这里是「王喆的机器学习笔记」的第二十七篇文章。这篇文章我们与大家讨论的是Facebook于2019年5月份分享的深度学习推荐系统论文《Deep Learning Recommendation Model for Personalization and Recommendation Systems》。
其实Facebook在2014年发表GBDT+LR的那篇论文之后,就鲜有知名的推荐系统相关论文流出,这篇文章也让我们能对Facebook近期的推荐系统研究进展有所了解。如果用一个词来概括这篇文章,那就是“浓浓的工业风”。看完这篇文章之后,感觉不能算是一篇学术论文,更像是一篇业界分享总结。
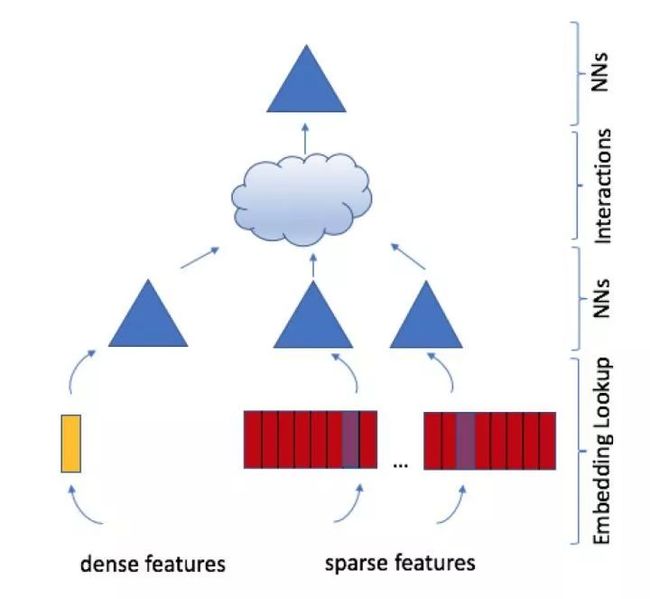
大家见过如此“简练”的五颜六色的深度学习模型结构图吗?
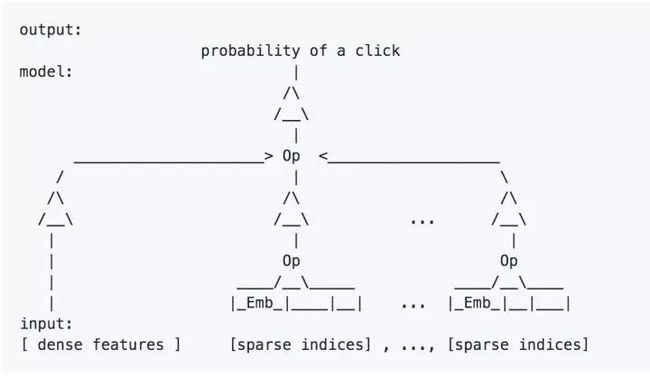
更简练点,大家见过ascii字符画版的模型结构图吗?
大家见过文章一开始就称自己是State of the art的深度学习模型吗?
In this paper, we develop astate-of-the-artdeep learning recommendation model (DLRM)
虽然DLRM这篇文章有一些这样那样的问题,但作为一名工程师,我还蛮喜欢这样的风格的,简单、直接、开源、不故弄玄虚。我曾经说过本专栏的目的就是分享业界前沿的,经典的推荐系统知识,facebook这篇文章也许不能算是最前沿的推荐系统尝试,但就我来说,它为我们介绍了一个经典的,标准的,符合业界趋势的深度学习推荐系统模型应该如何构建。所以我仍要说DLRM这篇文章是每一个从业者应该看一看的经典文章。
Facebook 深度学习推荐系统模型结构
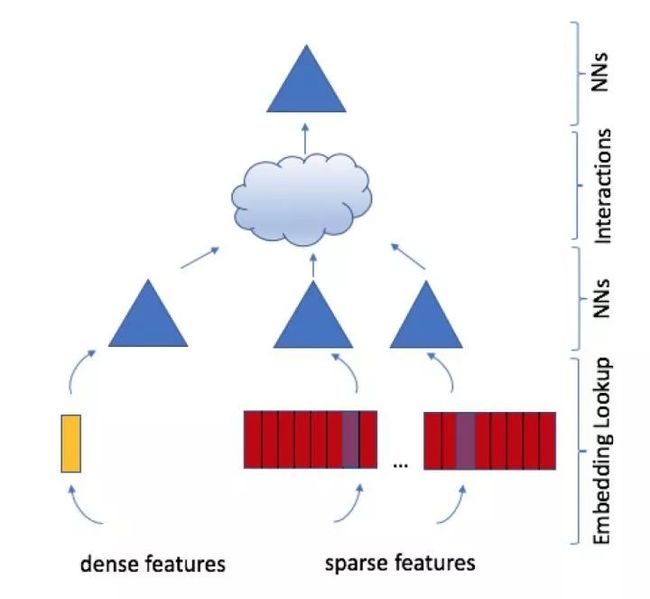
Facebook 深度学习推荐系统模型结构
从下到上来解释一下Facebook DLRM这个模型的模型结构:
·特征工程:所有特征被分为两类,一类是将类别、id类特征用one hot编码生成的稀疏特征(sparse features),一类是数值型连续特征(dense features)
·Embedding层:每个类别类特征转换成one hot vector后,用embedding层转换成维度为n的embedding。也就是说,每种稀疏特征转换成一个embedding向量。而年龄、收入等连续型特征将被concat称一个特征向量后,输入图中黄色的MLP(Multi Layer Perceptron)中,被转化成同样维度为n的向量。至此,无论是类别类稀疏特征,还是连续型特征组成的特征向量在经过Embedding层后,都被转换成了n维的embedding向量。
·NNs层:Embedding再往上是由三角形代表的MLP神经网络层,也就是说得到n维的embedding 向量后,每类embedding还有可能进一步通过MLP做转换,原文中这么说的“ optionally passing them through MLPs”,就是说选择性的通过MLP做进一步转换,看来那三个三角形其实是根据调参情况可有可无的。
·interactions层:这一层其实这篇文章相对还算创新的一点,它是怎么做的呢?原文这么说的:
This is done by taking the dot product between all pairs of embedding vectors and processed dense features. These dot products are concatenated with the original processed dense features and post-processed with another MLP (the top or output MLP)
也就是说会讲之前的embedding两两做点积,做完之后在跟之前dense features对应的embedding concat起来,喂给后续的MLP。所以这一步其实是希望特征之间做充分的交叉,组合之后,再进入上层MLP做最终的目标拟合。这一点其实follow了FM的特征交叉概念。
·最上层那个三角不用多说,是另一个FC NN,并最终用sigmoid函数给出最终的点击率预估。
整个模型看下来,没有特别fancy的结构,也没有加入sequential model,RF等模型的思路,可以说是一个工业界的标准深度学习模型。facebook的博客上还给出了稍微详细一点的模型结构图,大家可以参考。
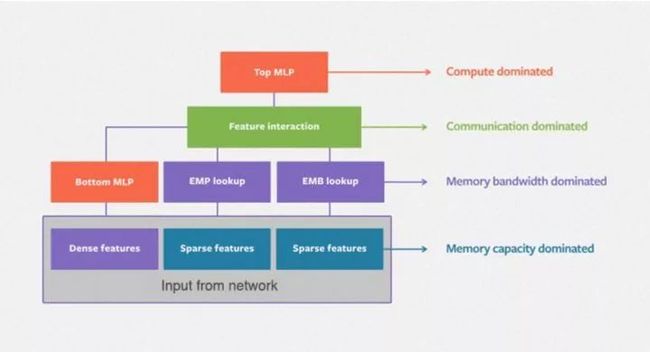
DLRM模型结构
Facebook的模型并行训练方法
作为一篇业界的论文,模型的实际训练方法,训练平台往往是让人受益最多的。而对于Facebook的数据量来说,单节点的模型训练必然无法快速完成任务,那么模型的并行训练就肯定是少不了的解决方法。我们先看原文是如何解释DLRM这个模型的并行训练过程的:
Our parallelized DLRM will use a combination of model parallelism for the embeddings and data parallelism for the MLPs to mitigate the memory bottleneck produced by the embeddings while parallelizing the forward and backward propagations over the MLPs.
简单来说,DLRM融合使用了模型并行和数据并行的方法,对于Embedding部分采用了模型并行,对于MLP部分采用了数据并行。Embedding部分采用模型并行的原因是减轻大量Embedding参数带来的内存瓶颈问题。MLP部分采用数据并行是可以并行进行前向和反向传播。
其实原文中并没有给出非常准确的并行训练方法,这里凭我自己的理解进一步解释一下Embedding做模型并行训练和上层MLP做数据并行训练的原理,对pytorch和caffe2熟悉的专家可以随时纠正我的解释:
·Embedding做模型并行训练指的是在一个device或者说计算节点上,仅有一部分Embedding层参数,每个device进行并行mini batch梯度更新时,仅更新自己节点上的部分Embedding层参数。
·MLP层和interactions进行数据并行训练指的是每个device上已经有了全部模型参数,每个device上利用部分数据计算gradient,再利用allreduce的方法汇总所有梯度进行参数更新。

模型并行训练示意图
DLRM模型的效果
DLRM的训练是在Facebook自研的AI平台Big Basin platform上进行,具体的配置是Dual Socket Intel Xeon 6138 CPU@ 2.00GHz and eight Nvidia Tesla V100 16GB GPUs

Facebook Big Basin AI硬件平台
总之,是一个高性能的CPU+GPU的组合,没有采用分布式的硬件架构。
在性能的对比上,DLRM选择了Google 2017年的DCN(Deep cross network)作为baseline。
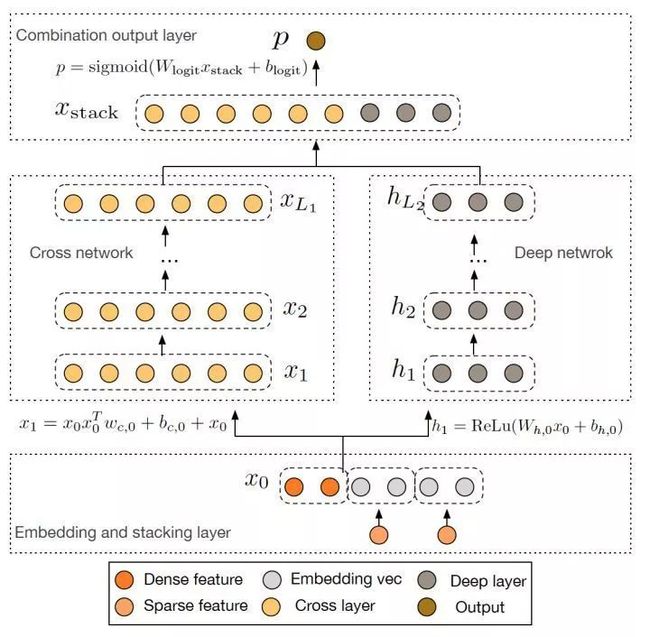
Google DCN模型结构
DCN可以看作是对Wide&Deep模型的进一步改进,主要的思路使用Cross网络替代了原来的Wide部分。其中设计Cross网络的基本动机是为了增加特征之间的交互力度,使用多层cross layer对输入向量进行特征交叉。单层cross layer的基本操作是将cross layer的输入向量xl与原始的输入向量x0进行交叉,并加入bias向量和原始xl输入向量。
可以看出DLRM和DCN的主要区别在于特征交叉方式的不同,DLRM采用了不同特征域两两点积的交叉方式,DCN采用了每个维度两两交叉的方式。利用Criteo Ad Kaggle data作为测试集,二者的性能对比如下:

DLRM与DCN性能对比
可以看到,DLRM在Accuracy上稍胜一筹。当然模型的performance与数据集的选择,参数的调优都有很大关系。而且DLRM在Adagrad训练方式下的优势已经微乎其微,这里的性能评估大家仅做参考即可。
总结
无论是之前GBDT+LR那篇文章,还是这篇DLRM,Facebook的文章总给人非常工业化的感觉,简单暴力,直入主题。虽然有不严谨之处,但对于业界借鉴经验来说已经完全够用了。DLRM这个模型也是非常标准且实用的深度学习推荐模型。如果大家刚开始从传统机器学习模型转到深度学习模型,完全可以采用DLRM作为标准实现。
PS:Facebook最近接连发生了一些不愉快的事情,作为同行有很多感同身受之处。希望在大家工作学习之余,还是要积极调整心态,世上的模型学不完,世上的工作也没有完美的,如果真的压力太大,就停下来,歇一会再继续。希望大家能工作愉快。
这里是「王喆的机器学习笔记」的第二十七篇文章。
认为文章有价值的同学,欢迎关注我的微信公众号:王喆的机器学习笔记(wangzhenotes),跟踪计算广告、推荐系统等机器学习领域前沿。
想进一步交流的同学也可以通过公众号加我的微信一同探讨技术问题,谢谢。
参考资料:
1.https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep-learning-recommendation-model/
2.https://github.com/facebookresearch/dlrm
3.https://arxiv.org/pdf/1906.00091.pdf
—END—

每周关注计算广告、推荐系统和其他机器学习前沿文章,欢迎关注王喆的机器学习笔记