知识要点:
基本概念
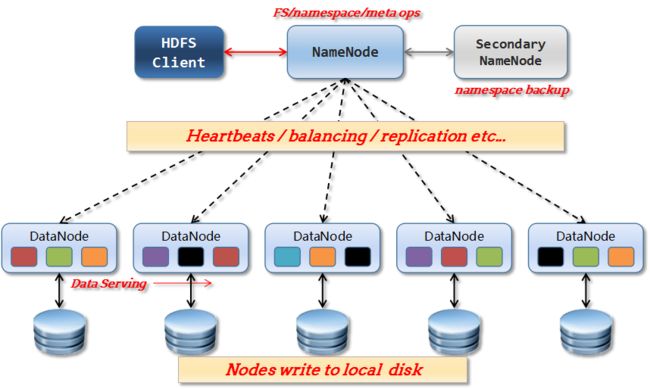
Hadoop底层五行元素
Hadoop四种机制
Hadoop两大功能
基本概念
存储目录
①name:存储元数据
②data:存储数据
③dfs:SecondaryNameNode执行Checkpoint合并(SNN合并)的存储目录
④nm-local-dir:缓存目录
元数据
①抽象目录树
②数据和块的映射
③数据块的存储节点
Hadoop底层五行元素
NameNode
Namenode 维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是 镜像文件(Namespace image)和操作日志文件(edit log)。
在HDFS中主要是通过两个数据结构FsImage和EditsLog来实现Metadata的更新。在启动HDFS时,会从FSImage文件中读取当前HDFS文件的Metadata,之后对HDFS的操作都会记录到EditsLog文件中。
镜像文件
FSImage
保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。
- 对于文件来说包括了数据块描述信息、修改时间、访问时间等;
- 对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
简单的说,FSImage存储的信息就相当于整个HDFS在某一时刻的快照,就是这个时刻HDFS上所有的文件块和目录,分别的状态,位于哪些个datanode,各自的权限,各自的副本个数等。
文件格式
镜像文件(元数据文件):fsimage_oooooooo(如:fsimage_0000000000000000006)
-rw-rw-r-- 1 hadoop hadoop 477 1月 21 13:59 fsimage_0000000000000000023
-rw-rw-r-- 1 hadoop hadoop 62 1月 21 13:59 fsimage_0000000000000000023.md5
-rw-rw-r-- 1 hadoop hadoop 477 1月 21 14:44 fsimage_0000000000000000025
-rw-rw-r-- 1 hadoop hadoop 62 1月 21 14:44 fsimage_0000000000000000025.md5
查看FSImage内容
hdfs oev -i /home/hadoop/hdfs/name/current/fsimage_0000000000000000000 -o /home/hadoop/editslog.xml -p XML
日志文件
①EditLogs
对HDFS进行的各种更新操作、写操作都会被记录到editlog中。日志文件保护两种,一种是历史日志文件,另外一种是正在操作的日志文件。
②文件格式
- 正在操作的日志文件:edits_inprogress_xxxxxxxx(如:edits_inprogress_0000000000000000015)
- 镜像文件(元数据文件):fsimage_oooooooo(如:fsimage_0000000000000000006)
历史日志
-rw-rw-r-- 1 hadoop hadoop 314 1月 19 15:02 edits_0000000000000000001-0000000000000000006
-rw-rw-r-- 1 hadoop hadoop 567 1月 19 16:02 edits_0000000000000000007-0000000000000000014
-rw-rw-r-- 1 hadoop hadoop 42 1月 19 17:02 edits_0000000000000000015-0000000000000000016
-rw-rw-r-- 1 hadoop hadoop 651 1月 19 18:02 edits_0000000000000000017-0000000000000000025
-rw-rw-r-- 1 hadoop hadoop 42 1月 19 19:02 edits_0000000000000000026-0000000000000000027
-rw-rw-r-- 1 hadoop hadoop 42 1月 19 20:02 edits_0000000000000000028-0000000000000000029
正在操作的日志
-rw-rw-r-- 1 hadoop hadoop 1048576 1月 21 14:44 edits_inprogress_0000000000000000026
查看EditsLog内容
hdfs oev -i /home/hadoop/hdfs/name/current/edits_0000000000000000001-0000000000000000006 -o /home/hadoop/editslogs.xml -p XML
启动阶段合并
启动阶段合并的作用就是:在启动时保证FSImage元数据是最新的。
EditsLog存储的是日志信息,在Namenode启动后所有对目录结构的增加,删除,修改等操作都会记录到EditsLog文件中,并不会同步的记录在FSImage中。
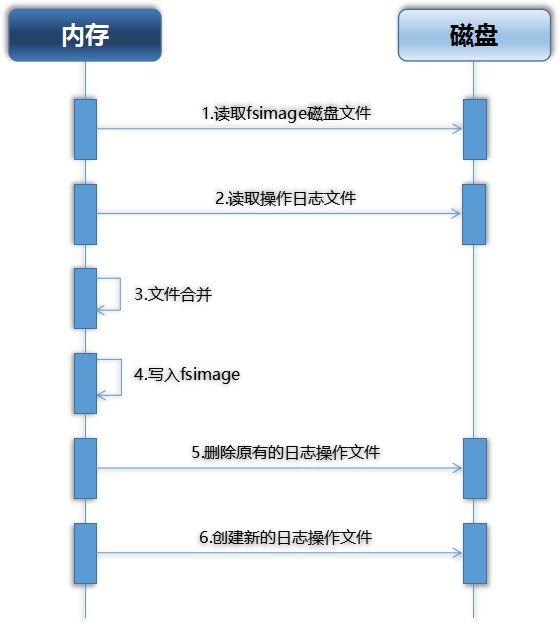
而当Namenode结点关闭的时候,也不会将FSImage与EditsLog文件进行合并,这个合并的过程实际上是发生在Namenode启动的过程中。
- 将fsimage文件加载到内存
- 将edits文件也加载到内存
- 在内存将fsimage和edits文件进行合并
- 将合并后的文件写入fsimage
- 清空原先edits中的数据,使用一个空的edits文件进行正常操作
SecondaryNameNode
问题:如果NameNode在启动后发生的改变过多,势必会导致EditsLog文件变得非常大,那么在下一次NameNode启动的过程中,读取了FSImage文件后,会用这个无比巨大的EditsLog文件进行“启动阶段合并”,从而导致Hadoop启动时间过长。
SecondaryNameNode的作用就是:根据规则被唤醒,然后进行FSImage文件与EditsLog文件的合并,防止editslog文件过大,从而导致NameNode启动时间过长。
为什么要合并?
防止editslog文件过大,导致NameNode启动时间过长。
FSImage是一个元数据文件,并且保存着Hadoop的整个目录树结构。随着时间的推移,元数据也会越来越庞大,FSImage文件也会越来越大,而FSImage的目录树也越来越复杂,如果直接对FSImage进行修改,势必会影响到效率。所以先把操作记录到EditsLog日志文件中,而后在checkpoint点(合并了多长时间或者事务数达到多少条)上进行合并。
 Checkpoint合并
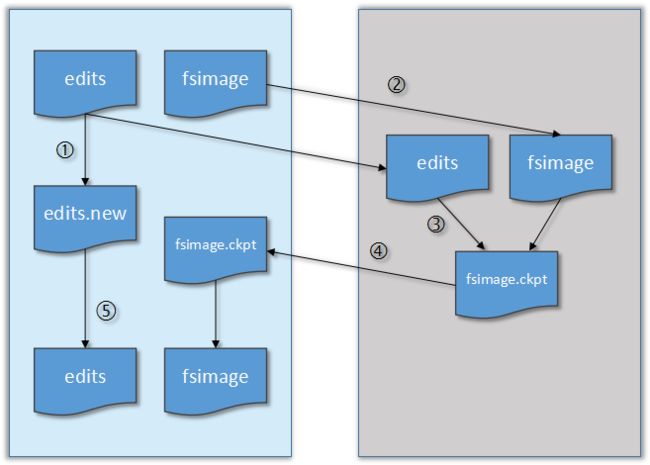
Checkpoint合并 - 将hdfs更新记录写入一个新的文件——edits.new。
- 将fsimage和editlog通过http协议发送至secondary namenode。
- 将fsimage与editlog合并,生成一个新的文件 —— fsimage.ckpt。因为比较耗时,所以在secondary namenode中进行。
- 将生成的fsimage.ckpt通过http协议发送至namenode。
- 重命名fsimage.ckpt为fsimage,edits.new为edits。
- 等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
合并参数
checkpoint合并触发的条件可以在core-site.xml文件中进行配置
fs.checkpoint.period 检查点间隔时间 单位秒。默认值3600,当距离上次检查点执行超过该时间后启动检查点
fs.checkpoint.size 检查点文件大小 单位字节。默认值67108864,当edits文件超过该大小后,启动检查点
DataNode
DataNode在HDFS中真正存储数据。相关的数据会有两个文件,如:
-rw-rw-r-- 1 hadoop hadoop 157136 2020/01/29 16:06 blk_1073742069
-rw-rw-r-- 1 hadoop hadoop 1235 2020/01/29 16:06 blk_1073742069_1245.meta
blk_1073742069 中存储的是具体的数据。
blk_1073742069_1245.meta 是一个CRC校验文件,其中保存数据块的校验信息。
Hadoop四种机制
- 机架感知
- 负载均衡
- 心跳机制
- 安全机制
Hadoop两大功能
数据块(Block)
128m 1m
文件大小===》split(128m)===》Map Task 10TB 1m 多少Task 128m 80000
寻道时间
写入
- 先和NameNode沟通,在元数据里面创建一个新文件,不关联块。
- 检查文件:是否存在、操作权限。创建一个块。
- FSDataOutputStream,和client建立连接开始写入文件。
- 读取
HDFS常用命令
文件命令
列出HDFS下的文件
$ hdfs dfs -ls
# 显示HDFS中指定的文件的读写权限、大小、创建时间、路径等信息
$ hdfs dfs -ls -h payment.txt
# 查看目录中的文件
$ hdfs dfs -ls /home
上传文件
将hadoop目录下的payment文件上传到HDFS:
$ hdfs dfs -put payment.txt /home
文件被复制到本地系统中
将HDFS中的in文件复制到本地系统并命名为getin:
$ hdfs dfs -get in getin
删除文档
删除HDFS下名为home的目录:
$ hdfs dfs -rm -r /home
查看文件
查看HDFS下payment.txt文件中的内容:
$ hdfs dfs -cat /home/payment.txt
**建立目录 **
$ hdfs dfs -mkdir /user/hadoop/examples
复制文件
$ hdfs dfs -copyFromLocal 源路径 路径
管理命令
缓存
当我们需要频繁访问HDFS中的热点公共资源文件和短期临时的热点数据文件时,可以使用Hadoop缓存。比如:需要频繁访问的报表数据、公共资源(如:jar依赖、计算包等)。
①建立缓存池:
# 建立缓存池
$ hdfs cacheadmin -addPool cache
# 查看缓存是状态
$ hdfs cacheadmin -listPools -stats cache
②把文件或者目录添加到缓存池中
# 把文件添加到缓存池中
$ hdfs cacheadmin -addDirective -path /home/payment.txt -pool cache
# 查看缓存
$ hdfs cacheadmin -listDirectives
存储策略
①存储类型
- DISK:普通磁盘
- SSD:SSD盘
- RAM_DISK:内存盘
- ARCHIVE:归档/压缩,不是实际的磁盘类型,而是数据被压缩存储。
②存储策略 - HOT:存储和计算都热。如果是热块,那么复制的目标也是DISK(普通的磁盘)。
- COLD:用于有限计算的存储。 数据不再使用,或者需要归档的数据被移动到冷存储。如果数据块是冷的,则复制使用ARCHIVE.
- WARM:半冷半热。warm块的复制内容,部分放置在DISK,其它的在ARCHIVE.
- All_SSD: 所有数据存储在SSD.
- One_SSD: 一个复制在SSD,其它的在DISK.
- LAZY_PERSIST:只针对只有一个复制的数据块,它们被放在RAM_DISK,之后会被写入DISK。
# 设置一个文件为HOT存储策略
$ hdfs storagepolicies -setStoragePolicy -path /home/twilight.txt -policy HOT
# 查看某个文件的存储策略
$ hdfs storagepolicies -getStoragePolicy -path /home/twilight.txt
WebHDFS和HttpFS
WebHDFS
HortonWorks,捐赠给Apache Hadoop。建议使用这个。
http://ip:50070/webhdfs/v1/
curl -i -L "http://192.168.56.105:50070/webhdfs/v1/home/payment.txt?op=OPEN"
HttpFS
Cloudera,捐赠给Apache Hadoop
http://ip:14000/webhdfs/v1/