决策树是机器学习最基础的算法之一,基于决策树可衍生出AdaBoostTree、随机森林、GBDT等高级算法。本文重点介绍决策树的构造原理及应用。
1. 什么是决策树
举一个简单的例子,我们在挑选西瓜的时候,如何判断一个西瓜是否好西瓜,有经验的人都知道可以看西瓜的纹理、根蒂、色泽和触感等。
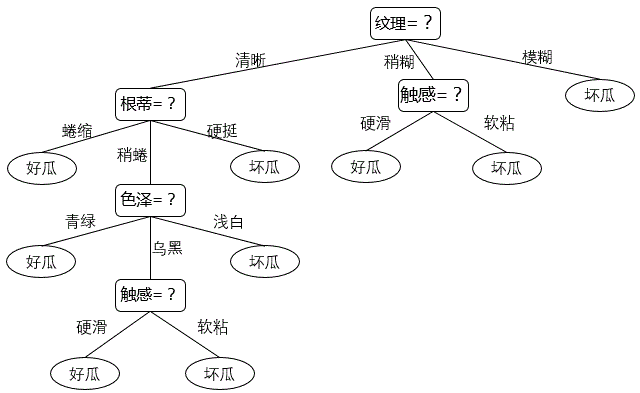
上图就是一棵决策树,也就是一个包含有根节点、分支节点、叶节点的树状结构,叶节点为类别标签。在挑选西瓜的时候,如果带着上面这棵决策树,挑选西瓜的流程就可以是这样:
- step1: 观察西瓜的纹理,如果纹理模糊就可以认为是坏瓜,否则进一步观察;
- step2: 如果纹理稍微模糊,则看西瓜的触感,如果触感硬滑则是好瓜,如果触感软粘则是坏瓜;如果为例清晰,则看根蒂,如果根蒂蜷缩则为好瓜,如果根蒂硬挺则为坏瓜,如果根蒂稍蜷,则再进一步观察;
- step3: 看西瓜的色泽,如果是青绿色则为好瓜,如果是浅白色则为坏瓜,如果为乌黑色则再进一步观察;
- step: 看西瓜的触感,如果触感硬滑则为好瓜,如果触感软粘则为坏瓜。
如果在买西瓜的时候能有这样一棵决策树仅根据西瓜的纹理、根蒂、色泽和触感便能准确判断西瓜的好坏,再也不用担心买到坏瓜啦!但是,这样一棵决策树是如何得来的呢?为什么首先判断西瓜的纹理而不是色泽或触感呢?为什么说纹理模糊的就是坏瓜呢?接下来将详细介绍决策树的构造原理和过程。
2. 如何构造决策树
给定数据集
,
表示样本的类别,类似于卖西瓜例子中的“好瓜”和“坏瓜”,属性集(用于判断样本类别的维度,类似于上例中的纹理、触感等)为
,决策树构造过程如下:
STEP1:如果D中样本全属于同一个类别C,则添加节点C,结束;否则进入STEP2。(此时得到的决策树仅包含一个节点,即将任何样本都判断为类别C。)
STEP2:如果属性集个数为空或在每一个属性上面都取相同的值,则将D中样本数最多的类添加到节点中,算法结束;否则进入STEP3。
STEP3:选择最优划分属性
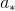
,对于
的每一个取值

,用
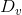
表示D中在
 image.png
image.png
上对应取值
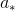
的样本子集;如果

为空,则将分支节点标记为D中样本数最多的类别,算法结束;否则,重复STEP1-STEP3生成样本集为
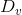
,属性集为
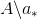
的决策树作为分支节点(递归调用)。
决策树的生成是一个递归的过程,以下三种情况会导致递归结束:
- 当前节点包含的样本全属于同一类别,无需划分;
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
- 当前节点包含的样本集合为空,不能划分。
从决策树的构造过程可以看出,构造决策树最关键的问题在于最优属性选择,即如何选择能够最好的将样本集中各类样本区分开的属性。
3. 最优划分属性选择方法
在判断西瓜是好瓜还是坏瓜的例子中,假定给我们的是一批贴了“好瓜”和“坏瓜”标签的西瓜,让我们从中找出规律用来判断一个没有贴标签的西瓜是好瓜还是坏瓜。
假如所有的好瓜根蒂都是蜷缩的,所有的好瓜根蒂都是硬挺的,那么我们只需要看西瓜的根蒂是蜷缩还是硬挺便可以判断西瓜是好瓜还是坏瓜。这样的结果是我们所期望的,但往往事与愿违。
假如所有根蒂是蜷缩的西瓜其中有95%是好瓜,所有根蒂硬挺的西瓜其中有95%是坏瓜。所有触感硬滑的西瓜中有50%是好瓜,所有触感软粘的西瓜种有50%是坏瓜。此时,我们选择“根蒂”作为划分属性,判断西瓜好坏的准确率为95%左右;而如果选择“触感”作为划分属性,判断西瓜好坏的准确率字50%左右。此时最好的划分属性为“根蒂”。
从上面的分析中可以看出,我们在选择最优划分属性的时候,希望分支节点所包含的样本尽可能属于同一类别,也就是希望划分后样本的纯度尽可能高。接下来将介绍如何衡量样本的纯度和最优划分属性选择方法。
3.1 信息增益
在介绍信息增益之前,先介绍信息熵的定义。信息熵是衡量样本集合纯度最常用的一种指标。假定集合
中第
类样本所占的比例为
,总类别数为
,则集合D的信息熵可以定义为:

的值越小,则集合D的纯度越高;最小值为,最大值为
.
我们选择最优划分属性的目的是使得划分后各自己的“纯度”相对划分前集合的纯度更高,也就是信息熵相对划分前更低。信息熵的变化量就是信息增益。
假定离散属性a有V个可能的取值
,若使用a来对样本集D进行划分,则会产生V个分支节点,其中第v个分支节点包含了样本集中所有在属性a上取值为
的样本,即为
。由于各个样本子集的样本数量不同,所以考虑给分之节点赋予权重
,样本数越多的分支节点对信息熵的影响越大。按属性a进行划分能获得的信息增益计算公式为:

以信息增益为属性选择方法,标准为选择信息增益最大的属性作为最优划分属性。ID3决策树学习算法就是以信息增益为准则来选择划分属性。
3.2 增益率
信息增益准则对可取值数目较多的属性有所偏好,即候选属性可取值数目越多带来的信息增益越大,但是这种情况下大的信息增益可能并不是我们希望得到的结果。为了减少这种偏好可能带来的不利影响,可采用增益率来进行最优划分属性选择。增益率的定义为:
,其中
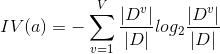
,属性a可取值数量越多,IV(a)的值一般越大,因此增益率的弊端在于对可取值数量小的属性有所偏好。
C4.5算法采用的就是增益率,但是不是单纯地应用增益率。为了权衡信息增益和增益率各自的优势和弊端,C4.5的处理方法是先从候选划分属性中选择信息增益高于平均值得属性,再从中选择增益率最高的属性作为最优划分属性。
3.3 基尼指数
除了信息增益和增益率外,常用的划分属性选择指标还有基尼指数。与信息熵一样,也是描述集合中样本的纯度,但是原理不一样。基尼指数描述的是从样本集D中又放回的随机抽取两次抽到不同类别样本的概率,用数学公式表示为:

,
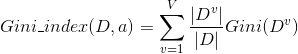
.
CART决策树就是采用基尼指数来选择最优划分属性。
4. 连续值处理
以上讨论均是基于属性取值为有限离散值展开的,但是在实际应用场景中,更多的是属性取连续值的情况,比如人的身高体重、西瓜的重量和密度等。如果是连续值属性,那么属性的可取值数量为无穷多个,以上属性选择方法仅局限于取有限离散值得属性。
针对连续值属性,我们可以将连续区间离散化,最简单的策略是采用二分法。给定样本集D和连续值属性a,假定a在D上出现了n各取值,将所有这些取值按照从小到大排序,依次以每一个取值
为划分点,将样本分成在a上取值大于
和不大于
如果属性a在取值上本来就有很明显的界限,如{1, 2, 3, 2, 1, 2, 2, 8, 7, 8, 9},并且依然按照上面的方法划分,那么很明显应该是在3或者7里面选择一个。但是我们更加希望决策边界能够尽量远离各类别的取值边界,也就是以(3+7)/2为分界会更加合理。因此,在实际中我们常采用的是对n各取值进行排序后,依次取相邻两个值得均值作为划分点,共n-1个。
连续值属性与离散值属性不同的是,若当前节点划分属性为连续值属性,则该属性还可以作为后代节点的划分属性。也就是在递归选择最优划分属性的过程中不从属性集中删除。
例如我们以西瓜的密度和含糖量来判断西瓜是好瓜还是坏瓜,数据集如下:
| 编号 | 密度 | 含糖率 | 类别 |
|---|---|---|---|
| 1 | 0.697 | 0.460 | 好瓜 |
| 2 | 0.774 | 0.376 | 好瓜 |
| 3 | 0.634 | 0.264 | 好瓜 |
| 4 | 0.608 | 0.318 | 好瓜 |
| 5 | 0.556 | 0.215 | 好瓜 |
| 6 | 0.403 | 0.237 | 好瓜 |
| 7 | 0.481 | 0.149 | 好瓜 |
| 8 | 0.437 | 0.211 | 好瓜 |
| 9 | 0.666 | 0.091 | 坏瓜 |
| 10 | 0.243 | 0.267 | 坏瓜 |
| 11 | 0.245 | 0.057 | 坏瓜 |
| 12 | 0.343 | 0099 | 坏瓜 |
| 13 | 0639 | 0.161 | 坏瓜 |
| 14 | 0.657 | 0.198 | 坏瓜 |
| 15 | 0.360 | 0.370 | 坏瓜 |
| 16 | 0.593 | 0.042 | 坏瓜 |
| 17 | 0.719 | 0.103 | 坏瓜 |
从上表中的数据,我们可以得到以下决策树:
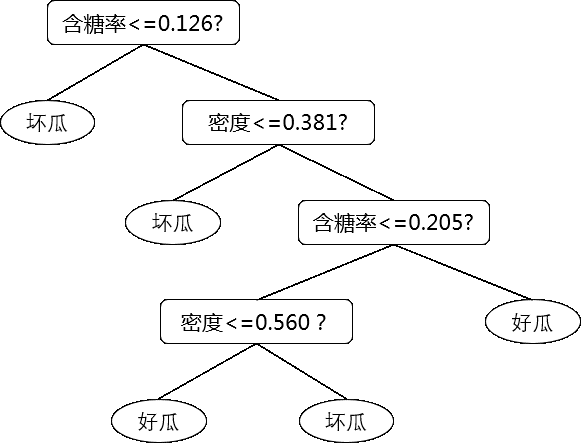
在决策树中,同一个属性出现了两次。
6. Python实现C4.5决策树
# -*- coding: utf-8 -*-
"""
本程序完全应用pandas中处理数据的方法,舍近求远,切勿模仿。
"""
import pandas as pd
import math
# 计算信息熵
def infoEntropy(ds):
ind = ds.columns
# 统计每个类别的样本数
classCount = ds.groupby(ind[-1]).count().values[:, 0]
# 计算每个类别样本占比
sampleNum = sum(classCount)
classRatio = list(map(lambda x: float(x)/sampleNum, classCount))
classEntropy = list(map(lambda x: -x*math.log(x, 2), classRatio))
return sum(classEntropy)
# 按属性取值划分数据集
def dsAttrEntropy(ds, attr, attrTypeDic):
sampleNum = ds.shape[0]
dsEntropy = infoEntropy(ds)
# 计算子集加权信息熵的匿名函数
l1 = lambda x: infoEntropy(x) * x.shape[0] / float(sampleNum)
# 计算子集固有值(IV)的匿名函数
l2 = lambda x: 1 if x.shape[0] == sampleNum \
else -(x.shape[0]/float(sampleNum))/(math.log(x.shape[0]/float(sampleNum), 2))
if attrTypeDic[attr] == 0:
# 数据集在属性a上的取值
attrValues = list(ds[attr].drop_duplicates().values)
# 按属性值分组
groups = ds.groupby(attr)
# 属性各取值对应的样本子集
dsSplited = list(map(lambda x: groups.get_group(x), attrValues))
# 计算信息增益
entropyGain = dsEntropy - sum(list(map(l1, dsSplited)))
# 计算IV
iv = sum(list(map(l2, dsSplited)))
entropyGainRatio = entropyGain / iv
return [attr, attrValues, entropyGain, entropyGainRatio]
else:
# 对属性值去重,排序
sortedAttrValues = list(ds[attr].drop_duplicates().sort_values().values)
minEnt = 9999
split = 0
iv = 0
for i in range(1, len(sortedAttrValues)):
tempSplit = (sortedAttrValues[i - 1] + sortedAttrValues[i]) / 2.
dsSplited = [ds[ds[attr] <= tempSplit], ds[ds[attr] > tempSplit]]
splitEnt = sum(list(map(l1, dsSplited)))
if splitEnt < minEnt:
minEnt = splitEnt
split = tempSplit
iv = sum(list(map(l2, dsSplited)))
entropyGain = dsEntropy - minEnt
entropyGainRatio = entropyGain / iv
return [attr, split, entropyGain, entropyGainRatio]
# 选择最优划分属性
def attrChoose(ds, attrTypeDic):
attrs = ds.columns[:-1]
attrRefer = pd.DataFrame(list((map(lambda x: dsAttrEntropy(ds, x, attrTypeDic), attrs))),
columns=list(['attr', 'split', 'entropyGain', 'entropyGainRatio']))
return attrRefer[attrRefer['entropyGain'] >= attrRefer['entropyGain'].mean()]\
.sort_values(by='entropyGainRatio', ascending=False).head(1)
# 创建决策树
def createTree(levelID, tree, tempNode, ds, split, attrTypeDic):
attrs = ds.columns
if ds[attrs[-1]].describe().unique()[1] == 1:
tree.append(addNode(levelID, ds[attrs[-1]].describe().top, tempNode, split, 'leaf'))
levelID += 1
return tree
if len(attrs) == 1 or ds[attrs[:-1]].drop_duplicates().shape[0] == 1:
tree.append(addNode(levelID, ds[attrs[-1]].describe().top, tempNode, split, 'leaf'))
levelID += 1
return tree
bestAttr = attrChoose(ds, attrTypeDic)
bestAttrName = bestAttr['attr'].values[0]
tree.append(addNode(levelID, bestAttrName, tempNode, split, 'brunch'))
levelID += 1
if attrTypeDic[bestAttrName] == 0:
groups = ds.groupby(bestAttrName)
for v in bestAttr['split'].values[0]:
subDs = groups.get_group(v)
if subDs.shape[0] == 0:
tree.append(addNode(levelID, ds[attrs[-1]].describe().top, bestAttrName, v, 'leaf'))
return tree
if subDs.shape[0] == ds.shape[0]:
tree.append(addNode(levelID, subDs[attrs[-1]].describe().top, bestAttrName, v, 'leaf'))
return tree
tree = createTree(levelID, tree, bestAttrName, subDs.drop(bestAttrName, axis=1), v, attrTypeDic)
else:
bestAttrSplit = bestAttr['split'].values[0]
subDs = ds[ds[bestAttrName] <= bestAttrSplit]
tree = createTree(levelID, tree, bestAttrName, subDs, str(bestAttrSplit) + '-', attrTypeDic)
subDs = ds[ds[bestAttrName] > bestAttrSplit]
tree = createTree(levelID, tree, bestAttrName, subDs, str(bestAttrSplit) + '+', attrTypeDic)
return tree
# 添加节点
def addNode(levelID, nodeName, fatherNode, splitCondition, nodeType):
return {'levelID': levelID, 'nodeName': nodeName, 'fatherNode': fatherNode,
'splitCondition': splitCondition, 'nodeType': nodeType}
# 读取数据集
ds = pd.read_table('watermelon.txt', delimiter=',')
attrType = [0, 0, 0, 0, 0, 0, 1, 1]
attrs = ds.columns
attrTypeDic = {}
for i in range(len(attrs)-1):
attrTypeDic[attrs[i]] = attrType[i]
tree = createTree(0, [], '', ds, '', attrTypeDic)
ofile = open('tree.txt', 'w')
for t in tree:
ofile.write(str(t)+'\n')
ofile.close()
输入数据集:
色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜
青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.460,是
乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是
乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是
青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是
浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是
青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是
乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是
乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是
乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否
青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否
浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否
浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否
青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否
浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否
乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.360,0.370,否
浅白,蜷缩,浊响,模糊,平坦,硬滑,0.593,0.042,否
青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否
输出决策树:
{'levelID': 0, 'nodeName': '纹理', 'fatherNode': '', 'splitCondition': '', 'nodeType': 'brunch'}
{'levelID': 1, 'nodeName': '根蒂', 'fatherNode': '纹理', 'splitCondition': '清晰', 'nodeType': 'brunch'}
{'levelID': 2, 'nodeName': '是', 'fatherNode': '根蒂', 'splitCondition': '蜷缩', 'nodeType': 'leaf'}
{'levelID': 2, 'nodeName': '密度', 'fatherNode': '根蒂', 'splitCondition': '稍蜷', 'nodeType': 'brunch'}
{'levelID': 3, 'nodeName': '否', 'fatherNode': '密度', 'splitCondition': '0.3815-', 'nodeType': 'leaf'}
{'levelID': 3, 'nodeName': '是', 'fatherNode': '密度', 'splitCondition': '0.3815+', 'nodeType': 'leaf'}
{'levelID': 2, 'nodeName': '否', 'fatherNode': '根蒂', 'splitCondition': '硬挺', 'nodeType': 'leaf'}
{'levelID': 1, 'nodeName': '触感', 'fatherNode': '纹理', 'splitCondition': '稍糊', 'nodeType': 'brunch'}
{'levelID': 2, 'nodeName': '是', 'fatherNode': '触感', 'splitCondition': '软粘', 'nodeType': 'leaf'}
{'levelID': 2, 'nodeName': '否', 'fatherNode': '触感', 'splitCondition': '硬滑', 'nodeType': 'leaf'}
{'levelID': 1, 'nodeName': '否', 'fatherNode': '纹理', 'splitCondition': '模糊', 'nodeType': 'leaf'}