2. 用cat进行拼接
cat 用于读取文件、拼接数据,还能够从标准输入中进行读取。
- 压缩多余的空白行
cat -s file
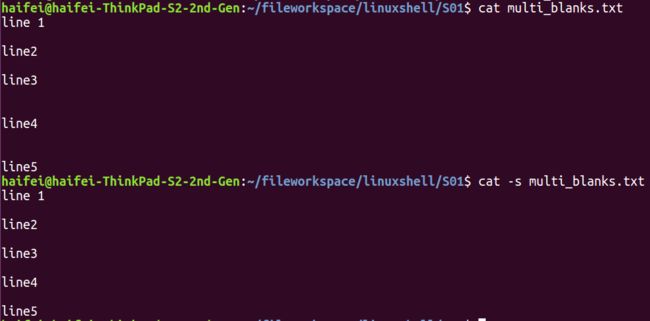 压缩空行.png
压缩空行.png - 将制表符显示为^I
cat -T file
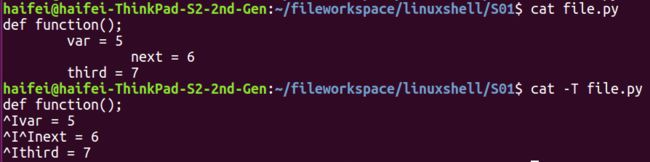 制表符显示.png
制表符显示.png - 行号
cat -n file
3. 录制并回放终端会话
录制终端会话:script -t 2> timing.log -a output.session
结束录制:exit
回放:scriptreplay timing.log output.session
(实测Ubuntu16.04 效果并不好)
Linux下利用script命令录制并回放终端会话
- 若想实现完整的录制功能,就必须有一个
time文件,文件名可以任意取但一定注意-t后面的2>。这条语句是将stderr重定向输出到文件。缺少这段语句将失去模拟回放的功能。 -
output.file存储了全部的输出信息,也是我们回放信息的来源。-a的意义是将输出append到文件。之所以这么做是因为在录制期间我们已经对命令行作了有效的输出,所以若要保留这些输出信息,必须把输出流复制一下,也就是append。 - 如果不添加
-a output.file这段语句,则默认生成一个名为typescript的文件,可以使用这个默认文件作为output.file -
output.file中除了输出的文本信息外,还保存了光标移动的信息。 - 录制脚本后用
exit推出 - 如果开始一次新的录制,应该创建两个新的记录文件而非使用原来的。因为脚本的
append方式并不会将原来文件内容清空而是在末尾添加。
4. 文件查找与文件列表
- find 命令的工作方式:沿着文件的层次结构向下遍历,匹配符合条件的文件,执行相关的操作。
-
find base_path从该位置向下搜索
find . -print-print打印搜索到文件的路径
-print0指明了使用‘\0’作为匹配间的定界符,文件名包含换行符时,使用 - 根据文件名或正则表达式进行搜索
find /home/slynux -name "*.txt" -print-name 匹配时忽略大小写
匹配多个条件中的一个,可以采用 OR 条件操作:
find . \( -name "*.txt" -o -name ".pdf" \) -print - 否定参数
find . ! -name "*.txt" -print
 否定参数.png
否定参数.png - 基于目录深度的搜索
-maxdepth: 向下遍历的目录最大深度
-mindepth:向下遍历的目录最小深度
find . -maxdepth 1 -name "f*" -print - 根据文件类型搜索
-type: 对文件类型进行过滤
如:find . -type d -print
| 文件类型 | 类型参数 |
|---|---|
| 普通文件 | f |
| 符号链接 | l |
| 目录 | d |
| 字符设备 | c |
| 块设备 | b |
| 套接字 | s |
| FIFO | p |
- 根据文件时间进行搜索
Linux三种时间戳:
访问时间 -atime:用户最近一次访问文件的时间
修改时间 -mtime: 文件内容最后一次被修改的时间
变化时间 -ctime: 文件元数据(例如权限或所有权)最后一次改变的时间- 打印出最近7天内被访问过的所有文件:
find . -type f -atime -7 -print - 打印出7天前访问的所有文件
find . -type f -atime 7 -print - 打印出访问时间超过7天的所有文件
find . -type f -atime +7 -print
- 打印出最近7天内被访问过的所有文件:
基于时间的参数的计量单位:
-amin 访问时间
-mmin 修改时间
-cmin 变化时间
打印出时间超过7分钟的所有文件
find . -type f -amin +7 -print
-newer 指定一个比较时间戳的参考文件,然后找出比参考文件更新的所有文件。
比file.txt修改时间更近的所有文件:
find . -type f -newer file.txt -print
- 基于文件大小的检索
# 大于2KB的文件
find . -type f -size +2k
# 小于2KB的文件
find . -type f -size -2k
| 符号 | 文件大小 |
|---|---|
| b | 块 512字节 |
| c | 字节 |
| w | 字 2字节 |
| k | 1024字节 |
| M | 1024k 字节 |
| G | 1024M 字节 |
- 删除匹配的文件
-delete:可以用来删除find查找到的匹配文件
如:find . -type f -name "*.swap" -delete - 基于文件权限和所有权的匹配
-perm:指明find应该只匹配基于特殊权限
如:find . -type f -perm 644 -print
-user: 查找某个特定用户所拥有的文件
如:find . -type f -user slynux -print - 利用find执行命令或动作
#找出root拥有的所有文件,然后用-exec更改所有权
find . -type f -user root -exec chown slynux {} \;
# {} 对于任何匹配的文件名,{}均会被该文件名替换
- 让find跳过特定的目录
find devel/source_path \( -name ".git" -prune \) -o \( -type f -print \)
# \( -name ".git" -prune \)的作用就是用来排除
5. 玩转 xargs
xargs擅长将标准输入数据转换为命令行参数。也可以将单行或多行文本输入转换为其他格式,例如单行变多行或是多行变单行
-
将stdin接收到的数据重新格式化,再将参数提供给其他命令
将多行转换为单行输入
将单行转换为多行输入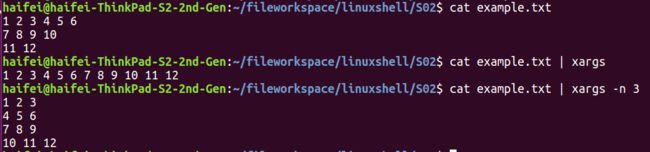 image.png
image.png 用 -d 选项为输入指定一个定制的定界符

- 读取stdin,将格式化参数传递给命令
# 传递一个参数
./cecho.sh arg1
# 传递多个参数
./cecho.sh arg1 arg2 arg3
使用xargs

-I 指定替换字符串,在执行的时候进行替换
haifei@haifei-ThinkPad-S2-2nd-Gen:~/fileworkspace/linuxshell/S02$ cat args.txt | xargs -I {} ./s01_cecho.sh -p {} -l
-p arg1 -l#
-p arg2 -l#
-p arg3 -l#
- 结合find使用xargs
# xargs与find是一对死党。注意find后的定界符,下面是删除.txt文件
# -print0 指明 \0 为定界符,-0 是以\0为定界符
find . -type f -name "*.txt" -print0 | xargs -0 rm -f
# 统计C程序文件的行数
find source_code_dir_path -type f -name "*.c" -print0 | xargs -0 wc -l
6. 用tr进行转换
tr是对来自标准输入的内容进行字符替换,字符删除和重复字符压缩等操作。使用格式如下:
tr [options] set1 set2
由set1映射到set2,然后将输出写入stdout。如果两个字符集的长度不相等,set2会不断重复最后一个字符。set2大于set1,超出被忽略
#用tr删除字符
$ echo "Hello 123 world 456" | tr -d '0-9'
Hello world
# 字符串补集, -c 为取反
$ echo "Hello 1 char 2 next 4" | tr -d -c '0-9 \n'
1 2 4
# 用tr压缩字符
$ echo "GNU is not UNIX. Recursive right ?" | tr -s ' '
GNU is not UNIX. Recursive right ?
tr可以使用集合一样使用不同的字符类,这些字符类包括:
使用方式
tr [:class:] [:class:]
如:tr '[:lower:]' '[:upper:]'
| 字符类 | 说明 |
|---|---|
| alnum | 字母和数字 |
| alpha | 字母 |
| cntrl | 控制字符 |
| digit | 数字 |
| graph | 图形字符 |
| lower | 小写字母 |
| 可打印字符 | |
| punct | 标点符号 |
| space | 空白字符 |
| upper | 大写字母 |
| xdigit | 十六进制字符 |
7. 校验和与核实
检验和程序用于生成 校验和秘钥,然后利用这个校验和秘钥核实文件的完成性。
用于文件完整性测试的特定秘钥称为校验和
# 计算md5sum,会生成
$ md5sum args.txt
3f228b61493cf779a95c94dd8e11328b args.txt
#将md5sum重定向到一个文件,使用MD5文件核实数据完整性
md5sum filename > file_sum.md5
#校验
md5sum -c file_sum.md5
# 检查所有的文件
md5sum -c *.md5
#SHA-1与上类似,md5sum替换为sha1sum,生成的文件为.sha1
#对目录进行检验
md5deep -rl directory_path > directory.md5
#使用find来递归计算校验和:
find directory_path -type f -print0 | xargs -0 md5sum >> directory.md5
#核实
md5sum -c directory.md5
8. 加密工具与散列
加密技术主要用于数据遭受未经授权的访问。
crypt gpg base64 md5sum sha1sum openssl
# crypt是简单的加密工具,它从stdin接受一个文件以及口令作为输入,然后将加密数据输入到Stdout
$ crypt output_file
Enter passphrase:
#通过命令行参数来提供口令
crypt PASSPHEASE output_file
# 解密文件
crypt PASSPHEASE -d output_file
# gpg 使用加密技术保护文件,确保数据在送达目的地之前无法被读取
#加密,会生成filename.gpg
gpg -c filename
#读取口令,然后对文件进行解密
gpg filename.gpg
#base64 是一组相似的编码方案,他将ASCII字符转换为以64为基数的形式,以可读的ASCII字符串来描述二进制文件。
# 加密
base64 filename > outputfile
cat file | base64 > outputfile
#解码
base64 -d file > outputfile
cat base64_file | base64 -d > outputfile
# md5sum 与 sha1sum 都是单向散列算法,无法逆向出原始数据,常用于验证数据完整性或为特定数据生成唯一的秘钥。
md5sum file
sha1sum file
# shadow-like散列(salt散列)
#SALT指额外的字符串,用来起一个混淆的作用,使加密不易破解。
opensslpasswd -l -salt SALT_STRING PASSWORD
将SALT_STRING替换为随机字符串,并将PASSWORD替换为你想要的密码
9. 排序、唯一与重复
# 简单排序
sort file1.txt file2.txt > sorted.txt
sort file1.txt file2.txt -o sorted.txt
# 数字顺序排序
sort -n file.txt
# 逆序进行排序
sort -r file.txt
# 月份进行排序
sort -M months.txt
# 合并俩个已排序过的文件
sort -m sorted1 sorted2
# 找出文件是否已经排序过
sort file1.txt file2.txt | uniq
# 检查文件是否排序过
#!/bin/bash
sort -C filename ;
if [ $? -eq 0 ]; then
echo Sorted;
else
echo Unsorted;
fi
1.依据键或列进行排序
$ cat data.txt
1 mac 2000
2 winxp 4000
3 bsd 1000
4 linux 1000
# -k指定了排序应该按照哪一个键进行,-r 告诉sort命令按照逆序排序
$ sort -nrk 1 data.txt
4 linux 1000
3 bsd 1000
2 winxp 4000
1 mac 2000
$ sort -k 2 data.txt
3 bsd 1000
4 linux 1000
1 mac 2000
2 winxp 4000
# uniq命令通过消除重复内容,从给定输入中找出唯一的行。他也可以用来消除重复行
$cat sorted.txt
bash
foss
hack
hack
# 重复的行只打印一次
$ uniq sorted.txt
bash
foss
hack
# 重复行不打印
$ uniq -u sorted.txt
$ sort sorted.txt | uniq -u
# 统计各行在文件中出现的次数
$ sort sorted.txt | uniq -c
# 找出文件中重复的行
$ sort sorted.txt | uniq -d
# -s 指定可以跳过前 n 个字符
# -w 指定用于比较的最大字符数
$ cat data3.txt
u:01:gnu
d:04:linux
u:01:bash
u:01:back
$ sort data3.txt | uniq -s 2 -w 2
d:04:linux
u:01:back
10. 临时文件命名与随机数
最适合存储临时数据的位置是/tmp
# 创建临时文件:
$ filename=`mktemp`
$ echo $filename
/tmp/tmp.azrfACVCNy
# 创建临时目录
$ dirname=`mktemp -d`
$ echo $dirname
/tmp/tmp.2P3ESjrx1y
# 生成文件名,有不希望生成实际的文件或目录
$ tempfile=`mktemp -u`
$ echo $tempfile
/tmp/tmp.RXlgIJpWMw
# 根据模板生成临时文件
$ mktemp test.XXX
test.Cmy
11. 分割文件和数据
# 将文件分割为多个大小为1k的文件, -b指定分割大小
$ split -b 1k wifi_password.odt
$ ls
wifi_password.odt xaa xab xac xad xae xaf xag xah xai
# -d指定使用数字后缀,-a length 指定后缀长度
$ ls
wifi_password.odt x0000 x0001 x0002 x0003 x0004 x0005 x0006 x0007 x0008
# 分割后文件设置前缀
$ split -b 1k wifi_password.odt -d -a 4 split_file
$ ls
split_file0000 split_file0001 split_file0002 split_file0003 split_file0004 split_file0005 split_file0006 split_file0007 split_file0008 wifi_password.odt
# 根据行数分割文件
$ split -l 10 data.file
12. 根据扩展名切分文件名
# #代表了由左向右最小匹配,%代表了右向左最小匹配
# ##由左向右最大 匹配,%%代表了右向左最小匹配
# 移除 .* 匹配的最右边的内容,假设URL=WWW.google.com
$ echo ${URL%.*}
WWW.google
# 右边开始一直匹配到的 *. 移除
$ echo ${URL%%.*}
WWW
# 移除 *. 所匹配的最左边的内容
$ echo ${URL#*.}
google.com
#
$ echo ${URL##*.}
com
13. 批量重命名和移动
# 将 *JPG 更名为 *.jpg
$ rename *.JPG *.jpg
# 替换文件名中的空格替换为字符“_”
$ rename 's/ /_/g'
# 转换文件名大小写
$ rename 'y/A-Z/a-z/' *
# 移动.mp3 到指定目录
$ find path -type f -name "*.mp3" -exec mv {} target_dir \;
# 将所有文件名中的空格替换为字符“_”
$ find path -type f -exec rename 's/ /_/g' {} \;
14. 拼写检查与词典操作
# 包含的词典文件
$ ls /usr/share/dict/
american-english british-english
# 检查给定的单词是否为词典中的单词
# ^ 单词的开始, $ 单词的结束 -q 禁止产生任何输出
grep “^word$” /usr/share/dict/british-english -q #(这个要看返回值)
# 列出文件中以特定单词起头的所有单词
$ look word filepath
$ grep "^word" filepath
# 如果没有给出文件参数,默认使用/usr/share/dict/words
15. 交互输入自动化
$ cat S02_15_interactive.sh
#!/bin/bash
read -p "Enter number:" no ;
read -p "Enter name:" name ;
echo your have enter $no, $name;
$ sh S02_15_interactive.sh
Enter number:200
Enter name:haifei
your have enter 200, haifei
# -e表示生成输入序列,会解释其中的\n分界符
$ echo -e "200\nhello\n" | ./S02_15_interactive.sh
your have enter 200, hello
# expect等待特定的输入提示,通过检查输入提示来发送数据
$ cat s02_15_automate_expect.sh
#!/bin/bash
spawn ./interactive.sh
expect "Enter number:"
send "1\n"
expect "Enter name:"
send "hello\n"
expect eof
# spawn参数指定需要自动化哪一个命令
# expect 参数提供需要等待的消息
# send 是要发送的消息
# expect eof 指明命令交互结束
16. 利用并行进程速命令执行
$字符将使得shell命令置于后台并继续执行脚本
$!保存着最近一个后台进程的PID,我们将这些PID放入数组,使用wait命令等待这些进程结束