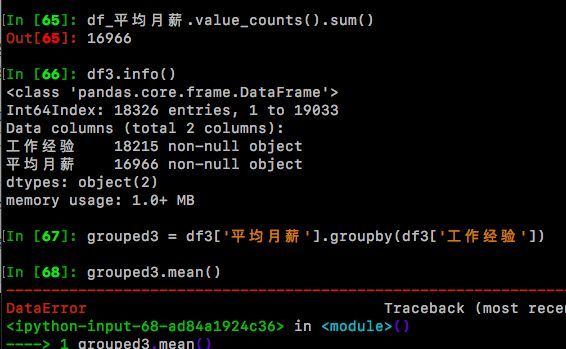
在进行grouped3.mean()时,我们发现报错了:DataError: No numeric types to aggregate,看一下,原来df_平均月薪列里的值都是字符型str,并不是数值型的float,因为前面的步骤没有做好,留下了这个bug,无奈我们需要对值类型做个转换。
#构造一个listi存放转化后float型的‘平均月薪’
import re
pattern = re.compile('([0-9]+)')
listi = []
for i in range(len(df.average)):
item = df.average.iloc[i].strip()
result = re.findall(pattern,item)
try:
if result:
listi.append(float(result[0]))
elif (item.strip()=='found no element' or item.strip()=='面议'):
listi.append(np.nan)
else:
print(item)
except Exception as e:
print(item,type(item),repr(e))
#将df3.平均月薪列替换掉,同时给df新增一列'df_平均月薪'做备用。
df3['平均月薪'] = listi
df['df_平均月薪'] = df3['平均月薪']
#看看更新后的数据是否正确
df3['平均月薪'].value_counts()#统计每个月薪字段的个数
df3['平均月薪'][:10]#查看前10个值
type(df3['平均月薪'][1])#看看现在月薪的类型是不是浮点型
df3['平均月薪'].value_counts().sum()#看看月薪样本总数
df3['平均月薪'].mean()#看看这16966个月薪样本的平均值是多少?

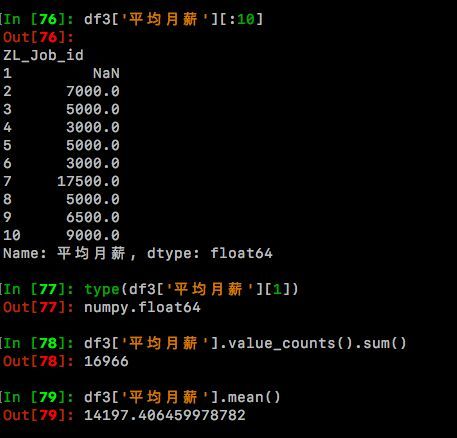
可以看到,替换后的df3['平均月薪']值从str变为了可以计算的float,月薪样本总数16966个,样本的平均月薪14197元。好,现在终于OK了,让我们再回到之前的步骤:
grouped3 = df3['平均月薪'].groupby(df3['工作经验'])
grouped3.mean()
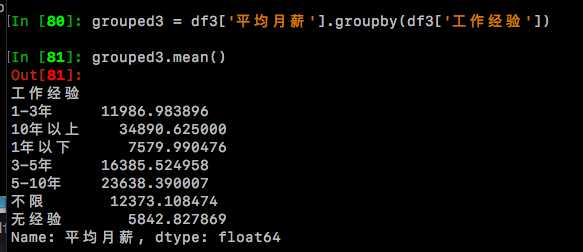
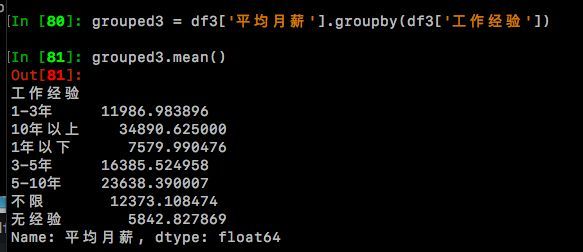
好了,完美,格式对了,数据有了,现在可以来画图了!但是再看看,还不是那么完美,数据大小排列很乱,而且小数点那么多。。。好吧,让我们再简单处理下
#新增一个平均值,即所有非空df3['平均月薪']的平均值
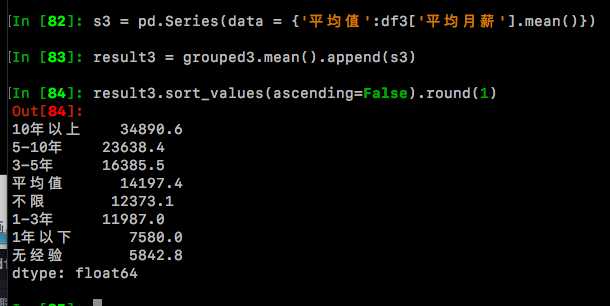
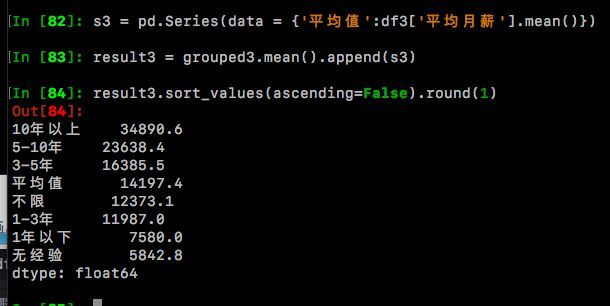
s3 = pd.Series(data = {'平均值':df3['平均月薪'].mean()})
result3 = grouped3.mean().append(s3)
#sort_values()方法可以对值进行排序,默认按照升序,round(1)表示小数点后保留1位小数。
result3.sort_values(ascending=False).round(1)
3.数据可视化
这次我们画一个躺倒的柱状图(barh),用ggplot的风格来画。
matplotlib.style.use('ggplot')
fig3 = plt.figure(3,facecolor = 'black')
ax3 = fig3.add_subplot(1,1,1,facecolor='#4f4f4f',alpha=0.3)
result3.sort_values(ascending=False).round(1).plot(kind='barh',rot=0)
#设置标题、x轴、y轴的标签文本
title = plt.title('工作经验——平均月薪分布图',fontsize = 18,color = 'yellow')
xlabel= plt.xlabel('平均月薪',fontsize = 14,color = 'yellow')
ylabel = plt.ylabel('工作经验',fontsize = 14,color = 'yellow')
#添加值标签
list3 = result3.sort_values(ascending=False).values
for i in range(len(list3)):
ax3.text(list3[i],i,str(int(list3[i])),color='yellow')
#设置标识箭头
arrow = plt.annotate('Python平均月薪:14197元/月', xy=(14197,3.25), xytext=(20000,4.05),color='yellow',fontsize=16,arrowprops=dict(facecolor='cyan', shrink=0.05))
#设置图例注释(16966来源:df2['平均月薪'].value_counts().sum())
text= ax3.text(27500,6.05,'月薪样本数:16966(个)',fontsize=16, color='cyan')
#设置轴刻度文字颜色为白色
plt.tick_params(colors='white')


通过图表,我们可以直观地看到,Python关键词下的职位月薪是随着工作经验增长而递增的(这不是说了一句废话么?!囧) 其中【无经验】的平均月薪最低,只有5842,相比之下【10年以上】经验的,平均月薪达到了恐怖的34890,约达到了【无经验】月薪的6倍之多!!! 【1年以下】的平均月薪7579,还勉强凑合,【1-3年】的已经破万了,达到了近12000元/月的水准。最后让我们看看平均值吧,由于‘被平均’的缘故,16966条月薪样本的均值是14197元,有没有让你满意呢?
4.工作城市-平均月薪
对了,刚才说到北上广深占据了全国大部分的工作机会,那么北上广深的平均月薪如何呢?会不会也碾压小城市?让我们来看看! 和之前的套路一样,我们还是要构造一个DataFrame,包含两列,一列是【平均月薪】,一列是【工作城市】,然后对df4进行groupby操作,还是很简单的!不过,经过上次的教训,平均月薪一定要是数值型的,str型的计算不了。
#此处df['df_工作城市']是之前经过筛选后的30个城市数据
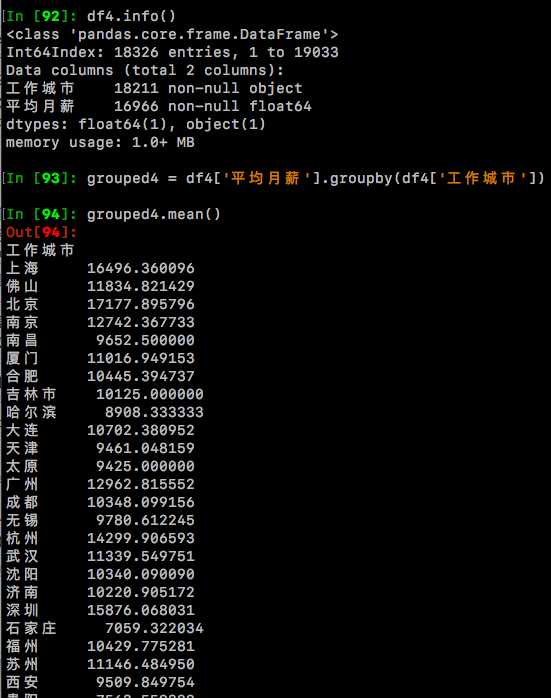
df4=pd.DataFrame(data={'工作城市':df['df_工作城市'],'平均月薪':df['df_平均月薪']})
df4.info()
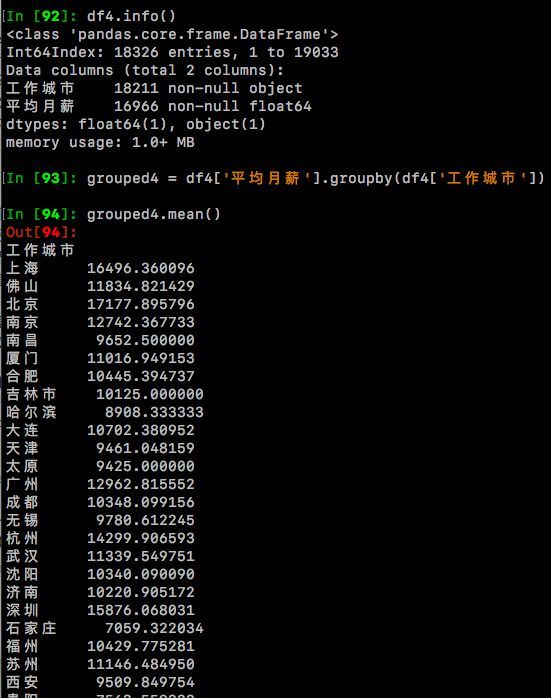
grouped4 = df4['平均月薪'].groupby(df4['工作城市'])
grouped4.mean()#查看对30个城市分组后,各个城市月薪的平均值
grouped4.count().sum()#查看对30个城市分组后筛选出的平均月薪样本数
#新增一个平均值,即所有非空df2['平均月薪']的平均值
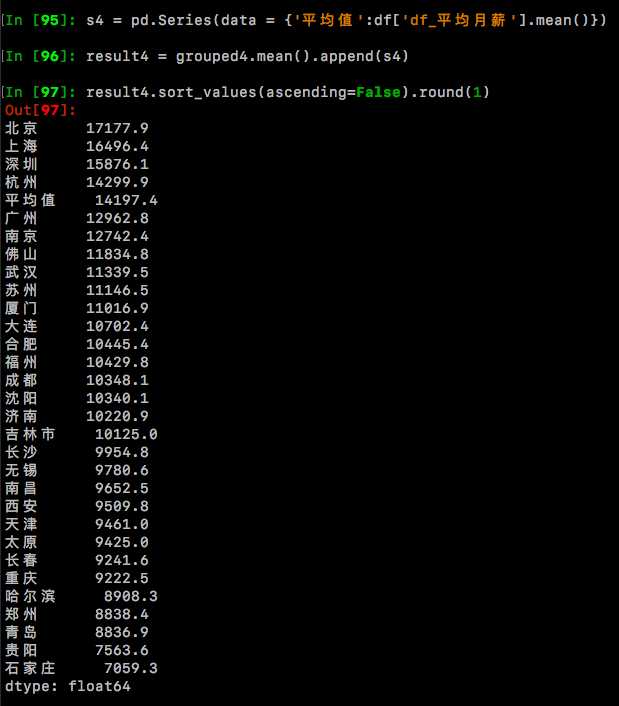
s4 = pd.Series(data = {'平均值':df['df_平均月薪'].mean()})
result4 = grouped4.mean().append(s4)
#sort_values()方法可以对值进行排序,默认按照升序,round(1)表示小数点后保留1位小数。
result4.sort_values(ascending=False).round(1)
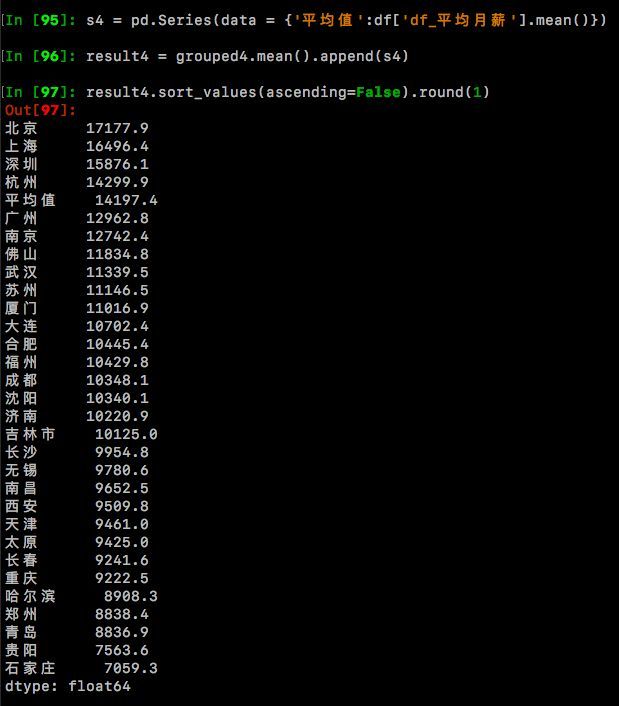
数据构造好了,进行下一步,可视化。
#可以通过style.available查看可用的绘图风格,总有一款适合你
matplotlib.style.use('dark_background')
fig4 = plt.figure(4)
ax4 = fig4.add_subplot(1,1,1)#可选facecolor='#4f4f4f',alpha=0.3,设置子图,背景色灰色,透明度0.3
result4.sort_values(ascending=False).round(1).plot(kind='bar',rot=30)#可选color='#ef9d9a'
#设置图标题,x和y轴标题
title = plt.title(u'城市——平均月薪分布图',fontsize=18,color='yellow')#设置标题
xlabel = plt.xlabel(u'城市',fontsize=14,color='yellow')#设置X轴轴标题
ylabel = plt.ylabel(u'平均月薪',fontsize=14,color='yellow')#设置Y轴轴标题
#设置说明,位置在图的右上角
text1 = ax4.text(25,16250,u'城市总数:30(个)',fontsize=12, color='#FF00FF')#设置说明,位置在图的右上角
text2 = ax4.text(25,15100,u'月薪样本数:16946(条)',fontsize=12, color='#FF00FF')
#添加每一个城市的坐标值
list_4 = result4.sort_values(ascending=False).values
for i in range(len(list_4)):
ax4.text(i-0.5,list_4[i],int(list_4[i]),color='yellow')
#设置箭头注释
arrow = plt.annotate(u'全国月薪平均值:14197元/月', xy=(4.5,14197), xytext=(7,15000),color='#9B30FF',fontsize=14,arrowprops=dict(facecolor='#FF00FF', shrink=0.05))
#设置轴刻度文字颜色为粉色
plt.tick_params(colors='pink')
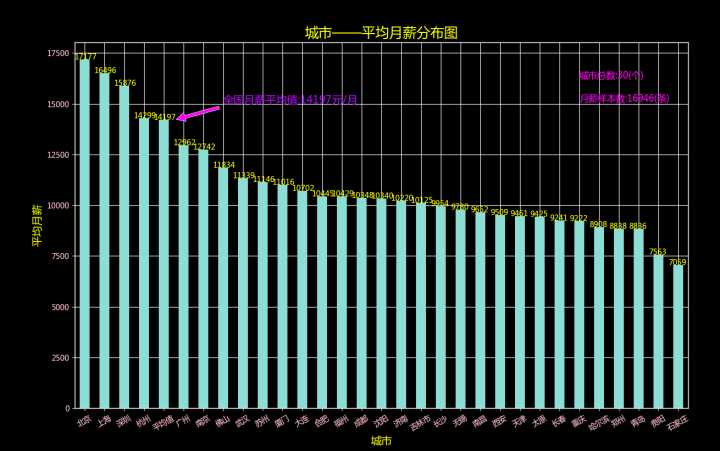
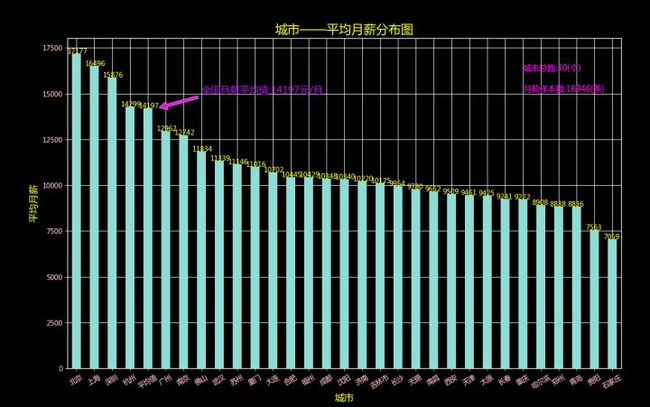
可以看见,Python这个关键词下,全国16946条样本的月薪平均值为14197元/月,平均月薪排名前5的城市分别是:北京、上海、深圳、杭州、广州。哎,记得之前城市—职位数分布图么?全国30个城市中,职位数排名前5 的也是这5座城市!看来北上广深杭不仅集中了全国大部分的职位数量、连平均工资也是领跑全国的!不禁让人觉得越大越强!但是在超级大城市奋斗,买房总是遥遥无期,房子在中国人的概念里,有着特殊的情节,意味着家,老小妻儿生活的地方,给人一种安全感!我们可以看到还有不少城市的平均月薪也破万了,在这些相对小点的城市中挑一个,工作安家,买房还是有希望的,哈哈!譬如南京、武汉、苏州、大连、厦门都挺好的!
Python学习交流圈:906407826 欢迎加入学习交流海量资料免费拿
入门、进阶、项目等资料自取