参考:https://www.cnblogs.com/li0803/archive/2008/11/03/1324746.html
- HTTP通解
- 基本认证
- 压缩
- 缓存
- 代理
- 状态码
- Cookie
其余问题:
- 浏览器是如何缓存的?
2.If-Modified-Since和If-None-Match的使用场景区别。
URL
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
- 协议名(
http):,http、https、FTP等,后面跟着://。 - 域名(
www.aspxfans.com):也可以用IP作为域名。 - 端口(
8080):若省略,即为默认80端口, https默认443。 - 虚拟目录(
/news/): - 文件名部分(
index.asp):从最后一个/到?或#,若省略,即为默认文件名。 - 锚(
name): - 参数(
boardID=5&ID=24618&page=1):从“?”开始到“#”为止之间的部分。
- 为何要引入cookie?因为HTTP是无状态的,服务器并不知道俩个不同的请求是否是来自同一个客户端。


请求行(Request Line)
- 请求方法(Method):GET、POST
- 请求统一资源标识符(URI):URI就是URL中排除掉Host剩下的部分,也就是资源在服务器本地上的路径。
- HTTP版本号:目前主流版本是1.1(1999年采用),最新版本是2.0(2015年5月发布)。
请求头(Request Header)
主要存放对客户端想给服务端的附加信息。
Host: 目标服务器的网络地址Accept: 让服务端知道客户端所能接收的数据类型,如text/html也就是我们常说的html文档 、*/*表示可以处理任何类型。Content-Type: body中的数据类型,如application/json; charset=UTF-8Accept-Language: 客户端的语言环境,如zh-cnAccept-Encoding: 客户端支持的数据压缩格式,如gzipUser-Agent: 客户端的软件环境,我们可以更改该字段为自己客户端的名字,比如QQ music v1.11,比如浏览器Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/600.8.9 (KHTML, like Gecko) Maxthon/4.5.2Connection: keep-alive,该字段是从HTTP 1.1才开始有的,用来告诉服务端这是一个持久连接,“请服务端不要在发出响应后立即断开TCP连接”。关于该字段的更多解释将在后面的HTTP版本简介中展开。Content-Length: body的长度,如果body为空则该字段值为0。该字段一般在POST请求中才会有。
POST请求的body请求体也有可能是空的,因此POST中Content-Length也有可能为0Cookie: 记录者用户信息的保存在本地的用户数据,如果有会被自动附上。-
if-Modified-since: 浏览器缓存最后修改时间。发送给服务器,服务器会把这个时间跟服务区上的最后修改时间(Last-Modified)对比,若一样,则返回304,直接用缓存,不一样则返回200,并返回新的数据,然后更新浏览器本地的if-Modified-since。
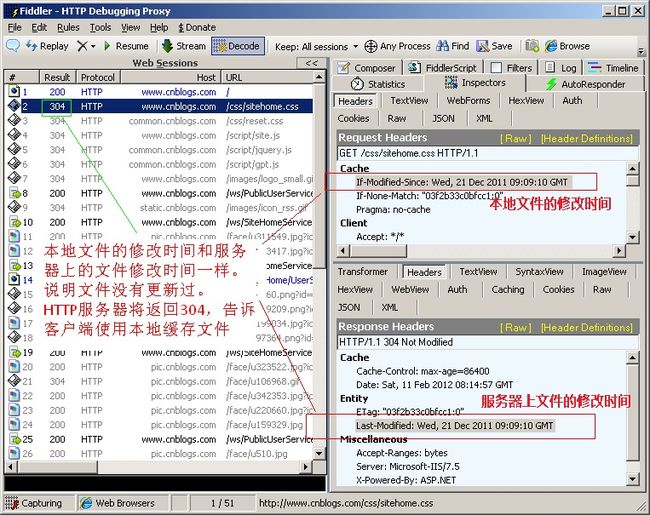
-
if-none-match: 和ETag一起工作,原理是在Response中添加ETag信息,浏览器再次请求该资源时,把if-none-match发送给服务器,服务器拿着个和文件的ETag对比,若两者相同返回304,然后直接用缓存显示。若两者不同说明文件有更新,返回200和新的ETag,然后浏览器保存为新的if-none-match。
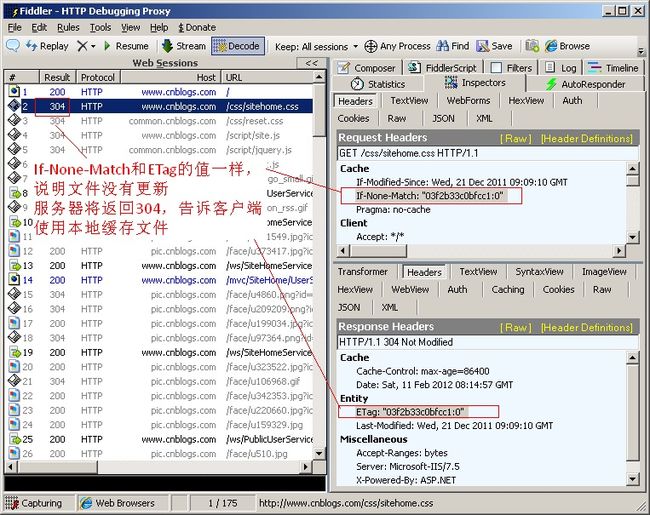
Pragma: 作用是防止页面被缓存,在HTTP/1.1中,它和Cache-Control:no-cache作用一样。Cache-Control:用来制定Response-Request遵循的缓存机制。
Cache-Control: Public:可以被任何缓存所缓存
Cache-Control: Private:只缓存到私有缓存中
Cache-Control: no-cache:所有内容都不会被缓存
请求体(Request Body)
需要传给服务端的数据。
- GET请求中body就为空。
- POST请求中上传文件body就是二进制,普通请求就是一些表单数据。
响应状态行(Response Line)

- 版本号:
HTTP/1.1 - 状态码:
200 - 状态码英文名称:
OK
状态码种类:
- 1XX:信息提示。不代表成功或者失败,表示临时响应,比如100表示继续,101表示切换协议
- 2XX: 成功
- 3XX: 重定向
- 4XX:客户端错误,很有可能是客户端发生问题,如亲切可爱的404表示未找到文件,说明你的URI是有问题的,服务器机子上该目录是没有该文件的;414URI太长
- 5XX: 服务器错误,比如504网关超时
响应头与响应实体
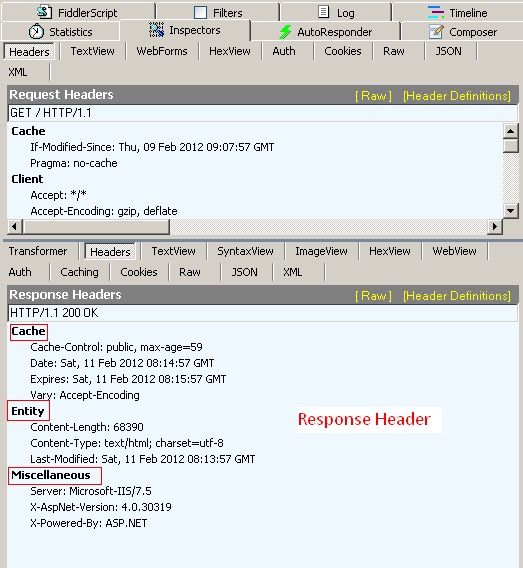
这两部分与请求部分差异不大。
- 响应头:包含了对服务器的描述、对返回数据的描述。
Server: Apache-Coyote/1.1 // 服务器的类型。Content-Type: image/jpeg // 返回数据的类型Content-Length: 56811 // 返回数据的长度Date: Mon, 23 Jun 2014 12:54:52 GMT // 响应的时间Expires: 过期时间,浏览器会在制定的过期时间内使用本地缓存。ETag:和 if-none-match 配合使用。Last-Modified:资源最后修改时间,和if-modified-since配合使用。Content-Encoding:服务器使用什么压缩方法(gzip, deflate)压缩响应中的对象。X-powered-by:网站用什么技术开发的,如:X-powered-by:ASP.NET。Connection:例如,Connection : keep-alive当一个网页打开完成后,客户端和服务器间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这条已经建立的连接,当然不关闭也会有个时间限制,不会永久保持连接。再如,Connection : close表示一个Request完成后,客户端和服务器之间的TCP连接会guanbi,当客户端再次发送Request时,需要重新建立TCP连接。Set-Cookie:服务器把cookie发送给浏览器,没写入一个cookie都会生成一个Set-Cookie。

HTTP版本简介
这里我把HTTP版本简单分为三类:1.1之前,1.1,2.0,针对这三类做个主要差异的介绍:
HTTP 1.1之前
- 不支持持久连接。一旦服务器对客户端发出响应就立即断开TCP连接
- 无请求头跟响应头
- 客户端的前后请求是同步的。下一个请求必须等上一个请求从服务端拿到响应后才能发出,有点类似多线程的同步机制。
HTTP 1.1(主流版本)
与1.1之前的版本相比,做了以下性能上的提升。
- 增加请求头跟响应头
- 支持持久连接。客户端通过请求头中指定Connection为keep-alive告知服务端不要在完成响应后立即释放连接。HTTP是基于TCP的,在HTTP 1.1中一次TCP连接可以处理多次HTTP请求
- 客户端不同请求之间是异步的。下一个请求不必等到上一个请求回来后再发出,而可以连续发出请求,有点类似多线程的异步处理。
HTTP 2.0
本着向下兼容的原则,1.1版本有的特性2.0都具备,也使用相同的API。但是2.0将只用于https网址。由于2.0的普及还需要比较长的一段时间,这里不展开。
我们重点关注一下当前1.1版本所做几点改变。支持持久连接有什么好处呢?HTTP是基于TCP连接的,如果连接被频繁地启动然后断开就会花费很多资源在TCP三次握手以及四次挥手上,效率低下。以请求一个网页为例,我们知道,一个html网页上的图片资源并不是直接嵌入在网页上,而只是提供url,图片仍需要额外发HTTP 请求去下载。一个网页从请求到最终加载到本地往往需要经过过个HTTP请求。在1.1版本之前请求一个网页就需要发生多次"握手-挥手"的过程,每次连接之间相互独立;而1.1及之后的版本最少只需要一次就够。
再来就是请求异步,其好处参考多线程异步处理,在此不展开。
以上特性可以用图2.3表示:
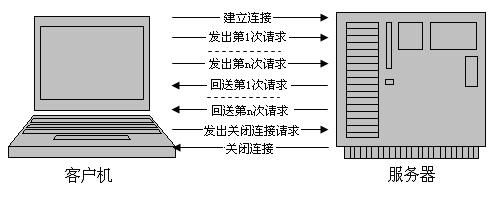
我们可以看到:1、N次请求其实只建立了1次TCP连接,2、N次请求连续异步发出。
HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。
2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
1、浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2、解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
3、浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
4、服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5、释放 TCP连接;
6、浏览器将该 html 文本并显示内容;
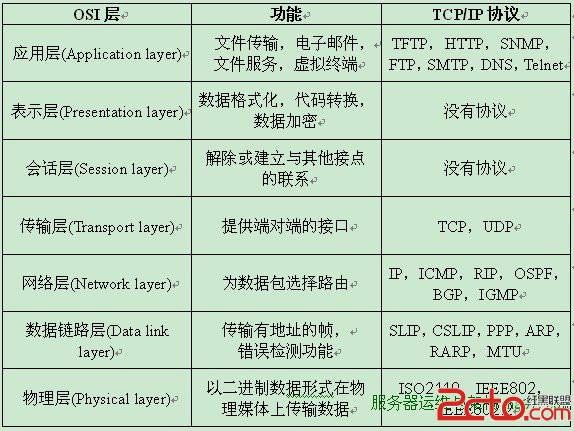
OSI七层模型
HTTP、Socket、TCP的区别
这三个概念经常被谈到,也是比较容易被混掉的概念。在回顾之前我们先看一下这三者在TCP/IP协议族中的位置关系:
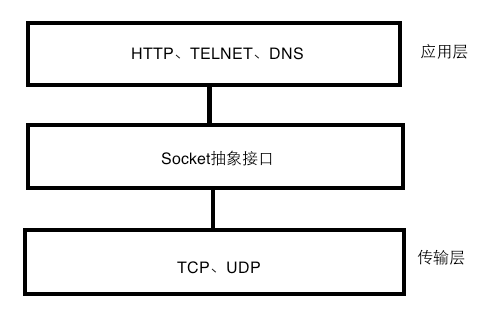
HTTP是应用层的协议,更靠近用户端;TCP是传输层的协议;而socket是从传输层上抽象出来的一个抽象层,本质是接口。所以本质上三种还是很好区分的。尽管如此,有时候你可能会懵逼,HTTP连接、TCP连接、socket连接有什么区别?好吧,如果上面的图解释的还是不够清楚的话,我们继续往下看。
- TCP连接与HTTP连接的区别
上文提过,HTTP是基于TCP的,客户端往服务端发送一个HTTP请求时第一步就是要建立与服务端的TCP连接,也就是先三次握手,“你好,你好,你好”。从HTTP 1.1开始支持持久连接,也就是一次TCP连接可以发送多次的HTTP请求。
小总结:HTTP基于TCP
- TCP连接与Socket连接的区别
在图4.1中我们提到,socket层只是在TCP/UDP传输层上做的一个抽象接口层,因此一个socket连接可以基于TCP,也有可能基于UDP。基于TCP协议的socket连接同样需要通过三次握手建立连接,是可靠的;基于UDP协议的socket连接不需要建立连接的过程,不过对方能不能收到都会发送过去,是不可靠的,大多数的即时通讯IM都是后者。
小总结:Socket也可以基于TCP
- HTTP连接与Socket连接的区别
区分这两个概念是比较有意义的,毕竟TCP看不见摸不着,HTTP与Socket是实实在在能用到的。
- HTTP是短连接,Socket(基于TCP协议的)是长连接。尽管HTTP1.1开始支持持久连接,但仍无法保证始终连接。而Socket连接一旦建立TCP三次握手,除非一方主动断开,否则连接状态一直保持。
- HTTP连接服务端无法主动发消息,Socket连接双方请求的发送先后限制。这点就比较重要了,因为它将决定二者分别适合应用在什么场景下。HTTP采用“请求-响应”机制,在客户端还没发送消息给服务端前,服务端无法推送消息给客户端。必须满足客户端发送消息在前,服务端回复在后。Socket连接双方类似peer2peer的关系,一方随时可以向另一方喊话。
4、问题来了:什么时候该用HTTP,什么时候该用socket
- 这个问题的提出是很自然而然的。当你接到一个与另一方的网络通讯需求,自然会考虑用HTTP还是用Socket。
- 用HTTP的情况:双方不需要时刻保持连接在线,比如客户端资源的获取、文件上传等
- 用Socket的情况:大部分即时通讯应用(QQ、微信)、聊天室、苹果APNs等
cookie和session的区别
cookie:HTTP是无状态的,服务器无法判断两个请求是否是来自同一客户点,需要借助cookie。cookie分为会话cookie和持久cookie。cookie是浏览器生成的。
- 两个都可以用来存私密的东西,同样也都有有效期的说法,区别在于session是放在服务器上的,过期与否取决于服务期的设定,cookie是存在客户端的,过去与否可以在cookie生成的时候设置进去。
- cookie数据存放在客户的浏览器上,session数据放在服务器上
- cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE
- 单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K。
- 所以:将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
- 如果web服务器端使用的是session,那么所有的数据都保存在服务器上,客户端每次请求服务器的时候会发送当前会话的sessionid,服务器根据当前sessionid判断相应的用户数据标志,以确定用户是否登录或具有某种权限。由于数据是存储在服务器上面,所以你不能伪造,但是如果你能够获取某个登录用户的 sessionid,用特殊的浏览器伪造该用户的请求也是能够成功的。sessionid是服务器和客户端链接时候随机分配的,一般来说是不会有重复,但如果有大量的并发请求,也不是没有重复的可能性.
- 如果浏览器使用的是cookie,那么所有的数据都保存在浏览器端,比如你登录以后,服务器设置了cookie用户名,那么当你再次请求服务器的时候,浏览器会将用户名一块发送给服务器,这些变量有一定的特殊标记。服务器会解释为cookie变量,所以只要不关闭浏览器,那么cookie变量一直是有效的,所以能够保证长时间不掉线。如果你能够截获某个用户的 cookie变量,然后伪造一个数据包发送过去,那么服务器还是认为你是合法的。所以,使用 cookie被攻击的可能性比较大。如果设置了的有效时间,那么它会将 cookie保存在客户端的硬盘上,下次再访问该网站的时候,浏览器先检查有没有 cookie,如果有的话,就读取该 cookie,然后发送给服务器。如果你在机器上面保存了某个论坛 cookie,有效期是一年,如果有人入侵你的机器,将你的 cookie拷走,然后放在他的浏览器的目录下面,那么他登录该网站的时候就是用你的的身份登录的。所以 cookie是可以伪造的。当然,伪造的时候需要主意,直接copy cookie文件到 cookie目录,浏览器是不认的,他有一个index.dat文件,存储了 cookie文件的建立时间,以及是否有修改,所以你必须先要有该网站的 cookie文件,并且要从保证时间上骗过浏览器。
TCP的三次握手
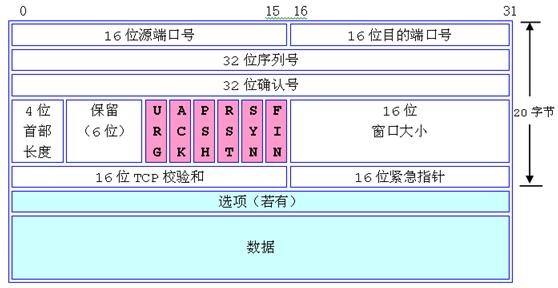
相关概念:6位标志域的各个选项功能如下:
- URG:紧急标志。紧急标志为"1"表明该位有效。
- ACK:确认标志。表明确认编号栏有效。大多数情况下该标志位是置位的。TCP报头内的确认编号栏内包含的确认编号(w+1)为下一个预期的序列编号,同时提示远端系统已经成功接收所有数据。
- PSH:推标志。该标志置位时,接收端不将该数据进行队列处理,而是尽可能快地将数据转由应用处理。在处理Telnet或rlogin等交互模式的连接时,该标志总是置位的。
- RST:复位标志。用于复位相应的TCP连接。
- SYN:同步标志。表明同步序列编号栏有效。该标志仅在三次握手建立TCP连接时有效。它提示TCP连接的服务端检查序列编号,该序列编号为TCP连接初始端(一般是客户端)的初始序列编号。在这里,可以把TCP序列编号看作是一个范围从0到4,294,967,295的32位计数器。通过TCP连接交换的数据中每一个字节都经过序列编号。在TCP报头中的序列编号栏包括了TCP分段中第一个字节的序列编号。
- FIN:结束标志。
- 32位序列号 seq:表示的是本次报文发送的数据的第一个字节的序号。
- 32位确认号:ack 表示期望下一次应该接受到的报文的第一个字节的序号,若ack = N则表示,到序号N-1为止的所有的数据都已经正确的收到了。
- ACK位(图中红色部分,用ACK大写表示ACK位,ack小写表示确认号):确认,当ACK = 1是确认号ack才有效,建立连接后,所有传送的报文段都必须把ACK置为1.
- SYN位(图中红色部分):同部位,在建立连接的时候使用,若SYN=1,ACK=0,则表示是一个连接请求报文,若接收方同意接收连接,则使用SYN = 1,ACK = 1。所以,从上面可以看出来SYN = 1表示这个报文是一个连接请求或连接接收报文。
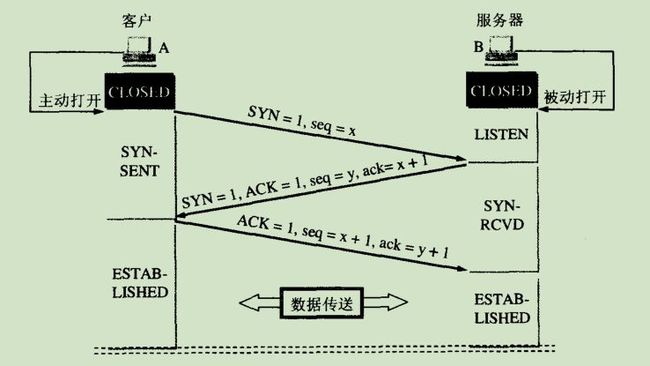
- A发送连接请求:A发送连接请求时,将SYN置为1,ACK置为0,seq取一个数x,ack取0(因为ACK为0,所以这个时候ack取值没有意义),这个过程将消耗一个序号。
- B确认连接:若B同意A请求连接,则B发送的报文中,SYN = 1,ACK = 1,seq取一个数字y,ack取x +1,这个过程将消耗一个序号。seq取y和前面的过程没有关系,ack取x+1是因为,A发送的数据seq为x,并且在发送的过程当中消耗了一个序号,所以,下一次应该收到的数据的地址为x+1,加的1就是消耗的一个序号。
- A确认:A需要再次确认,SYN = 0,ACK = 1, seq = x + 1, ack = y + 1。 seq表示发送的数据的序号为x + 1,同时希望B下一次发送的数据的序号为y + 1。
三次握手的另一个博客描述:
- 第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
- 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
- 第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
简单来说,就是
- 建立连接时,客户端发送SYN包(SYN=i)到服务器,并进入到SYN-SEND状态,等待服务器确认。
- 服务器收到SYN包,必须确认客户的SYN(ack=i+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器进入SYN-RECV状态。
- 客户端收到服务器的SYN+ACK包,向服务器发送确认报ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手,客户端与服务器开始传送数据。
- 在三次握手的时候,有四个字段是非常重要的。SYN和ACK均占一位,表示同步和确认。seq和ack均为32位,分别为发送的数据的序号,和希望对方发送的数据的序号。
- 在三次握手的过程中,第一次和第二次的过程中SYN的值均为1,并且每个过程都消耗掉一个序号,消耗一个序号的意思是:使得数据的序号加1,好像是发送了一位数据,但是并没有真正的传递数据。
为啥是三次握手不是两次?

SYN攻击:
在三次握手过程中,Server发送SYN+ACK之后,收到Client的ACK之前的TCP连接称为半连接(half-open connect),此时Server处于SYN_RCVD状态,当收到ACK后,Server转入ESTABLISHED状态。SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server回复确认包,并等待Client的确认,由于源地址是不存在的,因此,Server需要不断重发直至超时,这些伪造的SYN包将产时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络堵塞甚至系统瘫痪。SYN攻击时一种典型的DDOS攻击,检测SYN攻击的方式非常简单,即当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行:
netstat -nap | grep SYN_RECV
TCP的四次挥手
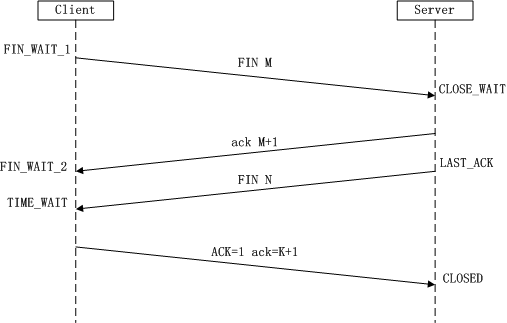
为啥连接时是三次,挥手却是四次?

因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。