机器学习从概念上来说很有趣,但同时,对于初学者来说也很难理解。要掌握和理解基础数学和逻辑,需要付出很多努力。但幸运的是,在线上有许多工具可以成倍地减少这些工作。其中之一是Google Cloud AutoML。
AutoML是一套机器学习产品,可使拥有有限机器学习专门知识的开发人员可以针对其业务需求训练高质量模型。用技术术语来说,它是可以设计神经网络的神经网络。
这篇文章将重点介绍如何使用Google Cloud AutoML Vision Edge从头开始训练自定义机器学习模型。
1.什么是基于边缘的模型?
AutoML Vision Edge允许您训练和部署针对边缘设备优化的低延迟,高精度模型。
训练后,可以使用AutoML提供的各种格式使用模型,例如TF Lite,Core ML,Tensorflow.js和其他容器导出格式。这篇文章将涵盖培训和使用基于AutoML Edge的模型的TF Lite格式。
2.准备数据集并训练基于边缘的模型
2.1获得一个好的数据集
数据集是机器学习的基础。准备数据集是培训之前的关键步骤。
有两种方法可以获取可行的数据集-可以使用互联网上现有的数据集(即适用于一般用例),也可以为特定用例创建自己的数据集。
为此,作者编写了一个简单的脚本,该脚本将有助于从Pexels网站上抓取图片,该网站上有1000张免费的高质量照片。
爬虫地址:
https://github.com/aayusharora/LazySpider/
一个简单的用AutoML进行试验的用例将是一个基本的图像分类问题:识别狗还是猫。互联网上可以找到许多猫和狗的图像,也可以从各种网站(例如Pexels)轻松地将它们抓取。
2.2问题:将照片分类为猫和狗类
步骤1:从Pexels抓取并创建数据集
通过使用Pexels,我们可以提取所需的所有猫狗图像。使用上述脚本,我们只需要按如下所示将spider.py中的关键字“ cat”和“ dog”更改为:
keyword = 'dog'
url = "https://www.pexels.com/search/" + keyword
然后使用以下命令运行Python脚本:
python spider.py
该脚本使用Selenium将所有图像延迟加载到浏览器窗口中,然后再将它们下载到_images文件夹中。
步骤2:清理资料集
该步骤通常被忽略,但是对于获得良好的准确性而言,这是非常重要的。确保数据集有一个名为“ dogs”的文件夹,另一个名为“ cats”的文件夹,分别包含其图像。
该目录应如下所示:

注意:两个文件夹都应至少包含100张图像,以便AutoML开始模型训练。
步骤3:建立Google Cloud案例
准备好干净的数据集后,我们可以开始设置Google Cloud项目。
我们可以按照此指南创建Google Cloud项目:
https://cloud.google.com/dataproc/docs/guides/setup-project
下一步是在AutoML页面上创建我们的数据集。如您在快照中所见,在这里,我们将使用单标签分类。当图像可以属于一个类别时,使用单标签分类。在我们的猫与狗问题中,每张图像都将被标记为猫还是狗,即单级标签。在多标签分类中,单个图像可以同时属于多个类别。
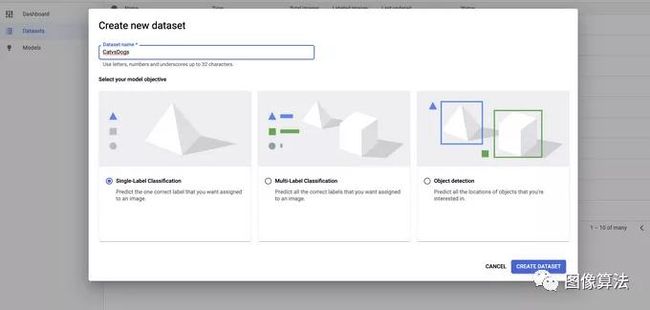
步骤4:导入所有图片
完成初始项目设置后,我们将使用“导入”按钮,并导入dog和cat文件夹及其各自的图像。
注意:最佳做法是将所有图像上传到Google Cloud Storage Bucket,然后从AutoML仪表板导入存储。
上传后,我们可以在“图片”标签下看到所有图片:

步骤5:开始进行模型训练
一旦看到在AutoML仪表板中反映出猫和狗的图像,我们就可以开始训练我们的模型了:D
使用AutoML训练此模型非常容易,请转到“训练”选项卡,然后单击“训练新模型”。 训练完成后,我们会收到一封电子邮件通知。
在训练之前,您应该决定如何使用模型(作为API(在线预测)或在边缘设备(离线预测)上使用)。在线预测是测试结果的最佳方法,或者是您要直接通过AutoML API使用模型的最佳方法。他们更准确。离线模型可以节省大量成本,并且可以在设备上运行。它们通常较小,并且可以在没有互联网连接的情况下运行。
步骤6:评估模型
在评估模型之前,我们应该了解精度和召回率的含义。精度是指您相关结果中所占的百分比。另一方面,召回率是指按算法正确分类的所有相关结果中的百分比。您可以在此处了解更多有关精度和召回的信息
在仪表板上查看我们CatVsDog模型的召回率和精度值。

步骤7:测试模型
该模型将在1–8小时之间的任何时间进行训练,具体取决于数据集中的图像数量。您可以在“测试和使用”选项卡中测试图像。
默认情况下,AutoML将数据集随机分为以下3组:
测试数据集:用于对训练数据集上的最终模型拟合进行评估的数据样本。80%的图像用于训练。
训练数据集:用于训练模型的数据样本。10%的图像用于超参数调整和/或决定何时停止训练。
验证数据集:数据样本,用于在调整模型超参数时对训练数据集上的模型拟合进行评估。10%的图像用于评估模型。这些图像未在训练中使用。

3.离线使用TensorFlow Lite(.tflite)模型
如果我们想离线使用模型(无论是在Android,iOS,任何桌面应用还是在边缘设备上),我们都需要一个.tflite版本的模型,这是常见的移动和边缘用例的模型版本。
要导出模型,我们必须单击Tf Lite卡并选择一个Google Cloud Bucket来导出它。
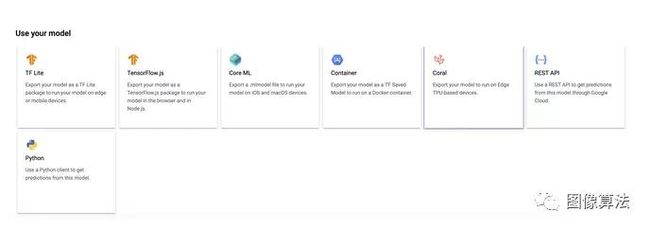
将模型导出到Google Cloud存储桶后,您将可以看到一个.dict文件,其中包含模型的类名以及一个JSON文件,其中解释了图像的输入和输出形状。词典文件是您的类名的词典。它包含将由TensorFlow Lite模型预测其分数/置信度的类名称。
JSON文件可帮助我们了解可接受的输入类型以及有关模型的其他信息。
例如:在这里,字典文件将包含两个类dog和cat。当运行下面提到的代码时,我们将得到图片的信心分别是猫还是狗。
import numpy as np
import tensorflow as tf
import cv2 as cv
import os
import random# Load TFLite model and allocate tensors.interpreter = tf.lite.Interpreter(model_path="Your Model Path")interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()dim = (224, 224) // From request.json
img = cv.resize(img,dim)
img = img.reshape(1,224,224,3 ) // From request.jsoninput_data = np.array(img, dtype=np.uint8)interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()output_data = interpreter.get_tensor(output_details[0]['index'])print(output_data)
您的output_data将包含图像的类名称和准确性得分。我们的数据集的准确度达到93.2%,对于大多数基本用例而言,这是很好的选择。
结论
AutoML它确实伴随着不可避免的在线预测成本。但是如果您离线(即在设备上)使用模型,则无需支付任何费用。
AutoML非常适合分类问题,也非常适合希望使用ML解决实际问题的初学者。
更多论文地址源码下载地址:关注“图像算法”微信公众号