
互联网金融和大数据是最近特别热的两个方向,而其中大数据发展最快的商业化应用就是在互联网金融中用于风险控制,简称为大数据风控。
大数据风控领域里也有很多细分方向的产品,其中通过数据挖掘对个人信用数据进行分析,为互联网金融机构提供个人征信服务的产品,就是大数据征信产品。
最近刚好有机会对大数据征信产品做下快速的市场调研,虽然理解的还比较浅,但是对于像我一样外行的朋友,总能有些帮助。
为了更好地理解为什么会需要大数据征信产品,首先要知道传统征信机构存在什么问题。
传统征信机构的局限
以央行的征信系统为代表,传统征信机构通过商业银行、其它社会机构上报的数据,结合身份认证中心的身份审核,提供给银行系统信用查询和提供给个人信用报告。
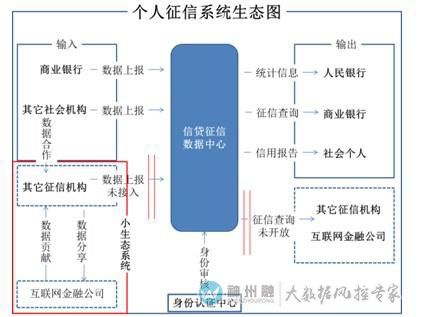
1. 存在大量信用“白板”用户
央行征信系统有大概8亿人档案,其中只有不到3亿人有过银行或其他金融机构发生过借贷的记录。
2. 征信数据纬度单一,来源缺乏
没有完全接纳个人的社保、保险、教育、房产、车辆等信息,数据主要来自银行体系及少部分小贷公司提供,但不接入民间借贷信息
3. 半封闭式获取,信息无法及时更新
数据上报机构缺乏积极性,数据获取方式非常被动,导致数据来自某个时点的快照,因此无法有效交叉验证
对于互联网金融机构而言,需要解决的问题更多。
互联网金融机构的困境
以P2P网贷为典型,互联网金融机构发展迅速,数据显示2015年全国P2P网贷平台每月资金成交量超过160亿,数量超过3000家,有效投资人达到50万。
但是P2P网贷在风险管理上仍然非常混乱,坏账和逾期率都无法控制,而造成问题的主要原因是缺乏个人征信的有效手段。
1. 没有纳入央行征信系统
央行征信系统对于其它征信机构和互联金融公司目前不提供直接查询服务。
2. 客户覆盖范围存在偏差。
互联网金融机构的客户有很大比例是传统征信中的“白板”用户,而这些客户是传统征信中的盲区。
因此P2P网贷平台只能依靠第三方征信机构,
第三方征信机构该如何解决个人征信的问题呢?美国互联网金融行业已经发展成熟,因此最容易想到的解决方案当然是借鉴美国的。
FICO和ZestFinance
长期以来美国金融机构用FICO作为一个重要的变量指标来衡量个人信用风险。美国个人信用数据库较全面,一般存储有最近7-10年的个人信用记录。但是美国仍有25%的人没有征信记录,在面对这些次级客户时,FICO评分指标起不到特别好的甄别作用。
而ZestFinance正是面向无账户人群,信用数据不足和信用记录不好的人群,通过大数据挖掘和机器学习,采用十个模型,从不同角度进行计算,给出个人信用评分。ZestFinance的核心是来自Google的大数据模型。特别的,ZestFinance主要还是采用结构化和类结构化的数据,来源主要是从数据代理商处购买,从未将社交网络数据纳入模型。
问题是ZestFinance的模式真的完全适用国内征信行业吗?
大数据征信和本土化
ZestFinance似乎给出了个人征信的解决方案:大数据征信。大数据征信通过获得多渠道的大数据原料,利用数学运算和统计学的模型进行分析,从而评估出借款者的信用风险。
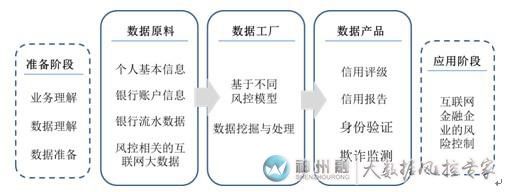
国内征信问题的差异
美国征信体系完善,信用数据相对全面,ZestFinance在数据获取的途径上没有障碍,因此其核心是数据挖掘和建立模型。
然而,国内征信体系不成熟,大数据征信在本土化过程中首要解决的问题是数据原料的获取。那么国内现有第三方征信机构发展情况如何?
国内第三方征信机构
2015年央行公布了首批获得个人征信牌照的8家机构名单。这些机构一个特点是征信机构本身亦是“数据制造者”。比如阿里的风控模式,他们通过自身系统大量的电商交易以及支付信息数据建立了封闭系统的信用评级和风控模型。除此之外,还有众多中小互联网金融公司通过贡献数据给一个中间征信机构,再分享征信信息。
1. 芝麻信用:依托阿里电商系的交易数据闭环,构建以芝麻分为核心的征信服务平台。
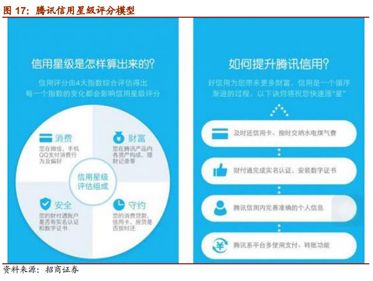
2. 腾讯征信:腾讯多维度的产品线同样构建以社交关系行为为核心的征信体系
3. 考拉征信:考拉征信有老牌三方支付拉卡拉的数据,数据优势在于大量的真实线下还款交易及其他交易。
4. 中智诚:曾服务于8家商业银行联盟的反欺诈咨询,并与8家联盟银行的数据实现共享,有基于反欺诈的评分服务
5. 中诚信:中诚信从2003年起开始布局征信也,比央行征信起步还早,前期积累了大量企业信息,和企业主信息。
6. 前海:平安从2013年开始筹备征信事业部,银行+保险的模式获取了大量金融服务的客户数据。
7. 鹏元:老牌征信提供商,在深圳广州有非常深入的金融征信数据,几乎覆盖了深圳地区所有的小贷公司数据。
8. 华道征信:华道征信有深厚的大型企业资源,在获取独占数据上有一定优势。
总体来说,国内征信机构在数据获取阶段中存在两个问题:1. 数据纬度单一,数据多来自关联业务。2. 数据无法共享,形成信息孤岛。
授权爬取多纬度数据
真正的第三方征信机构需要能进行多纬度征信数据的获取。
聚信立给出的解决方案是用户授权爬取:通过借款人授权,利用网页极速抓取技术获取各类用户个人数据,通过海量数据比对和分析,交叉验证,最终为金融机构提供用户的风险分析判断。聚信立2016年1月获得京东B轮投资,同时京东也是ZestFinance的投资者。聚信立此轮融资后,数据获取和处理能力将会进一步提升。
聚信立报告的四个维度包括:
1. 信息验真:通过交叉比对验证用户是否是真实存在的人,是否有欺诈风险。
2. 运营商数据:分析用户生活、工作及社交范围,与家人朋友的联系频率等。
3. 电商数据:分析用户消费能力及消费习惯,判断用户是否有能力还款。
4. 其他数据:包括公积金社保数据、学信网数据、全国高法执行名单、黑名单等数据,判断用户是否存在欺诈风险。
授权爬取是目前看来能够解决多纬度数据获取问题的方法,而对于信息孤岛问题,同样有机构在尝试新的解决方案。
P2P分布连接信息孤岛
蜜蜂数据的解决方案是P2P分布数据库:各平台自行管理自有数据,无需中央数据库;系统仅负责通讯、对接,不对任何征信数据进行持久化存储;统一数据标准和接口,提供灵活、弹性的数据扩展 ;按需查询、按实际效果付费,数据被查询获得收益 。 蜜蜂数据2015年6月B轮融资,目前已经超过500家合作P2P平台。
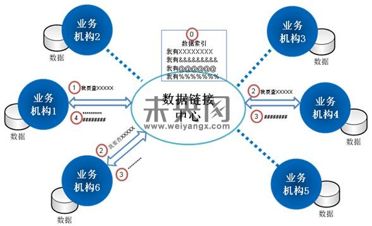
P2P分布式数据库能实现金融机构之间的纯粹、完整、无交叉的强属性数据自由、快速共享,加速行业发展,但是需要避免数据同质化。
换个角度来思考,互联网中存在着海量的社交数据,如果我们能够从社交数据中挖掘出有效的信息呢?首先想到的自然是腾讯。
非结构化数据的挖掘
如果能从社交数据中挖掘出更有价值的信息,将解决个人信用数据缺乏的情况。但是从社交等非结构化数据中挖掘信息目前尚有困难。因此现在的腾讯征信模型中并没有引入社交数据。
进展
腾讯征信正在积极应用新技术进行研究和验证,社交数据的信贷应用在全球范围内都是很前沿的探索。腾讯模型研究团队的初步成功已显示,社交数据可以明显提升个人征信的准确性。
前景
腾讯拥有的海量社交数据将来会为个人征信机构带来更丰富的数据纬度,但是目前腾讯征信并未使用到用户的社交数据。同时考虑到个人隐私的问题,社交数据易伪造,数据清洗难度高,其前景仍然不明朗。
写在最后
目前看来,大数据征信行业还是刚刚起步,市场天花板很高,竞争也会日趋激烈,同时先进入的不一定是最后的赢家,关键还是要更懂中国,更符合国情。
本文属原创内容,转载前须经过本人同意。