上篇文章说目标是想拉一丢知乎的用户数据 这周正好有时间 给他整一发大的

-
目标
1 通过登录账号获取关注用户(第一层)
2 通过获取到的关注用 继续循环获取关注用户 level++
3 用户信息表格截个图 大概就是这些

-
实现方式
1 语言 Python3
2 库--requests gevent BeautifulSoup(lxml)
3 数据库 MongoDB
4 PIL(图像库) pytesseract(验证码识别-识别率低(不是重点))
-
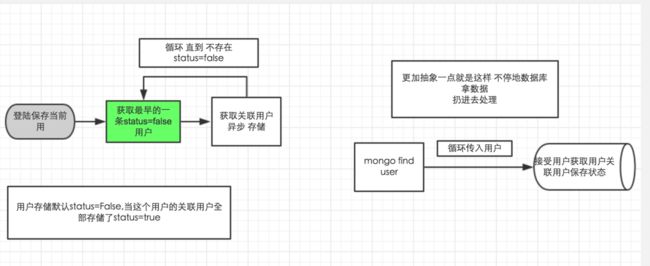
整体过程实现逻辑
1 登陆账号 以当前账号为中心用户 获取基本信息 保存数据库 默认完成状态是false
2 循环开启 每次读取最早的一条 status=False的用户 异步 读取关联url数据存储 依次循环
-
现在一步一步做
整个代码结构图

本来还想开着多进程 后面试了一下 没几下知乎就给我限制ip了
发现当前这种 算是没有在没有代理ip的情况下速度还算不错的
后面有爬取一个代理ip网站 但是用起来多数不可用或者说可用时间太短(正式因为被限制ip了 和 mac总是黑屏后 自动断网 就算了 目的达到了 也抓了一丢 ~)

-###代码过程
1 登陆 要从当前用户开始 先得登陆 保持登陆状态 就是保持cookie状态 cookie作为服务器识别你是否登陆的标志
所以说到底我们就要在登陆这个操作我们模拟完成后 存cookie 后续的链接访问后带上这个cookie 这里我们用的requests 特别方便 直接session-requests就能共享上个连接的cookie
登陆中 有可能遇到验证码 这里用到了自动识别三次 失败就会弹出图片手动输入
-
getMyCenterURL 判断登陆成功与否 随便用登陆成功后能娶到的一个标识来判断就行
'''
if name == 'main':
account = 'phone or email'
secret = 'XXOO'
refer="http://www.zhihu.com/"
if(getMyCenterURL()):
#登陆状态
pass
else:
LoginActon.login(secret,account,session,headers)
getMyCenterURL()''' -
登陆没成功说明cookie失效 这里通过抓取到的接口来登陆 至于怎么抓取 网上很多讲解的 主要步骤
1 chrome F12 前往知乎登陆页面 故意输错密码 抓取登陆接口 与 request from表单 看post的内容 这个网上很多
2 验证码 同意的抓取 这里用了自动是别的一个库 不过成功率 太低 三次自动识别失败 就弹出图片手动输入
3 cookie保存
cookie载入 名为cookies
'''
session = requests.session()
session.cookies = cookielib.LWPCookieJar(filename='cookies')
try:
session.cookies.load(ignore_discard=True)
except:
print("Cookie 未能加载")
'''
登陆之后 session.cookies.save()保存
4 登陆成功后 就可以开始抓取数据了 先把自己作为第一个用户抓取保存数据库 后面就以自己为中心开始抓取
 login ok 后的数据抓取调用
login ok 后的数据抓取调用 -
数据抓取 DataParseAction类 看看整体代码
两个方法
1 根据用户关注用户url获取关注列表用户
2 根据用户主页 抓取用户基本新保存数据库
方法一 在while 循环中一条一条的从数据库取出来 塞入方法2中 方法2保存具体数据具体代码
import random
import time
import gevent
import pymongo
import requests
__author__ = 'Daemon1993'
from bs4 import BeautifulSoup, SoupStrainer
from ZHSpider import LoginActon
from ZHSpider import getProxyIP
'''
解析 用户主页数据
parmas url userHomePage
get all attention users
'''
# 全局 count 每次解析一个 就加一
count = 0
sleep_time = 0
sleep_timeCount = 0
# tagName_ClassName 获取相关数据
def getTagTextByName_Class(soup, tagName, class_name, data, key):
try:
value = soup.find(tagName, class_=class_name).text
data[key] = value
except Exception as e:
pass
# getTitle by Name_Class
def getTagTitleByName_Class(soup, tagName, class_name, data, key):
try:
value = soup.find(tagName, class_=class_name).get('title')
data[key] = value
except:
pass
def getSexByName_Class(soup, tagName, class_name, data, key):
try:
data[key] = "未知"
value = soup.find(tagName, class_=class_name)
value = value.find('i')
tags = value.get('class')
tag_str = "".join(tags)
if (tag_str.find('female') != -1):
data[key] = "female"
else:
data[key] = "male"
except:
pass
# 获取关注详情
def getFollowsDetail(soup, tag1, class1, tag2, class2, data, attr_name, key):
try:
data[key] = LoginActon.index_url + soup.find(tag1, class_=class1).find(tag2, class_=class2).get(attr_name)
# 获取 关注信息
index = 0
for tag in soup.find(tag1, class_=class1).find_all("strong"):
if (index == 0):
data["followees"] = tag.text
else:
data["followers"] = tag.text
index += 1
except:
return False
pass
def getAttentionContent(soup, data):
try:
topics = []
for img in soup.find("div", class_="zm-profile-side-topics").find_all("img"):
topics.append(img.get('alt'))
data["topics"] = topics
except:
pass
def changeRefer(headers,refer):
headers["Referer"]=refer
# 根据URL获取 数据 解析保存
def saveDataByUrl(from_url, url, headers, zh, relation_level):
data = {}
data['_id'] = url
data['from_url'] = from_url
global sleep_time
if(sleep_time!=0):
sleep_time=random.randint(0,5)
if(sleep_time>3):
print('sleep {0}'.format(sleep_time))
time.sleep(sleep_time)
r = requests.session()
try:
if(from_url!=url):
changeRefer(headers,from_url)
html = r.get(url,timeout=5.0, headers=headers)
except Exception as e:
print("saveDataByUrl {0}".format(e))
return
pass
only_data_info = SoupStrainer("div", class_="zm-profile-header-main")
soup_info = BeautifulSoup(html.text, "lxml", parse_only=only_data_info)
getTagTextByName_Class(soup_info, "span", "name", data, "name")
getTagTitleByName_Class(soup_info, "div", "bio ellipsis", data, "introduction")
getTagTitleByName_Class(soup_info, "span", "location item", data, "location")
getTagTitleByName_Class(soup_info, "span", "business item", data, "business")
getSexByName_Class(soup_info, "span", "item gender", data, "gender")
getTagTitleByName_Class(soup_info, "span", "employment item", data, "work_adr")
getTagTitleByName_Class(soup_info, "span", "position item", data, "work_direction")
getTagTitleByName_Class(soup_info, "span", "education item", data, "education_school")
getTagTitleByName_Class(soup_info, "span", "education-extra item", data, "education_direction")
try:
description = soup_info.select('span[class="description unfold-item"] span[class="content"]')[0].get_text()
data["description"] = description
except Exception as e:
pass
# 关注行为
only_data_action = SoupStrainer("div", class_="zu-main-sidebar")
soup_action = BeautifulSoup(html.text, "lxml", parse_only=only_data_action)
getFollowsDetail(soup_action,
"div", "zm-profile-side-following zg-clear",
"a", "item",
data, "href", "followees_url")
# 获取关注话题
getAttentionContent(soup_action, data)
global count
try:
data["relation_level"] = relation_level
# 当前账号 的关注账号 默认没有被全部加载
data["followees_status"] = False
if(count%50==0):
print(data)
#200一次随机大于 不停 小于停
if(count%200==0):
if(sleep_time>3):
sleep_time=0
else:
sleep_time=random.randint(0,5)
zh.insert(data)
except:
pass
count += 1
return True
def startSpider(session, headers, zh):
print('知乎爬虫 开始工作 ------ 飞起来。。。。')
# 获取当前DBzhong status=False的所有URL 最大5000
while True:
tasks = []
userinfo= zh.find_one({"followees_status": False})
if(userinfo is None):
break
from_url = userinfo['_id']
try:
followees_url = userinfo['followees_url']
except:
zh.remove(from_url)
print('delete {0} '.format(from_url))
continue
pass
relation_level = userinfo['relation_level']
tasks.append(gevent.spawn(getAllAtentionUsers,
from_url, followees_url, session, headers, zh, relation_level + 1,userinfo))
gevent.joinall(tasks)
# 获取当前所有的关注用户列表 返回
def getAllAtentionUsers(from_url, follows_url, session, headers, zh, relation_level,userinfo):
if (follows_url is None):
return
html = ""
r = requests.session()
r.cookies = session.cookies
try:
changeRefer(headers,from_url)
html = r.get(follows_url, timeout=5.0, headers=headers).text
except Exception as e:
pass
relation_info = SoupStrainer("div", class_="zm-profile-section-wrap zm-profile-followee-page")
soup = BeautifulSoup(html, "lxml", parse_only=relation_info)
urls = []
for user in soup.find_all("div", class_="zm-profile-card zm-profile-section-item zg-clear no-hovercard"):
user_a = user.find("a")
url = LoginActon.index_url + user_a.get('href')
urls.append(url)
# 保存每个关注的用户信息
print('user {0} follows size{1} '.format(from_url, len(urls)))
tasks = [gevent.spawn(saveDataByUrl, from_url, url, headers, zh, relation_level) for url in urls]
gevent.joinall(tasks)
try:
userinfo["followees_status"]=True
zh.save(userinfo)
except:
pass
print('用户 {0} followees save OK save count {1}'.format(from_url, count))
-
遇到状况
周六晚上代码写完后 挂着跑了一晚上 不知道为啥电脑熄屏后 网络断了 获取了7000多条 relation_level 到了4
还特意设置永不睡眠 周天白天重新开始
然后知乎给我限制ip啦
也不知道为啥 电脑能访问 请求返回 提示 ip次数过多 然后今天一天都在研究怎么绕开归根打的就是 不要只用一个ip 你可以多台机器爬去 可以每次拨号动态分配ip 什么的
后面我也去扒了一些免费代理ip网站的ip

用起来也不是顺利 大部分不能用 明明验证百度能过 访问知乎就readTimeout 这里整了几个小时后 后面 用一个list存ip
从本机开始 如果失败 就取新的ip删除list中旧的 但是一运行 大部分超时 能用的也很慢 (不太理想)后面还是放弃了 周一上班去 电脑挂着 回来又断网了 想想先这样吧
- 项目要跑起来
1 用户名密码输入
2 有mongoDB数据库 本地安装也行
github地址
等
寂寞到夜深
夜已静荒凉
夜已静昏暗
莫道你在选择人
人亦能选择你
公平原没半点偏心...