一.什么是协程
介绍
首先引用维基百科的一段介绍
协程是计算机程序的一类组件,推广了协作式多任务的子程序,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程源自Simula和Modula-2语言,但也有其他语言支持。协程更适合于用来实现彼此熟悉的程序组件,如协作式多任务、异常处理、事件循环、迭代器、无限列表和管道。
根据高德纳的说法, 马尔文·康威于1958年发明了术语coroutine并用于构建汇编程序。[1] [2] 协程最初在1963年被提出。[2]
上面提到的「子例程」我们可以简单理解为函数调用。维基百科还列出了函数调用和协程的区别,这里我总结了一下,具体如下:
- 函数调用的入口只有函数的起始位置,一旦退出就完成了函数调用。每个函数调用只会返回一次。
- 函数调用在所有语言中都是层级调用(函数调用栈)。
- 协程可以通过
yield中断执行,转而执行别的协程。在这种转换过程中不存在调用者与被调用者的关系。
简单来说,协程(coroutine)是一种程序运行的方式,可以理解成 协作的线程 或 协作的函数 。协程既可以用单线程实现,也可以用多线程实现。前者是一种特殊的子例程,后者是一种特殊的线程。
历史
徐宥博士在他的博客里有提到:
虽然协程是伴随着高级语言诞生的,它却没有能像子过程一样成为通用编程语言的基本元素。
从 1963 年首次提出到上个世纪九十年代,我们在 ALOGL, Pascal, C, FORTRAN 等主流的命令式编程语言中都没有看到原生的协程支持。协程只稀疏地出现在 Simula,Modular-2 (Pascal 升级版) 和 Smalltalk 等相对小众的语言中。协程作为一个比子进程更加通用的概念,在实际编程却没有取代子进程,这一点不得不说是出乎意外的。如果我们结合当时的程序设计思想看,这一点又是意料之中的:协程是不符合那个时代所崇尚的“自顶向下”的程序设计思想的,自然也就不会成为当时主流的命令式编程语言 (imperative programming) 的一部分。
但是因为硬件性能的提升、多线程等开始普及,协程又重回历史舞台大放异彩。
说一说我理解的协程
通俗一点讲,协程就是可以挂起(暂停)任意函数的执行,这个挂起操作是由开发者来完成的,并且你可以在你想恢复的时候恢复它。它跟线程最大的区别在于线程一旦开始执行,从任务的角度来看,就不会被暂停,直到任务结束这个过程都是连续的,线程之间是抢占式的调度,因此也不存在协作问题。这只是协程提供的最基本的能力,基于这个能力我们可以做很多事情。看起来其实概念很简单,但是应用起来还是比较复杂的。
二.大前端协程的发展
前端
早在2015年,JavaScript 推出 ECMAScript 6 标准的时候,就引入了协程的编程方式,我们可以看一个例子:
对于传统的网络请求,应该是下面这个样子
ajax({
method: 'POST',
url: url,
success: function (data) {
//解析 json
data.json(function(json) {
//在这里对获取的数据进行操作.....
})
})
这种异步编程方式被称之为「回调地狱」。
为了解决「回调地狱」的问题,ECMAScript 6 引入了几种异步编程方式。
Promise
Promise 从字面上来讲,就代表一种承诺。从语法上来讲,它是一个对象。简单来说,Promise 就是一个容器,里面保存着某个未来才会结束的事件。Promise 内部有三种状态:pending(等待),fulfiled(成功),rejected(失败)。Promise 的状态只会受异步操作的影响,并且一旦状态改变之后,就不会在变。Promise 对象的状态改变,只有两种可能:从 pending 变为 fulfilled 和从 pending 变为 rejected。
来看一看 Promise 的构造方法:
const promise = new Promise(function(resolve, reject) {
// ... some code
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);
}
});
Promise 构造函数接受一个函数作为参数,该函数的两个参数分别是 resolve 和 reject 。resolve 函数的作用是,将 Promise 对象的状态从 pending 变为 resolved,在异步操作成功时调用,并将异步操作的结果,作为参数传递出去;reject 函数的作用是,将 Promise 对象的状态从从 pending 变为 rejected,在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去。
然后我们可以指定 then 和 catch 来分别接收 resolved 和 reject 回调。
getJSON("/posts.json")
.then(result => {···})
.catch(error => {···})
then 所指定的函数中还可以返回 Promise 对象,相当于一个异步操作里面做了另一个异步操作。
getJSON("/post/1.json").then(function(post) {
return getJSON(post.commentURL);
}).then(function (comments) {
console.log("resolved: ", comments);
}, function (err){
console.log("rejected: ", err);
});
所以我们上面提到的网络请求利用 Promise 最终可以写成这样:
fetch(url).then(function(response) {
return response.json()
}).then(function (json) {
//处理json
}).catch(function (err){
console.log("rejected: ", err);
});
可以看到,通过 Promise 的改造后,嵌套的异步编程变得很清晰了。
Generator
上面讲了异步的一种新的解决方案 Promise,但它并不是基于协程的,只是内部对回调函数做了封装。下面我们会介绍一种真正基于协程的异步编程解决方案 Generator。
function* gen(x) {
var y = yield x + 2;
return y;
}
var g = gen(1);
g.next() // { value: 3, done: false }
g.next() // { value: undefined, done: true }
ES6 中,用 function* 表示协程函数。调用gen(1)的时候函数不会立即执行,而是返回一个遍历器(提供 next 方法来遍历)。调用 g.next() 会真正执行函数, 当遇到 yield 的时候,主函数会出让控制权,转而执行 yield 后面的语句。g.next() 的返回值是一个对象,value 代表 yield 后面表达式的返回值,done 代表当前的 Generator 函数是否执行完毕。
Generator 的执行过程可以用下图表示:

上面的示例 Generator 只是处理了一个同步操作,但其实 Generator 的威力是在处理异步上,下面来看一下一个 Generator 在异步情况下的处理。由于异步操作的特殊性,在 yield 切换到异步操作的时候,并不知道具体什么时候返回,所以在这里需要借助 Thunk 函数和递归来实现异步 Generator 的自动执行 。JS 有一个叫做 co 的库可以让异步 Generator 自动执行。
定义一个 Generator 函数:
var gen = function* () {
var f1 = yield readFile('/etc/fstab');
var f2 = yield readFile('/etc/shells');
console.log(f1.toString());
console.log(f2.toString());
};
利用 co 可以自动执行异步 Generator:
var co = require('co');
co(gen);
co 会返回一个 Promise 对象,用于订阅函数执行完毕的回调:
co(gen).then(function (){
console.log('Generator 函数执行完成');
});
async / await
ES2017 标准引入了 async 函数,使得异步操作更加方便。我们上面用 Generator 实现的读取文件操作,转化成 async 函数就是这样:
const asyncReadFile = async function () {
const f1 = await readFile('/etc/fstab');
const f2 = await readFile('/etc/shells');
console.log(f1.toString());
console.log(f2.toString());
};
其实 async / await 函数就是 generator 的语法糖。把 * 号换成了 async,把 yield 换成了 await。Generator 的执行需要执行器,所以才有了上面提到的 co 库。而 async 函数自带执行器,所以调用它可以像调用普通函数那样:
asyncReadFile()
下面用 async 函数改写一个普通的网络请求场景:
async function loadData() {
let response = await fetch(url)
let responseJson = await response.json()
//接下来对 json 进行操作.....
}
await 后面一般是一个 Promise 对象,也可以跟基础类型。如果是基础类型 await 会立刻返回。
iOS
对于 iOS 来说,苹果一直没有推出协程的 API,iOS 的异步编程一直都是基于 Block 实现。可以用一张图诠释 iOS 的异步编程现状:

基于Block回调的异步编程方式有以下缺点:
- 容易进入"嵌套地狱"
- 错误处理复杂和冗长
- 容易忘记调用completion handler
- 条件执行变得很困难
- 从互相独立的调用中组合返回结果变得极其困难
- 在错误的线程中继续执行(如子线程操作UI)
而就在今年的早些时候,一篇名为「刚刚,阿里开源 iOS 协程开发框架 coobjc!」的文章引爆了朋友圈,阿里推出了 iOS 上的协程框架 「coobjc」。
先来看一下这个库的架构:
- 最底层是协程内核,包含了栈切换的管理、协程调度器的实现、协程间通信channel的实现等
- 中间层是基于协程的操作符的包装,目前支持async/await、Generator、Actor等编程模型
- 最上层是对系统库的协程化扩展,目前基本上覆盖了Foundation和UIKit的所有IO和耗时方法
以下是这个库的核心能力:
提供了类似
C#和Javascript语言中的Async/Await编程方式支持,在协程中通过调用await方法即可同步得到异步方法的执行结果,非常适合IO、网络等异步耗时调用的同步顺序执行改造。提供了类似
Kotlin中的Generator功能,用于懒计算生成序列化数据,非常适合多线程可中断的序列化数据生成和访问。提供了
Actor Model的实现,基于Actor Model,开发者可以开发出更加线程安全的模块,避免由于直接函数调用引发的各种多线程崩溃问题。提供了元组的支持,通过元组
Objective-C开发者可以享受到类似Python语言中多值返回的好处。
还对 Foundation 的一些基础库做了扩展:
提供了对
NSArray、NSDictionary等容器库的协程化扩展,用于解决序列化和反序列化过程中的异步调用问题。提供了对
NSData、NSString、UIImage等数据对象的协程化扩展,用于解决读写IO过程中的异步调用问题。提供了对
NSURLConnection和NSURLSession的协程化扩展,用于解决网络异步请求过程中的异步调用问题。提供了对
NSKeyedArchieve、NSJSONSerialization等解析库的扩展,用于解决解析过程中的异步调用问题。
官方也提供了使用示例:

经过协程改造后的网络请求:
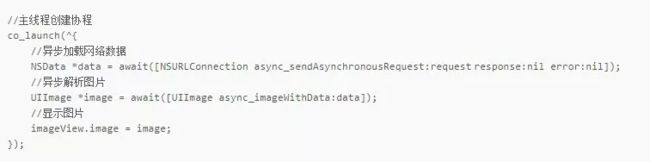
在 coobjc 中,也可以找到上面提到的 ES6 中的 API:
COPromise
COPromise 的用法同 ES6 Promiese 对象的用法基本一样:
- (void)testCoobjcPromise {
COPromise *promise = [COPromise promise:^(COPromiseFulfill _Nonnull fullfill, COPromiseReject _Nonnull reject) {
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
fullfill(@"异步任务结束");
});
} onQueue:dispatch_get_global_queue(0, 0)];
[promise then:^id _Nullable(id _Nullable value) {
NSLog(@"%@",value);
return nil;
}];
}
在延迟三秒之后,控制台输出了我们在 Promise 内部 fullfill 回调中传入的字符串 “异步任务结束” 。
COGenerator
COGenerator 也类似,只是写法上略有不同:
- (void)testGenerator {
COGenerator *generator = [[COGenerator alloc] initWithBlock:^{
int index = 0;
while(co_isActive()){
yield_val(@(index));
index++;
}
} onQueue:dispatch_get_global_queue(0, 0) stackSize:1024];
co_launch(^{
for(int i = 0; i < 10; i++){
int val = [[generator next] intValue];
NSLog(@"generator______value:%d",val);
}
});
}
COChan
COChan 可以理解为一个管道,管道两边分别是消息的发送者和接收者。原型是基于CSP并发模型。
实际上 COChan 就是一个阻塞的消息队列。
我们可以通过以下的方法创建一个 COChan:
COChan *chan = [COChan chanWithBuffCount:1];
buffCount 表示该 chan 可以容纳的消息数量,因为在阻塞的条件下面 chan 内部的消息会堆积。
创建好 chan 之后,可以通过 send 和 receive 方法发送和接收 chan 的消息。send 和 receive 有两种,一种是阻塞式的 send、receive,一种是非阻塞式的 send_nonblock、receive_nonblock。以下是一些 send 和 receive 需要注意的点:
-
send、receive必须在协程中调用。当调用send或者receive,会使当前的协程挂起直到buffCount为 0 的时候恢复。也就是说,如果调用了send协程会一直等待直到有人调用了receive,反过来调用receive也是一样的道理。 -
send_nonblock、receive_nonblock不会阻塞协程,所以也不需要在协程中调用。
Await
与 ES6 不同的是, coobjc 的 await 方法里面只能处理 COPromise 和 COChan 类型的对象:
- (COPromise *)Promise {
COPromise *promise = [COPromise promise:^(COPromiseFulfill _Nonnull fullfill, COPromiseReject _Nonnull reject) {
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
fullfill(@"异步任务结束");
});
} onQueue:dispatch_get_global_queue(0, 0)];
return promise;
}
-(void)testAwait {
co_launch(^{
id result = await([self Promise]);
NSLog(@"%@", result);
});
}
在这里我们构造了一个 COPromise 对象,并在内部模拟了一个异步操作,然后我们把这个COPromise 对象传到了 await 方法里,在 await 方法的返回值里我们得到了这个 COPromise 对象的输出。
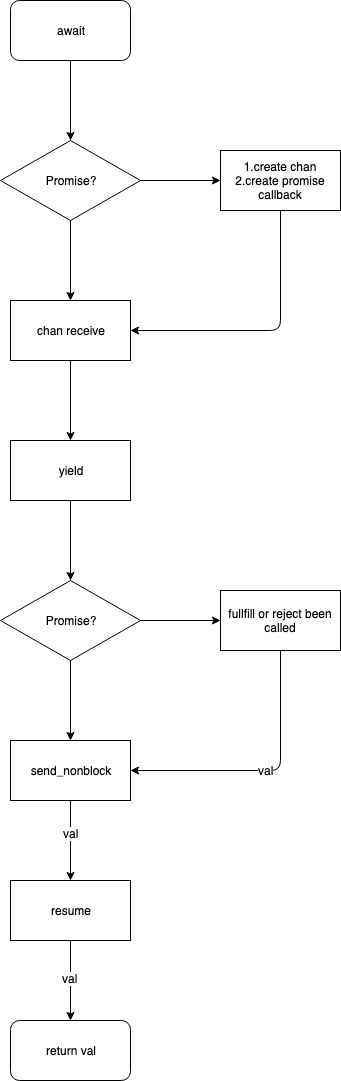
注意: coobjc 协程上的任务都需要执行在 co_launch 的回调中。
co_await 执行过程:
三.优势
介绍完了上面几种协程的 API,那么相对传统的基于子例程的开发方式,协程到底带来了什么优势?
异步操作的同步化表达
假设我们有3个异步任务需要同步执行,并且它们之间互相依赖,那么基于传统的回调函数是下面这样:
- (void)testNormalAsyncFunc {
@weakify(self);
[self asyncTask:^(NSInteger number) {
@strongify(self);
[self asyncTask:^(NSInteger number) {
@strongify(self);
NSInteger num = number + 1;
[self asyncTask:^(NSInteger number) {
@strongify(self);
NSLog(@"testNormalAsyncFunc_____%ld",(long)number);
} withNumber:num];
} withNumber:number];
} withNumber:1];
}
- (void)asyncTask:(void(^)(NSInteger number))callBack withNumber:(NSInteger)number {
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(2 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
if (callBack) {
callBack(number);
}
});
}
传统的回调函数在代码上阅读不是特别友好,并且需要处理多级 Block 嵌套过程中循环引用的问题。在这里我是直接忽略调了错误处理,真实的环境中错误处理不容忽视,那么在多级回调中就会变得特别复杂,这也是文章一开始说的回调地狱。
下面,我们看下经过协程改造后的代码:
- (void)testCORoutineAsyncFunc {
co_launch(^{
NSNumber *num = await([self promiseWithNumber:@(1)]);
// NSError *error = co_getError(); 如果有错误,可以这样获取
num = await([self promiseWithNumber:@(num.integerValue + 1)]);
num = await([self promiseWithNumber:@(num.integerValue + 1)]);
NSLog(@"testCORoutineAsyncFunc______%@",num);
});
}
- (COPromise *)promiseWithNumber:(NSNumber *)number {
COPromise *promise = [COPromise promise:^(COPromiseFulfill _Nonnull fullfill, COPromiseReject _Nonnull reject) {
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(3 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
fullfill(number);
// reject(error); // 如果有错误,回调到上层
});
} onQueue:dispatch_get_global_queue(0, 0)];
return promise;
}
可以看到,异步流程非常清晰,就像写同步代码一样。另外,如果发生错误,在 Promise 内部会调用 reject 回调将错误回调出去,在 await 之后可以调用 co_getError 获取到错误。
对于 IO 的封装
iOS 系统 API 设计很不友好,绝大部分 IO、跨进程调用等耗时接口提供的都是同步方法,主线程调用会产生严重性能问题。coobjc 封装了基本所有的 IO API,让 IO 拥有了协程调度的能力。
//从网络异步加载数据
[NSURLSession sharedSession].configuration.requestCachePolicy = NSURLRequestReloadIgnoringCacheData;
NSURLSessionDownloadTask *task = [[NSURLSession sharedSession] downloadTaskWithURL:url completionHandler:
^(NSURL *location, NSURLResponse *response, NSError *error) {
if (error) {
return;
}
//在子线程解析数据,并生成图片
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSData *data = [[NSData alloc] initWithContentsOfURL:location];
UIImage *image = [[UIImage alloc] initWithData:data];
dispatch_async(dispatch_get_main_queue(), ^{
//调度到主线程显示图片
imageView.image = image;
});
});
}];
协程改造后:
co_launch(^{
NSData *data = await(downloadDataFromUrl(url));
UIImage *image = await(imageFromData(data));
imageView.image = image;
});
懒加载序列
懒加载序列也是协程的一个经典用法。下面我们利用 COGenerator 生一个懒加载的斐波那契序列:
- (void)testFibonacciLazySequence {
COGenerator *fibonacci = [[COGenerator alloc] initWithBlock:^{
yield_val(@(1));
int cur = 1;
int next = 1;
while(co_isActive()){
yield(@(next));
int temp = cur + next;
cur = next;
next = temp;
}
} onQueue:dispatch_get_global_queue(0, 0) stackSize:1024];
co_launch(^{
for(int i = 0; i < 10; i++){
int val = [[fibonacci next] intValue];
NSLog(@"fibonacciLazySequence______value:%d",val);
}
});
}
利用 COGenerator 我们生成了一个懒加载的斐波那契数列并打印了数列的前10个元素,由于是懒加载序列,只有在调用 next 方法的时候才会真正在内存中生成这个元素。并且,生成器的实现是线程安全的,因为它们都是在单线程上运行,数据在生成器中生成,然后在另一条协程上使用,期间不需要加任何锁。而使用传统容器需要注意线程安全问题并且容易引发 crash。
下面一张图里诠释了 Generator 和传统容器的区别:

传统的数组,为了保障线程安全,读写操作必须放到一个同步队列中。而 generator 不需要,generator 可以在一个线程生成数据,另外一个线程消费数据。
Actor Model
race condition
大家应该都听说过进程和线程,也都知道进程和线程的概念。简单概括就是:
对操作系统来说,线程是最小的执行单元,进程是最小的资源管理单元。
进程和线程都是由操作系统调度和管理的,开发者并没有权限。现在主流的操作系统下,线程都是抢占式的。每个线程有特定的时间片,当线程时间片耗尽,操作系统就会让线程暂停转而去执行其它线程。这就造成了在多线程下,线程与线程之间会出现 race condition。举一个最常见的 i++ 的例子:
i++ 操作在底层其实是有三步:
- 寄存器从变量读取 i 的值
- 在寄存器中对 i 进行 +1 操作
- 把加完后的值写回变量

在多线程情况下,就有可能出现如图所示的情况。
为了避免这个问题,我们需要对出现 race condition 的资源加锁。但是锁会带来以下问题:
- 锁对于系统资源的占用。
- 涉及到线程阻塞状态和可运行状态之间的切换。
- 涉及到线程上下文的切换。
以上涉及到的任何一点,都是非常耗费性能的操作。
Actor
为了避免频繁的线程加锁和线程切换,我们引入了一种新的并发模型:
Actor Model 是一种替代多线程的并发解决方案。传统的并发解决方案是一种共享数据方式,使用共享数据的并发编程面临的最大问题是数据条件竞争,处理各种锁的问题是让人十分头疼的。
首先我们来看一下 Actor 的结构:
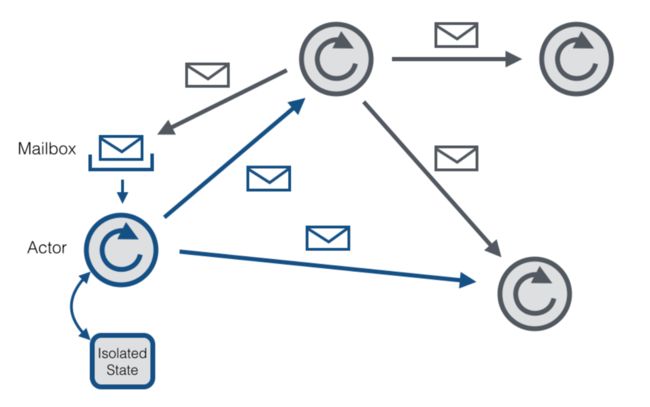
Actor 模型的理念是:万物皆为
Actor。
Actor 与
Actor 之间是通过消息通信,并不会直接共享每一个资源。
Actor 内部有一个
Mailbox ,可以理解为一个消息队列。所有消息都会先发送到
Mailbox。
Actor 内部管理着自身的
State,这个
State 只有
Actor 自己可以访问。
让我们来看一下 Actor 和传统 OOP 的对比:

示例
计数器
假设我们现在需要实现一个计数器,传统的实现应该是这样:
如果不加锁,我们使用多线程对计数器进行累加操作后,是达不到我们想得到的目标值的。原因就是上面提到的 race condition。
经 Actor 改造后:
COActor *countActor = co_actor_onqueue(get_test_queue(), ^(COActorChan *channel) {
int count = 0;
for(COActorMessage *message in channel){
if([[message stringType] isEqualToString:@"inc"]){
count++;
}
else if([[message stringType] isEqualToString:@"get"]){
message.complete(@(count));
}
}
});
我们使用 Actor 来测试一下多线程下的计数器累加操作:
NSOperationQueue *queue = [[NSOperationQueue alloc] init];
queue.maxConcurrentOperationCount = 15;
for (int i = 0;i < 10000;i++) {
NSBlockOperation *operation = [NSBlockOperation blockOperationWithBlock:^{
[countActor sendMessage:@"inc"];
}];
[queue addOperation:operation];
}
[queue waitUntilAllOperationsAreFinished];
co_launch(^{
int currentCount = [await([countActor sendMessage:@"get"]) intValue];
NSLog(@"count: %d", currentCount);
});
可以看到最后输出的值是我们期望的目标值,可见 Actor 在多线程下是线程安全的。
求素数
假设现在有一个任务,利用多线程找100000以内的素数的个数,如果以传统的共享数据的方式,我们需要两个变量,一个记录当前找到了第几,一个记录当前素数的个数。因为是多线程,我们在操作这两个变量的时候需要对它们加锁。加锁的坏处大家也很清楚,首先是加锁的开销是很大的,而且如果不小心还会出现死锁。
下面我们来使用基于分布式的 Actor Model 来解决这个问题。
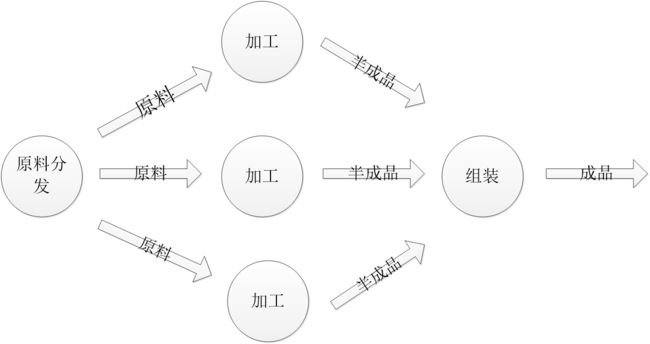
如果用 Actor 模型实现统计素数个数,那么我们需要1个 Actor 做原料的分发,就是提供要处理的整数,然后3个 Actor 加工,每次从分发 Actor 那里拿一个整数进行加工,最终把加工出来的半成品发给组装 Actor,组装 Actor 把3个加工 Actor 的结果汇总输出。
下面是一个分布式的结构:
COActor 就是
coobjc 为我们提供的
Actor 封装类,下面我们用
COActor 实现上面的分布式结构:
#import "Actor.h"
#import
@interface Actor ()
@property (nonatomic, strong) COActor *assembler;
@property (nonatomic, strong) COActor *dispatcher;
@property (nonatomic, strong) NSMutableArray *processers;
@property (nonatomic, assign) NSTimeInterval startTime;
@end
@implementation Actor
- (instancetype)init
{
self = [super init];
if (self) {
_processers = [NSMutableArray arrayWithCapacity:0];
[self setupProcessers];
__weak Actor *weakSelf = self;
_assembler = co_actor_onqueue(dispatch_get_global_queue(0, 0), ^(COActorChan * _Nonnull chan) {
__block int numCount = 0;
for (COActorMessage *message in chan) {
if ([message.stringType isEqualToString:@"add"]) {
numCount ++;
} else if ([message.stringType isEqualToString:@"stop"]) {
NSTimeInterval costTime = CFAbsoluteTimeGetCurrent() - self.startTime;
NSLog(@"素数的个数是______%d 消耗的时间_________%f", numCount, costTime);
}
}
});
_dispatcher = co_actor_onqueue(dispatch_get_global_queue(0, 0), ^(COActorChan * _Nonnull chan) {
for (COActorMessage *message in chan) {
if ([message.stringType isEqualToString:@"start"]) {
weakSelf.startTime = CFAbsoluteTimeGetCurrent();
__block int number = 0;
while (number <= 100000) {
[weakSelf.processers enumerateObjectsUsingBlock:^(COActor * _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[obj sendMessage:@(number++)];
});
}];
}
}
}
});
}
return self;
}
- (void)setupProcessers {
__weak Actor *weakSelf = self;
for (int i = 0;i < 4;i++) {
COActor *processer = co_actor_onqueue(dispatch_get_global_queue(0, 0), ^(COActorChan * _Nonnull chan) {
for (COActorMessage *message in chan) {
NSInteger currentNum = message.uintType;
if ([weakSelf isPrimeNumber:currentNum]) {
[[weakSelf assembler] sendMessage:@"add"];
}
if (currentNum == 10000) {
NSLog(@"processer%d stop",i+1);
[weakSelf.assembler sendMessage:@"stop"];
}
}
});
[self.processers addObject:processer];
}
}
- (BOOL)isPrimeNumber:(NSInteger)number {
BOOL flag = YES;
for (int i = 2;i < number;i++) {
if (number % i == 0) {
flag = NO;
break;
}
}
return flag;
}
- (void)startTask {
[self.dispatcher sendMessage:@"start"];
}
@end
dispatcher 作为自然数的生产者,产生 10000 以内的自然数。
processer 作为加工者,来处理自然数是否是素数的工作。如果是素数,就会发消息到 assembler。
assembler 作为组装者,有一个内部状态 numCount 记录目前素数的个数。当收到加工者的消息后,会把 numCount 自增。
可以看到,基于分布式的 Actor Model,很好的避免了传统并发模型下的共享资源,没有任何的锁操作,并且对每一个 Actor 都进行了明确的功能划分。
四.原理
刚才开篇有提到,协程与普通函数调用的区别就是,协程可以随时中断协程的执行,跳转到新的协程里面去,并且还能在需要的时候恢复。而普通的函数调用是没法作出暂停操作的。所以实现协程的关键就在于把当前调用栈上的状态都保存下来,然后再能从缓存中恢复。
基本上市面上实现这种操作的方法有以下五种:
- 利用 glibc 的
ucontext组件(云风的库)。 - 使用汇编代码来切换上下文(实现c协程),原理同
ucontext。 - 利用C语言语法
switch-case的奇淫技巧来实现(Protothreads)。 - 利用了 C 语言的
setjmp和longjmp。 - 利用编译器支持语法糖。
这里我主要介绍第一种,其它的大家感兴趣可以自行 Google。
这里顺便说一下第一种方法在 iOS 上是已经被废弃的(可能是因为效率不高)。第三种和第四种只是能过做到跳转,但是没法保存调用栈上的状态,看起来基本上不能算是实现了协程,只能算做做demo,第五种除非官方支持,否则自行改写编译器通用性很差。所以阿里爸爸的库其实是使用第二种方法实现的。
uncontext
一.Hello world
uncontext 是一个 c 的协程库,底层也是通过汇编来实现的。首先我们来看一个最简单的例子:
#include
#include
#include
int main(int argc, const char *argv[]){
ucontext_t context;
getcontext(&context);
printf("Hello world");
sleep(1);
setcontext(&context);
return 0;
}
运行这段代码,打印如下:
Hello world
Hello world
Hello world
Hello world
Hello world
Hello world
Hello world
...............
如果我们不终止程序,会一直打印 "Hello world"。
在这里我们初步可以看到,getcontext 保存了当前函数的执行上下文,当程序执行到 setcontext 的时候又会回到 getcontext 的那一行继续执行。
二.uncontext 深入
这里我们需要关注 mcontext_t 和 ucontext_t,和四个函数 getcontext()、setcontext()、makecontext()、swapcontext()。
首先来看下 uncontext 的结构:
typedef struct ucontext {
struct ucontext *uc_link;
sigset_t uc_sigmask;
stack_t uc_stack;
mcontext_t uc_mcontext;
...
} ucontext_t;
- uc_link:指向当前上下文运行终止时会回复的上下文
- uc_sigmask:上下文要阻塞的信号集合
- uc_stack:上下文所使用的栈空间
- uc_mcontext:其中 mcontext_t 类型与机器相关的类型。这个字段是机器特定的保护上下文的表示,包括协程的机器寄存器
下面说一下四个函数:
int getcontext(ucontext_t *ucp);:保存当前的 context 到 ucp 结构体中。int setcontext(const ucontext_t *ucp);:设置当前的上下文为 ucp 。这里会判断如果上下文是通过getcontext()获取的,程序会直接执行这个上下文。如果上下文是通过makecontext()获取的,程序会执行调用makecontext()第二个参数(func)所指向的函数。如果 func 函数返回,则会执行makecontext()第一个参数ucp.uc_link所指向的上下文。如果ucp.uc_link == NULL则程序退出。void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);:调用makecontext()之前需要先调用getcontext()生成上下文 ucp。makecontext()会给该 ucp 指定一个栈空间ucp->uc_stack。最重要的是设置后继上下文ucp->uc_link,这里确保了我们可以在协程间进行切换。然后这里会传入一个函数指针,当后面我们调用setcontext()和swapcontext()的时候会直接调用该函数。具体的在上面setcontext()方法讲解的时候有讲到。int swapcontext(ucontext_t *oucp, ucontext_t *ucp);:保存当前的上下文当 oucp 中,然后激活 ucp 所指向的上下文。
下面我们结合上面给的函数,来看一个简单的例子:
#include
#include
void func1(void * arg)
{
printf("func1");
}
void context_test()
{
char stack[1024*128];
ucontext_t child,main;
print("context_test");
getcontext(&child); //获取当前上下文
child.uc_stack.ss_sp = stack;//指定栈空间
child.uc_stack.ss_size = sizeof(stack);//指定栈空间大小
child.uc_link = &main;//设置后继上下文
makecontext(&child,(void (*)(void))func1,0);//修改上下文指向func1函数
swapcontext(&main,&child);//切换到child上下文,保存当前上下文到main
printf("main");//如果设置了后继上下文,func1函数指向完后会返回此处
}
int main()
{
context_test();
return 0;
}
执行上面代码,会打印出
contest_test
func1
main
现在来分析一下这段代码:按照函数执行顺序,首先会打印 "context_test" 。然后这里用 getcontext() 获取了当前上下文并设置了栈空间和后继上下文。注意这里 main 结构体并没有真正被赋值。随后调用了 makecontext() 并传入了一个指向 func1 的函数指针,那么在下面调用 swapcontext() 的时候就会调用这个函数指针所指向的函数,也就是 func1。swapcontext() 还有一个功能就是把当前上下文赋值给第一个参数,所以现在 main 里面存储了当前的上下文。最后当 func1 执行完之后,由于之前 child.uc_link 设置的是 main,所以会切换到 main 的上下文继续执行,所以我们看到了最后打印的 "main"。
现在我们稍微改动一下代码,把之前的 uc_link 赋值改为 child.uc_link = NULL,然后我们再次运行代码,可以看到打印变成了:
contest_test
func1
因为没有设置后继上下文,所以程序在执行完 func1 之后就直接结束了。
三.如何实现协程?
上面的例子只是简单的实现了从 主协程->协程1->主协程 这样一条路径,这样的路径普通函数调用也能实现。下面我们会介绍中断协程和恢复协程如何实现。
实现协程我们首先需要定义两个结构,一个是协程,一个是协程的调度器。
我这里的定义参考了 coobjc 和 uthread 的作者。
协程的结构体定义如下:
typedef void (*entryFunc)(void *arg);
typedef struct coroutine
{
ucontext_t ctx; //当前协程的上下文,用于后继协程的存储
entryFunc func; //协程需要执行的函数
void *arg; // 函数的执行参数
enum ThreadState state; //协程的运行状态,包括 FREE、RUNNABLE、RUNING、SUSPEND 四种。
char stack[DEFAULT_STACK_SZIE]; //栈空间
struct coroutine_scheduler *scheduler; // 协程的调度器.
};
调度器的定义如下:
typedef std::vector Thread_vector; //使用 c++数组来装载协程对象
typedef struct coroutine_scheduler
{
ucontext_t main; // main的上下文
int running_thread; // 当前正在运行的协程编号,如果没有返回 -1
Thread_vector threads; //协程数组
schedule_t():running_thread(-1){}
}
还需要实现4个比较关键的方法。
int uthread_create(schedule_t &schedule,Fun func,void *arg):创建协程
int uthread_create(schedule_t &schedule,Fun func,void *arg)
{
int id = 0;
for(id = 0; id < schedule.max_index; ++id ){
if(schedule.threads[id].state == FREE){
break;
}
}
if (id == schedule.max_index) {
schedule.max_index++;
}
// 加入到协程队列
uthread_t *t = &(schedule.threads[id]);
//初始化协程结构体
t->state = RUNNABLE;
t->func = func;
t->arg = arg;
//设置协程的上下文
getcontext(&(t->ctx));
t->ctx.uc_stack.ss_sp = t->stack;
t->ctx.uc_stack.ss_size = DEFAULT_STACK_SZIE;
t->ctx.uc_stack.ss_flags = 0;
t->ctx.uc_link = &(schedule.main);
schedule.running_thread = id;
//
makecontext(&(t->ctx),(void (*)(void))(uthread_body),1,&schedule);
swapcontext(&(schedule.main), &(t->ctx));
return id;
}
void uthread_yield(schedule_t &schedule):挂起协程
void uthread_yield(schedule_t &schedule)
{
if(schedule.running_thread != -1 ){
uthread_t *t = &(schedule.threads[schedule.running_thread]);
t->state = SUSPEND;
schedule.running_thread = -1;
swapcontext(&(t->ctx),&(schedule.main));
}
}
void uthread_resume(schedule_t &schedule , int id):恢复协程
void uthread_resume(schedule_t &schedule , int id)
{
if(id < 0 || id >= schedule.max_index){
return;
}
uthread_t *t = &(schedule.threads[id]);
if (t->state == SUSPEND) {
swapcontext(&(schedule.main),&(t->ctx));
}
}
int schedule_finished(const schedule_t &schedule):所有协程执行完毕
int schedule_finished(const schedule_t &schedule)
{
if (schedule.running_thread != -1){
return 0;
}else{
for(int i = 0; i < schedule.max_index; ++i){
if(schedule.threads[i].state != FREE){
return 0;
}
}
}
return 1;
}
接下来用 uthread 里提供的例子来验证一下协程库的运行:
void func1(void * arg)
{
puts("1");
puts("11");
}
void func2(void * arg)
{
puts("22");
puts("22");
uthread_yield(*(schedule_t *)arg);
puts("22");
puts("22");
}
void func3(void *arg)
{
puts("3333");
puts("3333");
uthread_yield(*(schedule_t *)arg);
puts("3333");
puts("3333");
}
void context_test()
{
char stack[1024*128];
ucontext_t uc1,ucmain;
getcontext(&uc1);
uc1.uc_stack.ss_sp = stack;
uc1.uc_stack.ss_size = 1024*128;
uc1.uc_stack.ss_flags = 0;
uc1.uc_link = &ucmain;
makecontext(&uc1,(void (*)(void))func1,0);
swapcontext(&ucmain,&uc1);
puts("main");
}
void schedule_test()
{
schedule_t s;
int id1 = uthread_create(s,func3,&s);
int id2 = uthread_create(s,func2,&s);
while(!schedule_finished(s)){
uthread_resume(s,id2);
uthread_resume(s,id1);
}
puts("main over");
}
int main()
{
// 执行 主协程->子协程->主协程
context_test();
//主线程和子协程间任意切换
schedule_test();
return 0;
}
上面的 Demo 可以用下面的流程图来表示:
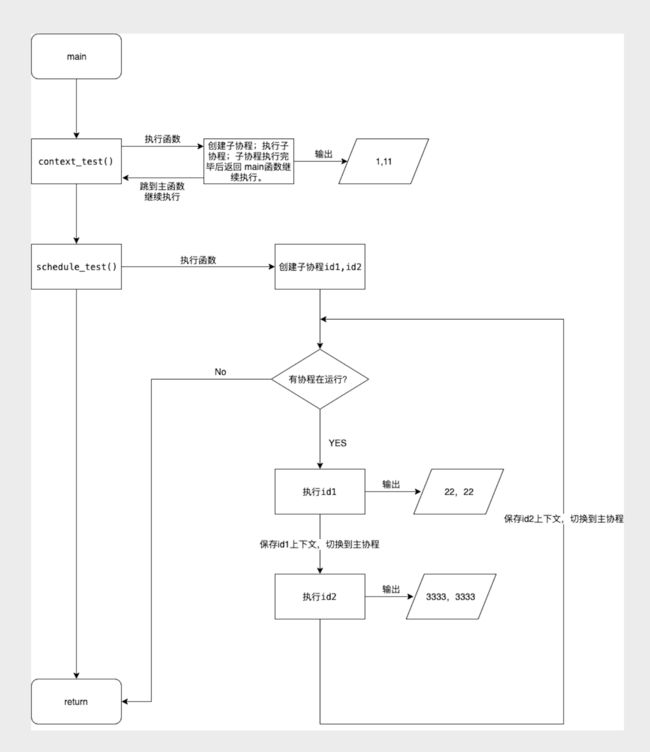
可以看到,在自己封装的协程库中,实现了主协程和子协程间的任意切换。并且切换之前都能保存当前的上下文,并不会从头开始执行。在这里其实就体现了文章一开始引用的维基百科中关于协程的介绍:「 协程可以通过 yield 中断执行,转而执行别的协程。在这种转换过程中不存在调用者与被调用者的关系」,这是函数调用所不能实现的。
总结
协程本身没有特别适用的场景,但是当搭配上多线程之后,协程的光芒渐渐显露出来。我们可以这么总结一下:协程的线程可以让我们的程序并发的跑,协程可以让并发程序跑得看起来更美好
不管是异步代码同步化,还是并发代码简洁化,协程的出现其实是为代码从计算机向人类思维的贴近提供了可能。
参考资料
刚刚,阿里开源 iOS 协程开发框架 coobjc!
基于协程的编程方式在移动端研发的思考及最佳实践
iOS协程coobjc的设计篇-栈切换
coobjc