虚拟内存概念
linux内核给每个进程都提供了一个独立的连续的虚拟地址空间。进程访问虚拟内存地址时不需要考虑会不会跟其他进程冲突,操作系统负责将每个进程的虚拟内存映射到物理内存。
虚拟内存布局
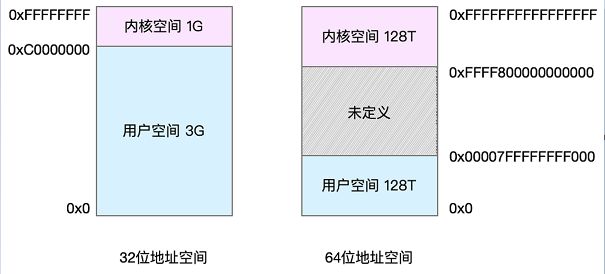
32位系统内核空间占用1G,位于最高处,用户空间占用3G。64位系统内核空间和用户空间各占128T,中间部分未定义。进程在用户态时,只能访问用户空间的内存,进程在内核态时,只能访问内核空间的内存。
每个进程的用户空间是隔离的(用户空间的虚拟地址映射到不同的物理地址),但是每个进程的内核空间都是一样的(用户空间的虚拟地址映射到相同的物理地址),虽然每个进程的内核栈都是独立的,但是如果知道其他进程内核栈的地址,仍然是可以访问的。所以在内核态,如果要访问公共的数据结构,需要加锁保护。
内存映射
操作系统把物理内存分成一块一块大小相同的页,这样更方便管理。页面的大小一般为4k。页表中记录了虚拟页号和物理页号的对应关系。将一个虚拟地址分成两部分:一部分存储虚拟页号,一部分存储页内的偏移量。这样虚拟地址通过查询页表可以获得物理页号,再根据偏移量就可以找到映射的物理地址。

多级页表和大页
32位环境下,虚拟地址空间总共4GB,如果4KB一个页,总共需要1M个页,每个页表项需要4个字节来存储。那么总共需要4MB的内存来存储页表。
这4MB页表项必须提前创建好,并且要求是连续的。为什么有这个要求?为了支持快速查找虚拟页号到物理页号的对应关系,页表采用了数组这样的数据结构来存储,数组的下标就是虚拟页号,值为物理页号。
如果有100个进程,就需要400M的内存,上边提到过,内核空间只有1GB,400MB对于内核来说太大了。
如何解决这个问题呢?第一个方法是采取多级页表,我们将这4MB的页表继续划分,分成1024个4KB,这1024个页也需要一个表进行管理,称为页目录表。这个页目录表里有1024项,每项4个字节,页目录表的大小为4KB
32位的虚拟地址如下图所示,根据前10位定位到页目录,再根据中间的10位定位页表,获取到物理页号,根据页内偏移量来定位到物理地址

多级页表是如何节省内存的?假设我们给进程分配一个数据页,如果只使用页表,需要1M个页表项共计4MB的空间来存储页表。如果使用页目录,页目录表需要4KB的空间来存储,里边只有一项使用了,页表,只需要分配那一个数据页的页表项就可以了,总共8KB的内存
对于64位系统,两级页表是不够的。64位需要四级目录,分别是:全局页目录项PGD、上层页目录项PUD、中间页目录项PMD、页表项PTE
再来看大页,大页就是比普通页更大的内存块,常见的大小有2MB和1GB,采用大页后,页表项会显著减少,大大降低TLB miss的概率。可以为单独的应用设置大页,比如基于dpdk开发的应用。
页表的存储位置
页表和task_struct都存储在内核空间
MMU和TLB
MMU是cpu的内存管理单元,cpu执行单元发出的内存地址(虚拟地址)将会被MMU截获,MMU将虚拟地址翻译成物理地址,然后将物理地址发到CPU芯片的外部地址引脚上。
MMU地址翻译的过程:
1 操作系统在初始化或分配、释放内存时会执行一些指令在物理内存中填写页表,然后用指令设置mmu,告诉mmu页表在物理内存中的具体位置
2 cpu访问虚拟地址时,自动触发mmu做查表和地址转换的操作,地址转换操作有硬件完成,不需要指令控制mmu
页表一般都很大,只能放在内存中。每次访问虚拟地址,都需要先访问内存。为了提高映射速度,引入了TLB(快表)。TLB存储的数据比较少,但是速度比内存快的多。TLB就是页表的缓存。通过减少TLB miss,可以大幅提高cpu访问内存的性能。
用户态虚拟空间布局
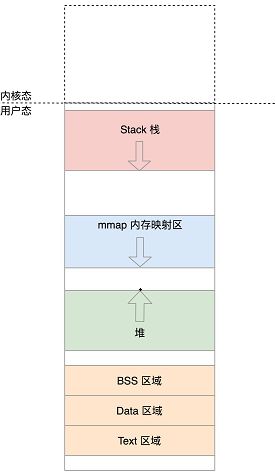
mm_struct结构
操作系统通过进程控制块task_struct中的mm_struct来管理内存,mm_struct中通过以下这些变量来记录内存区域的统计信息和具体位置
unsigned long mmap_base; /* mmap映射的起始地址 */
unsigned long total_vm; /* 总共映射的页的数目 */
unsigned long locked_vm; /* 被锁定不能换出的页的数目 */
unsigned long pinned_vm; /* 不能换出,也不能移动的页的数目 */
unsigned long data_vm; /* 存放数据的页的数目 */
unsigned long exec_vm; /* 存放可执行文件的页的数目 */
unsigned long stack_vm; /* 栈占用的页的数目 */
unsigned long start_code, end_code, start_data, end_data; /* 代码段起始、结束地址,已经初始化的数据段起始、结束地址 */
unsigned long start_brk, brk, start_stack; /*堆的起始地址、堆的结束地址、栈的起始地址*/
unsigned long arg_start, arg_end, env_start, env_end; /* 参数的起始、结束地址,环境变量的起始、结束地址,都位于栈中最高地址的地方 */
除了这些位置信息和统计信息之外,mm_struct里面还专门有一个结构vm_area_struct,来描述这些区域的属性。
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
mmap是双向链表,mm_rb是红黑树
vm_area_struct 结构如下:
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
struct mm_struct *vm_mm; /* The address space we belong to. */
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
} __randomize_layout;
其中vm_start和vm_end指定了该区域在用户空间中的起始地址和结束地址。vm_next和vm_prev将这个结构串在链表上。vm_rb将这个区域加到红黑树上,vm_ops是对这个区域可以做的操作的定义。anon_vma不为空时,表示这块虚拟内存映射的是物理内存。vm_file不为空时,表示虚拟内存映射的是文件
vm_area_struct映射过程
load_elf_binary会初始化内存映射
1 设置内存映射区mmap_base
2 设置栈的vm_area_struct
3 设置arg_start指向栈底,
4 设置代码段、数据段、bss段的vm_area_struct,将elf中的代码、已初始化的全局遍历和未初始化的全局变量映射到内存中来
5 设置堆的vm_area_struct,这时start_brk和brk相等,堆中是空的
6 设置mmap动态映射区的vm_area_struct,load_elf_interp将依赖的so映射到内存
内存的分配与回收
malloc()是c标准库函数提供的内存分配函数,对于小于128k的小块内存,用brk()来分配,对于大于128k的大块内存,用mmap来分配。brk()方式通过移动堆顶的位置来分配内存,内存释放的时候并不会立刻归还给操作系统(只有当brk指针下有连续的内存后才缩小brk指针,释放内存),因此brk()方式的优点是可以减少缺页异常的发生,缺点是会造成内存碎片。mmap()方式分配内存会在释放时直接归还给操作系统,优点是不会造成内存碎片,缺点是每次mmap都会发生缺页异常。
另外需要注意的一点是,这两种调用发生后,并没有真正的分配内存(brk没有可复用的内存时,会分配新的页,mmap每次都分配新的页),在首次访问内存时,通过缺页异常,由内核来分配内存
brk处理过程
1 根据申请内存的大小,计算出新的堆顶的位置
2 将新的堆顶和原来的堆顶按页对齐,比较大小,如果两者相同,说明这次增加的内存很小,还在一个页面里,不需要分配新页。直接设置mm->brk为新的堆顶即可
3 如果新旧堆顶不在一个页面里,就需要调用find_vma,这个函数是对红黑树的查找,找原堆顶所在的vm_area_struct的下一个vm_area_struct,查看当前堆顶和下一个vm_area_struct之间是否还能分配所需的页,如果不能,退出返回内存空间满。如果还有空间,调用do_brk分配所需的页数。
mmap处理过程
每个进程都有一个vm_area_struct列表,这个变量的名称就是mmap
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
......
}
内存映射不仅仅是物理内存和虚拟内存之间的映射(匿名映射),还包括将文件中的内容映射到虚拟地址空间。仅有物理内存和虚拟内存的映射是一种特殊情况。
mmap处理过程如下:
1 根据fd的值(匿名映射为-1)和flag(MAP_SHARE|MAP_ANON)来确定是否为匿名映射
2 调用get_unmapped_area 函数找到一个还没有映射的区域
3 创建一个新的vm_area_struct对象,将它加入红黑树,如果是映射文件,还需要设置vm_file为目标文件
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间
Linux并不是在缺页中断产生的时候才进行页面回收。Linux有一个守护进程kswapd,比较每个内存区域的高低水位来检测是否有足够的空闲页面来使用。每次运行时,采用lru算法来置换一定数量的页面到swap分区
oom
oom是内核的一种保护机制,它监控进程的内存使用情况,并且使用oom_score为每个进程的内存使用情况进行评分:进程消耗的内存越大,oom_score越大。运行占用的cpu越多,oom_score越小。oom_score越大,越容易被杀死。
在实际工作中,可以手动设置进程的oom_adj,oom_adj的取值范围是[-17, 15],数值越大越容易被杀死。-17表示禁止oom,设置进程oom_adj的示例如下:
echo -16 > /proc/$(pidof sshd)/oom_adj
高端内存
内核虚拟地址跟物理地址的对应关系为:
物理地址 = 逻辑地址 – 0xC0000000
那么内核逻辑地址空间访问为0xc0000000 ~ 0xffffffff,那么对应的物理内存范围就为0×0 ~ 0×40000000,即只能访问1G物理内存。若机器中安装8G物理内存,那么内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核 的地址空间已经全部映射到物理内存地址范围0×0 ~ 0×40000000。即使安装了8G物理内存,那么物理地址为0×40000001的内存,内核该怎么去访问呢?
显 然不能将内核地址空间0xc0000000 ~ 0xfffffff全部用来简单的地址映射。因此x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和 ZONE_HIGHMEM。ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域如下:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM896MB ~ 结束
内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存
SMP和NUMA

smp(多对称处理器):最经典的使用内存的方式是cpu通过总线去访问内存。多个cpu在总线的一侧,所有的内存组成一大片内存,在总线的另一侧,所有的cpu访问内存都要经过总线,而且距离都是一样的,这种模式称为smp,它的一个显著缺点是总线会成为瓶颈
numa(非一致内存访问):这种模式下,内存不是一整块,每个cpu都有自己的本地内存,cpu访问本地内存不用过总线,速度快很多,每个cpu和内存一起称为一个numa节点。缺点是:1 本地内存不足时,cpu去另外的numa节点申请内存,延时会比较长。2 物理内存是不连续的,页号也不连续,内存模型变成了非连续内存模型,管理起来复杂。