一 为什么读这篇
doodle比赛刚结束,蛙神推荐的,论文在arxiv上才挂出来,第二天蛙神就分享了,佩服其信息获取能力。正如题目讲的,一包tricks,读这篇相当于读综述,学习一下图像分类问题里的技巧讨论。
二 截止阅读时这篇论文的引用次数
2018.12.9 0次。毕竟12月4号才出的
三 相关背景介绍
几个作者全部都是来自AWS的华人,其他几人不算很有名,不过最后一个作者是大名鼎鼎的百度少帅李沐。应该会安利不少MXNet。
四 关键词
Tricks
Large-batch
Linear scaling learning rate(线性缩放学习率)
Learning rate warmup(学习率热身)
FP32 FP16
Cosine Learning Rate Decay(余弦学习率衰减)
Label Smoothing(标签平滑)
Knowledge Distillation(知识蒸馏)
Mixup Training(混合训练)
五 论文的主要贡献
正如论文题目所说,提供一包tricks用于提升效果。模型架构很重要,但是训练技巧也不容忽视。
六 详细解读
1 介绍
(摘要)当前许多图像分类的研究可归功于训练过程的改进,例如改进数据增强和优化方法。然而在文献中,许多改进仅仅在实现细节中有简短的描述或在源码中才会出现。本文通过模型简化测试(ablation study)试验了一系列这些改进并评估他们对最终模型准确率的影响。通过联合这些改进策略,能够显著的改善不同的CNN模型。用这些策略把原始ResNet-50在ImageNet上的准确率从75.3%提升到79.29%。。
在ImageNet上的top-1准确率从62.5%(AlexNet)提升到82.7%(NASNet-A)。然而改进不单单来自模型架构,训练过程中的改进也扮演了很重要的角色,例如损失函数,数据预处理,优化方法等。这些方法受到的注意相对少些。通过本文的实验说明模型准确率的提升不仅仅是由计算复杂度的改变带来的。
此处安利GluonCV。

2 训练过程(baseline)

2.1 Baseline训练过程
用torch的做法来实现ResNet作为baseline。训练和测试阶段的预处理流水线是不同的,在训练阶段,采用如下做法:
https://github.com/dmlc/gluon-cv/blob/master/scripts/classification/imagenet/train_imagenet.py#L152
1 随机采样图像,将其从[0,255]原始像素值解码为32位浮点数。
2 随机裁剪纵横比在[3/4, 4/3]之间,面积在[8%, 100%]之间的矩形区域,然后将裁剪区域调整为224x224的方形图像。
3 用0.5的概率做水平翻转。
4 从[0.6, 1.4]之间均匀采样系数来缩放色调,饱和度,亮度。
5 增加PCA噪声,系数为正态分布中的采样。
6 归一化RGB通道。分别减123.68, 116.779, 103.939,然后除58.393, 57.12, 57.375
测试阶段,调整图像的短边为256,同时保留其纵横比。之后从中间裁剪出224x224,用训练阶段的方式归一化RGB通道,不做其他数据增强。
卷积和FC层用Xavier的方式初始化。偏置都初始化为0。对于BN层,向量初始化为1,向量初始化为0。
用NAG(Nesterov Accelerated Gradient)做梯度下降。每个模型训练120个epoch,batch_size为256,在8卡的V100上。学习率初始为0.1,在30th, 60th, 90th epoch的时候分别除10。
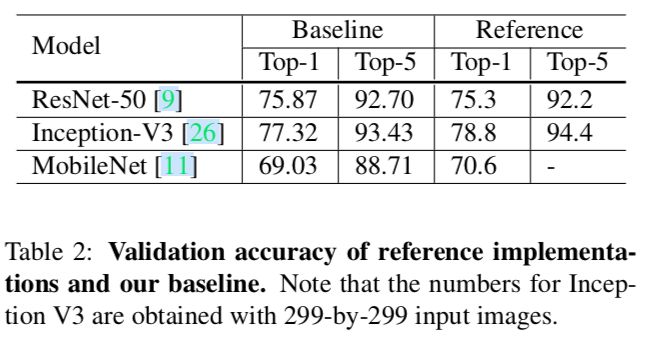
2.2 实验结果
3 更有效的训练
当前由于硬件的发展可以用更大的batch,更低的数值精度来训练。一些技术甚至能同时提高准确率和训练速度。
3.1 Large-batch 训练
对于同样个数的epoch,大的batch_size效果不如小的batch_size。可以用以下启发式方法来解决这个问题。
Linear scaling learning rate(线性缩放学习率)
增加batch_size并不能改变样本选择的随机性,但是能减小方差,也就是说更大的batch_size能够减少梯度的噪声。如果初始学习率为0.1,batch_size为256,我们的batch_size定义为b,那么学习率可以增加为0.1 * b/256。
Learning rate warmup(学习率热身)
训练刚开始时所有参数都是随机值,离最终方案还很远。使用太大的学习率也许会导致数值不稳定。用热身策略,可以在刚开始用小的学习率当训练稳定后再切换为初始学习率。"1小时训练imagenet"提出的策略是从0开始线性增加学习率直到初始学习率。
假设用前m个(如5个epoch)batch用于热身,初始学习率定义为,那么每个batch ,将学习率设置为。
Zero
ResNet的残差块的最后一层为BN时,BN层首先标准化其输入,定义为,然后执行缩放变换。当令时,缩小了网络的层数,因此在初始阶段更容易训练。(???)
No bias decay
在"14分钟训练imagenet"提出的策略是weight decay只用于卷积层和FC的weights,biases和BN层的和都不用。
因为本文提出的是限制在单机上训练的方法,所以batch_size不会超过2k。
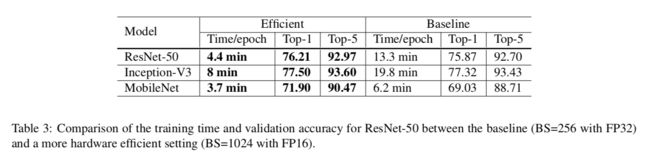
3.2 Low-precision 训练
通常神经网络都是用32位浮点型(FP32)精度训练,也就是说存储和运算都是用FP32。然而当前的新硬件支持更低精度的数据类型。比如V100用FP32能提供14TFLOPS,但是用FP16能提供100TFLOPS。。。表3说明FP16比FP32有2到3倍的加速。不过准确率提升不是因为FP16。
尽管有性能上的提升,减少精度也有可能因为其数值范围的缩小导致训练出错。mixed precision方法用于解决这个问题。存储所有的参数和激活用FP16,并用FP16计算梯度,同时存储所有参数的FP32用于参数更新。另外实践上,也经常乘一个标量给loss用于更好的对齐梯度为FP16。
3.3 实验结果
见表3和表4。不过加上No bias decay,明显是效果下降了,不知道为什么没提及这点。

4 模型调整
对网络架构的轻微调整通常不会改变计算复杂性,但可能对模型精度产生不可忽视的影响
4.1 ResNet架构
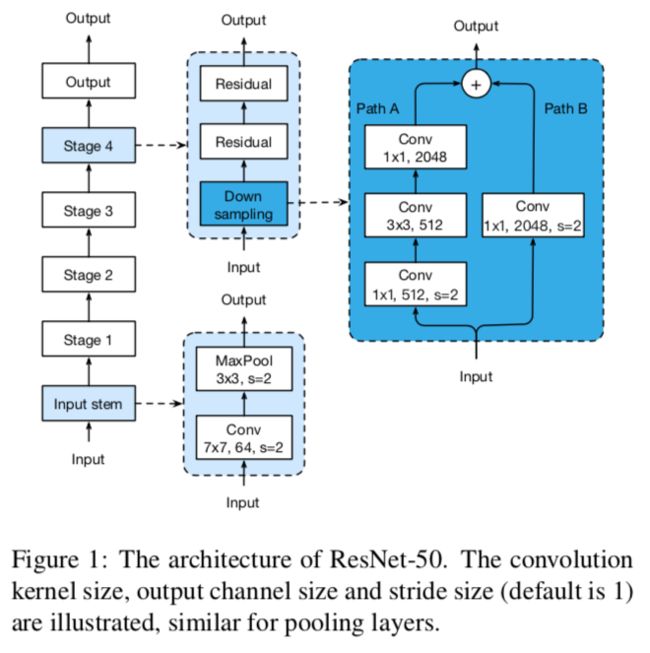
参考原作的图
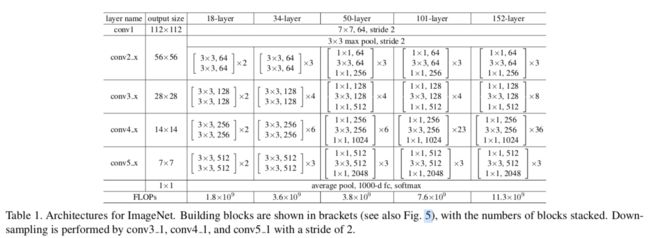
4.2 ResNet调整
ResNet-B
改的是图1的Down sampling部分。该调整最早在torch的实现中出现,后来也被1hour,se-net,resnext采用。修改点是ResNet的下采样块。如图,因为原作使用1x1,stride=2的卷积导致path A忽略了3/4的输入特征图,所以把stride=2往后挪到3x3的卷积。蓝色的地方是做了修改的。
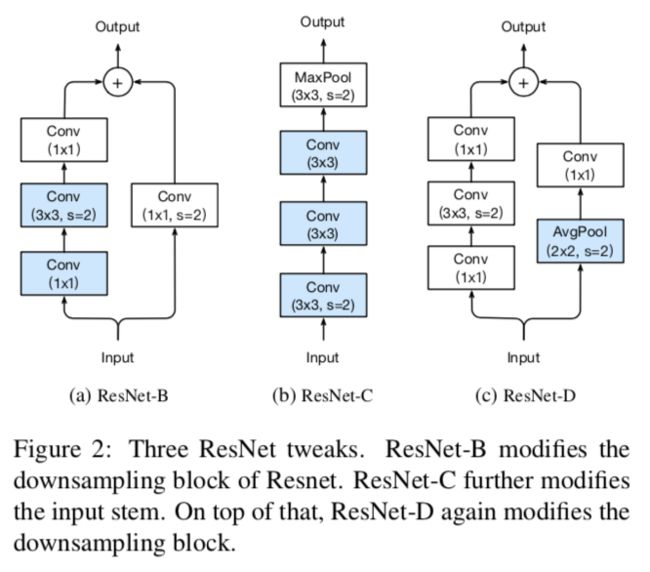
ResNet-C
改的是图1的Input stem部分。该调整最早由Inception-v2提出,后来也在SENet,PSPNet,DeepLabV3和ShuffleNetV2中使用。观察结果是卷积的计算成本是内核宽度或高度的二次方。7x7卷积比3x3卷积代价高5.4倍(49/9)。所做的修改是把7x7卷积用3个3x3卷积代替。前两个输出通道为32,第三个输出通道为64。
ResNet-D
这是由本文提出的。受ResNet-B的启发,发现下采样块中path B的1x1卷积也忽略了3/4的特征图,所以改它。在1x1卷积前加一个2x2的avgpool,stride=2,原来1x1卷积的stride从2改为1。这样的修改效果不错且只影响一点计算代价。
4.3 实验结果
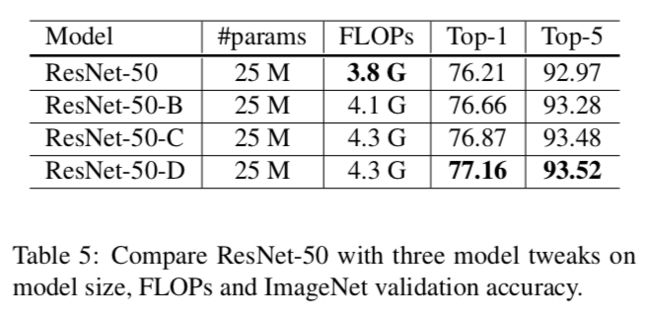
实验是基于第三部分的设置,即batch_size为1024,用FP16。相比原始ResNet-50,最后的ResNet-D提升了接近1%。不过在实践中,发现比原来慢3%。(差0.5G就慢这么多。。)
5 训练改进
5.1 Cosine Learning Rate Decay(余弦学习率衰减)
学习率的调整对训练至关重要。在用warmup策略后,通常会稳步降低初始学习率的值。被广泛使用的是指数衰减学习率。ResNet中用的是每30个epoch降低0.1,我们称之为『step decay』。Inception中用的是每2个epoch降低0.94。
余弦退火策略是2016年提出来的,简化版本是把学习率从初始值降低到0。
其中是总batch数,是当前batch索引,是初始学习率。
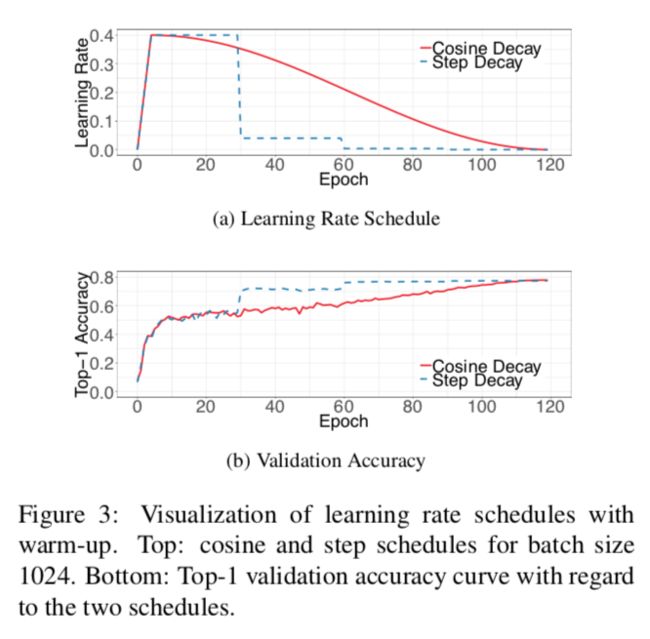
从上图可以看出,起初余弦衰减的学习率缓慢下降,在中间部分几乎是线性下降,在最后又缓慢下降。(不过从最后的准确率来看,余弦衰减似乎并无优势,也没有加速收敛?)
5.2 Label Smoothing(标签平滑)
softmax公式,其中为标签个数,为预测类别的分数,为softmax操作的输出。
负交叉熵损失公式,其中为真实概率分布,当对了为1,不对为0。(原文这里的公式好像写错了,p和q的地方放反了)
训练期间,通过最小化该损失来更新模型参数从而让两个概率分布彼此近似。特别地,说一下如何构造,我们知道。优化解是,同时保持其他值很小。换句话说,这样做也鼓励输出的分数有显著区别,从而可能导致过拟合(通过softmax学到的模型太自信了)。
标签平滑的思路来自2015年提出的Inception-v2。它将构造的真实分布改为
其中为一个很小的常量。现在优化解变为
其中为任意实数。这鼓励FC层为有限输出,从而泛化的更好。
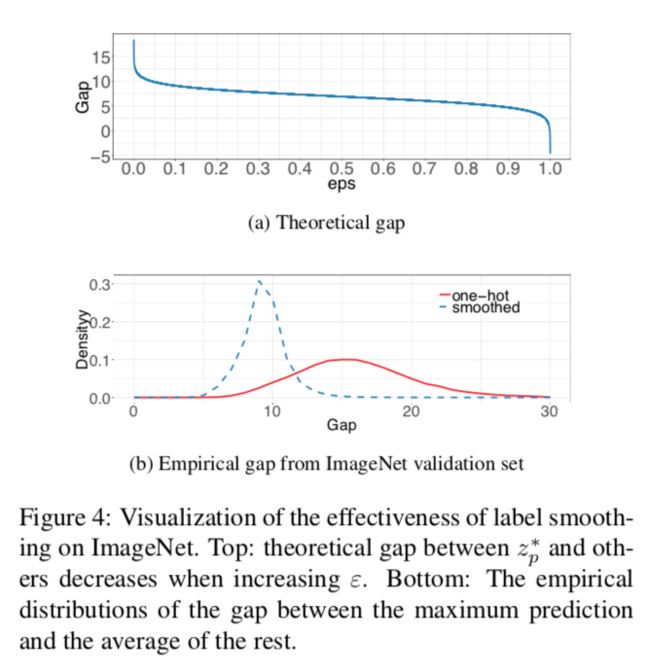
从上图可以看出标签平滑的分布中心更接近理论值同时其极值更少。
插播一个知乎:神经网络中的label smooth为什么没有火?
5.3 Knowledge Distillation(知识蒸馏)
Hinton在2015年提出的。用老师模型帮助当前的模型(学生模型)。老师模型通常是有很高准确率的预训练模型,通过模仿,学生模型能提升自己的准确率同时保持其模型复杂度。
在训练期间,增加一个蒸馏损失来惩罚老师模型和学生模型的softmax输出之间的差异。给定一个输入,定义为真实概率分布,和分别为学生模型和老师模型最后FC层的输出。
之前用损失来衡量和之间的差异,这里使用同样的损失用于蒸馏。此时,损失改为
其中为一个称为温度的超参,来使softmax的输出更平滑。
5.4 Mixup Training(混合训练)
2017年提出的mixup。每次随机选两个样本对和。然后通过权重线性插值合成一个新的样本对。
其中是取自分布的随机数。在mixup训练中,只用新样本。
这里有一作在知乎的回答。
5.5 实验结果
设置用于标签平滑,用于模型蒸馏,具体来说用加上余弦衰减和标签平滑的预训练的ResNet-152-D模型作为老师。在mixup训练中,选择作为Beta分布,同时增加epoch个数从120到200,因为混合样本需要更久的训练才能闭合。当用mixup训练知识蒸馏时,老师模型也用mixup。
效果如预期一样在ResNet-50-D,Inception-V3,MobileNet3个模型上都有提升,但是蒸馏只在ResNet上有效,事后给出的解释是老师模型和学生不是一个家族的,因此对于预测有不一样的分布,所以反而给模型带来负面影响。。

6 迁移学习
6.1 目标检测
把Faster-RCNN的VGG-19基模型用前面提到的各种预训练模型替换,其他设置保持一致。mAP在VOC2007上最终有4%的提升。

6.2 语义分割
用的FCN,这里是负面效果。除了余弦退火策略显著提升效果外,其他效果都不好。给出的解释是语义分割预测的是像素级别,而用标签平滑,蒸馏和mixup有利于软化标签,模糊的像素级信息可能会模糊并降低整体的像素级准确率。

7 总结
介绍的这些技巧对模型架构,数据预处理,损失函数和学习率调度做了轻微的修改。用ResNet-50,Inception-V3,MobileNet做实验后效果都得到了提升,而且加在一起用能明显的提升准确率。另外,迁移到目标检测和语义分割效果也有提升。
七 读后感
并不一定要拿当前最新最好的模型作为改进对象,用经典的也行。本文的分类网络用的就是ResNet-50,目标检测用的是Faster-RCNN,语义分割用的是FCN,三者都是15年的模型。
各种黑科技的作用不容小觑,累加着用总能提升,不过有的很明显,有的作用就没那么大。作为对比,mixup的效果就碉堡了,而知识蒸馏的提升则没那么明显(hinton挂一作也没用。。。)
另外,本文好像没有什么创新的地方(除了修改模型变为ResNet-D那一点),看来,实验做好,也是可以发paper的。。
八 补充
看这篇,也是讲技巧的
A disciplined approach to neural network hyper-parameters: Part 1 -- learning rate, batch size, momentum, and weight decay