摘要:现实生活中的很多场景都会要求我们出示身份证、驾驶证、护照上的照片。一个高准确率的实时自动人证比对系统可以自动的比对身份证的照片和证件上的照片,免去很多人为的麻烦。本文中,我们通过迁移学习的技术,我们提出了一个新的方法,叫DocFace,训练一个特定领域的网络,可以用在小的认证比对的数据集上。和现有的方法进行对比,我们的方法有很大的提高。在ID-Selfies数据集上交叉验证表明DocFace可以将TAR从61.14%提高到92.77%,在FAR=0.1%上。实验表明,如果有更多的数据,就可以训练得到一个可以使用的人证比对模型。
1. 介绍
身份认证系统在日常生活中非常的重要。理想的解决方案是有一个包括了所有人的生物特征数据的数据库,但这个在大多数地方是没办法办到的。一个比较实际的解决方案是使用身份证照片和生活照进行比对。这种场景很多,往往是通过人工来进行比对的,耗时耗力,而且容易出错。因此,高准确率和实时的人证比对系统有着广阔的前景。
人证比对的难点和普通的人脸识别的难点不同,普通的人脸识别的难点在于图片采集的非限制性,人脸的姿态、光照和表情各不相同。但是对于人证比对来说,对比的是身份证的照片和采集的生活照,在采集生活照的时候,人通常是配合的,所以,是限制场景的照片采集,不会有太多的多样性,难点在于身份证照片的质量一般很差,而身份证照片和生活照的年龄差距一般会比较大,如下图。还有个难点在于,现在的人脸识别的方法一般使用深度神经网络,这就需要大量的数据,而人证比对的场景往往很难收集到大量的数据。

在本文中,我们先介绍了已有的业界领先的人证比对的模型,然后我们提出了DocFace,使用迁移学习到特定领域进行人证的比对。我们使用了两个中国身份证的数据集对商用人脸比对器,开源人脸比对器和我们提出的方法进行对比。主要的贡献总结如下:
使用公开的人脸识别器对人证比对问题进行评估
一个学习异构人脸对的特征表的的新的系统和损失函数
一个针对特定领域的比对器,叫做DocFace,解决人证比对问题,显著的提升了已有的比对模型的能力,在中国的身份证数据集上TAR从61.4%提升到了92.77%,在FAR=0.1%下。
2. 相关的工作
2.1 人证比对
这部分主要讲的是一些传统的比对方法,需要手工提取特征。
2.2 深度学习人脸识别
在深度学习中,浅层的特征是可以迁移的,并不限制与特定的数据集中,利用这个特点,我们可以在大的数据集上训练显著的浅层的特征,然后迁移到特定的小的数据集上。
3. 数据集
这部分我们简单的介绍一下我们用到的数据集。见下图:

3.1 MS-Celeb-1M
这个数据集是公开的,包括8,456,240张图片,99,892个不同的人,大部分从网上下载,在我们的迁移学习框架中,这个数据集作为源领域,用来训练深度网络的丰富的浅层特征。然而,这个数据集有很多的噪声,我们使用的是清理过的数据集,共有5,041,527张图像,98,687个人。
3.2 ID-Selfie-A数据集
我们的第一个人证比对数据集,是私有的数据集。共有10000对身份证照片和生活照片,身份证照片是从身份证芯片中读取到的,生活照片是固定的相机上采集的。对齐之后,剩下9915对,一共19830张照片。假设所有的参与者都是配合的,那应该是没有注册失败的案例,我们将所有的对齐后的数据作为我们的数据集。这个数据集是我们的迁移学习的目标域,在实验中,我们把数据分为两部分,一部分为训练集,一部分为测试集。
3.3 ID-Selfie-B数据集
我们的第二个人证比对数据集也是个私有的数据集,有10844张照片,547个人,每个人包括1张身份证照片和几张自拍照片,这些自拍照片是不同的设备采集的,包括手机。相比于ID-Selfie-A,这个数据集受的限制更少,有些图像被压缩过,有些经过了滤波的处理。经过清理之后,我们剩下了10806张照片,537个人。我们使用这个数据集进行交叉验证。数据集A和数据集B中的人是没有重复的。
4. 方法
4.1 符号说明
使用迁移学习的框架,首先我们在源数据集上训练一个基准模型,然后将特征迁移到目标域。为源数据集,其中并且是第i张图像的标签,h和w是图像的高和宽,是图像的数量,是类别的数量。目标领域的训练数据集表示为,其中,表示第i个人的身份证照和自拍照,是图像对的数量。函数表示源领域从图像到特征的映射,同样的,表示从身份证图像到特征的映射,表示从自拍图像到特征的映射。见下图:
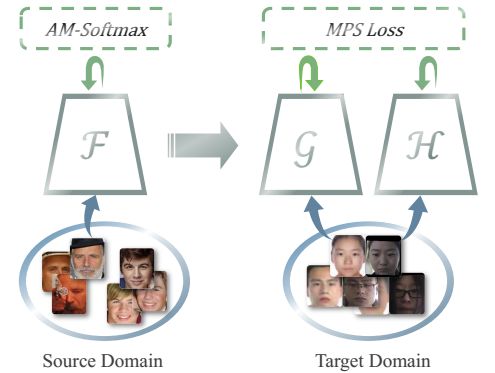
4.2 在源领域上训练
我们使用MS-Celeb-1M数据集进行训练,采用的网络结构是流行的Face-ResNet结构,我们使用了AM-softmax的loss进行训练,对于每一个minibatch里面的训练样本,损失函数定义为:
其中,
其中是权值矩阵,m是超参数。s可以自己设置,也可以通过学习得到,在这里,我们通过学习得到。
4.3 在目标领域上训练
目标领域是一个相对小的数据集。源领域和目标领域的图像的差别是很大的,直接使用效果是不好的。我们需要将两个不同领域的人脸映射到同一个嵌入空间。我们使用一对姐妹网络和,共享相同的网络结构,但是使用不同的参数。特征都是从中迁移过来的,具有相同的初始值。这样虽然模型变大了,但是推理时间并没有变长,不同的图像被送进不同的网络,可以同时进行。
受到最近的度量学习的方法的启发,我们提出了Max-margin Pairwise Score(MPS)的损失来训练异构的人脸对数据集。对于每一个mini-batch,有M个样本,M/2个身份证-自拍照对是从总的数据集中随机抽取得到的。对于每对图像,MPS的损失表示为:
其中
损失函数在M/2个图像对上做平均,j表示遍历所有其他的batch中的人,。超参数和AM-Softmax中的m类似。MPS的思想是最大化真实人脸对和虚假人脸对之间的相似度的差别。MPS模拟了这样一个场景,其中身份证照片就像是模板,来自不同人的自拍照就像是测试样本,用来比对。通过选取最大的相似度得到最难的那个虚假样本,MPS就好像是Triplet Loss一样,身份证/自拍照就像是anchor。
5. 实验
5.1 实验设置
我们所有的实验使用的是Tensorflow r1.2。我们再MS-Celeb-1M上训练基础模型,我们使用256的batch size,训练了280K个迭代。开始的学习率是0.1,然后160K迭代的时候,减少到0.01,240K迭代的时候,减少到0.001。finetune的时候,在ID-Selfie-A的数据集上进行,batch size为256,训练姐妹网络800个迭代。开始的学习率为0.01,500个迭代之后学习率减少为0.001。优化器采用SGD,momentum为0.9,weight decay为5e-4。所有的图像通过MTCNN进行对齐,缩放到96×112。margin的设置分别为m=5.0,m‘=0.5。
通过MS-Celeb-1M,我们使用AM-Softmax,在LFW上得到的准确率为99.67%,验证准确率99.60%,FAR为0.1%。
我们将这种方法命名为DocFace,我们设计了几种探索性的实验,来对比不同的方法,验证了我们的方法的有效性。然后对比了DocFace和已有的几种人脸比对器在ID-Selfie-A的数据集上的表现。通过在不同的ID-Selfie-A子数据集上的训练,我们发现,性能随着数据量的增加稳定的提升,最后,我们再整个的ID-Selfie-A数据集上训练了一个模型,然后在ID-Selfie-B上进行了交叉验证。
所有的在ID-Selfie-A上的实验,都是使用5折交叉验证的方式进行评估的,整个数据集平均分成5份,拿其中4份进行训练,另外一份进行测试。我们使用全部的ID-Selfie-B进行交叉数据验证,使用余弦距离作为相似度的评分。
5.2 探索实验
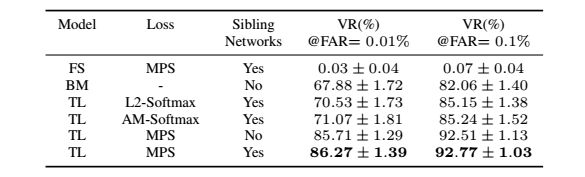
这部分我们使用ID-Selfie-A数据集,对比了不同的方法进行人证比对,首先对比了不使用迁移学习的方法(1)直接从头训练同样结构的网络,使用MPS损失函数(2)使用在MS-Celeb-1M的预训练模型。为了验证MPS损失函数的有效性,我们使用了两种方法进行finetune,L2-Softmax和AM-Softmax。最后使用基准模型和MPS损失函数,我们对比了姐妹网络的不同的参数设置。
结果显示再下面的表格中,由于ID-Selfie-A的数据集很小,从头开始训练,很容易就过拟合了,所以再测试集上表现很差。相比之下,基准模型表现就好的多。这个表明了学到的特征是可以迁移过来用到小的数据集上的。通过迁移学习之后,性能进一步提升。尽管使用L2-Softmax和AM-Softmax得到的结果已经很好了,我们提出的MPS损失比预训练模型提升的更多,这是由于我们的这个loss是专门为这个问题设计的。最后,我们发现,使用一对姐妹网络,可以小幅的提升能力,这表明,不同类型的图像使用不同的网络,可以学到不同的底层特征,可以得到更加有区分性的特征。
5.3 和已有的比对器的比较
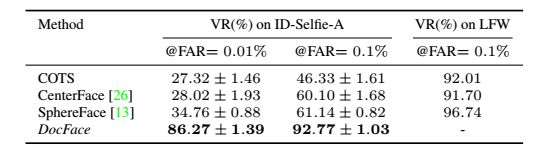
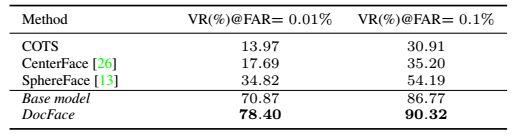
我们和通用的人脸比对器进行了比较,除了COTS的比对器外,还包括Center-Face,SphereFace,比较的结果如下表:
我们还列出了一些false accept和false reject的样本,如下,可以看到,false accept的样本由于图像质量较差,看起来都是很像的,而false reject的样本,由于化妆和年龄的差别,导致了差别有点大。

5.4 数据集大小的影响
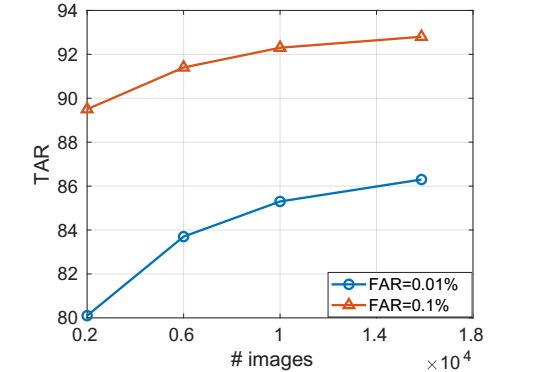
我们选取了1000,3000,5000和所有的(7932)对数据来进行训练,结果如下:
5.5 交叉数据集的评估
尽管自拍照是通过固定的摄像头采集的,在很多场景下,自拍照也可能通过其他的一些设备采集,一个理想的模型应该是可以在各种场景下都表现的比较鲁棒。因此,我们在ID-Selfie-A上训练模型,再ID-Selfie-B上进行测试,ID-Selfie-B中,每个人可能有多张自拍照,我们将所有的特征拿来做个平均。结果如下:
6 总结
本文中,我们提出了一个新的方法,DocFace,使用迁移学习的方法,使用一个新的loss,MPS的loss,finetune一对姐妹网络。通过两个私有数据集进行了评估,并对比了不同的方法。实验表明,我们的方法比以后的方法有较大的提升,我们还发现,增大数据集,性能能够稳步的提升。
本文可以任意转载,转载时请注明作者及原文地址。
