(一)进入spark-shell命令界面(默认使用scala的命令界面)
1,如果进入了spark安装目录则使用、
1,一台机器启动spark:./bin/spark-shell --master
2,集群下启动spark:spark://主机IP:7077(默认端口)
3,在CLASSPATH中添加jar包:./bin/spark-shell --master local[4] --jars code.jar
4,退出:(:quit)
2,Yarn集群模式:
yarn-client:客户端电脑不能关,调试阶段
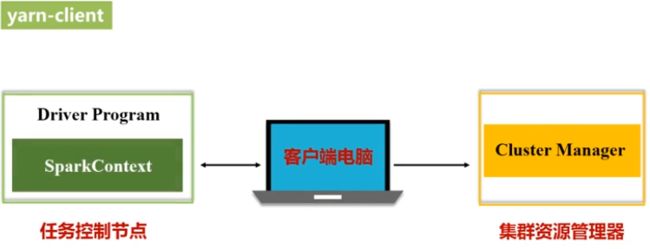
yarn-cluster:客户端电脑关了不影响,正常使用阶段
3,sbt是一款Spark用来对scala编写程序进行打包的工具(使用林子雨的教程没安装成功)
安装教程(参考):https://blog.csdn.net/Leader_wang/article/details/83743772
https://blog.csdn.net/litianxiang_kaola/article/details/103289326
两个教程相结合即可。
打包教程(参考):http://dblab.xmu.edu.cn/blog/1307-2/
sbt打包程序时使用:先新建~/.sbt/repositories文件
[repositories] #local public: http://maven.aliyun.com/nexus/content/groups/public/#这个maven typesafe:http://dl.bintray.com/typesafe/ivy-releases/ , [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly#这个ivy ivy-sbt-plugin:http://dl.bintray.com/sbt/sbt-plugin-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]#这个ivy sonatype-oss-releases sonatype-oss-snapshots
然后使用sbt -Dsbt.override.build.repos=true命令执行,然后在sbt界面输入run;自动退回项目原目录,再使用林子雨打包教程进行操作;不然下载依赖包会一直卡住不到。
使用sbt创建项目然后导入Eclipse:在导入插件前,要先下载插件.zip到系统;可以参考https://blog.csdn.net/dkl12/article/details/80224035和http://dblab.xmu.edu.cn/blog/1490/
RDD编程
1,创建RDD
方式一:从文件系统加载数据:包括本地,hdfs,云存储

启动spark-shell报错: A read-only user or a user in a read-only database is not permitted to disable read-only mode on a connection
解决办法:https://blog.csdn.net/u010886217/article/details/83685282
启动spark-shell报错:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决办法:https://blog.csdn.net/u010675669/article/details/81868415
Hadoop的9000端口无法连接:https://blog.csdn.net/u011170921/article/details/80437937(namenode没有启动)
![]()

方式二:通过集合或数组创建RDD:

2,操作RDD:
只有到动作类型操作才会进行计算,转换类型操作只会记录


1,filter(具体函数)操作:

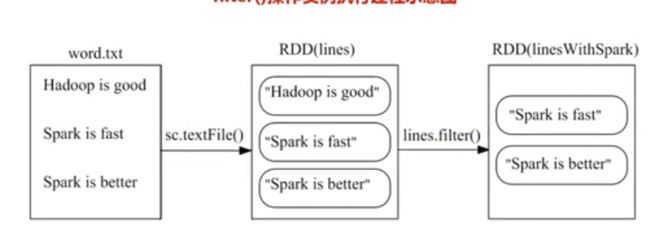
2,map(具体函数)操作:

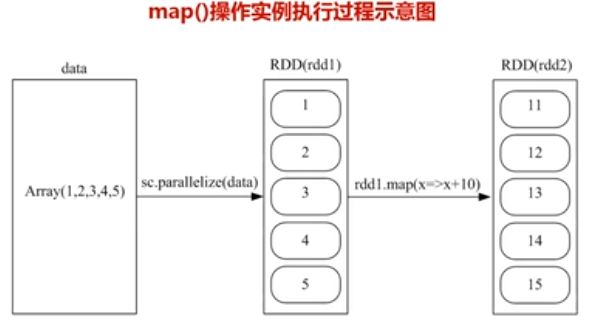


![]()
3,flatMa(具体函数)p操作:

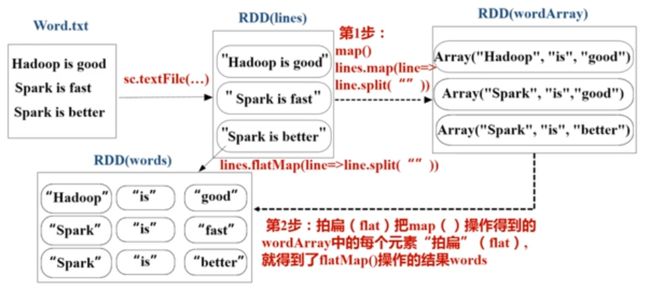

4,groupByKey()操作:进行分组得到(key,value-list)

5,reduceByKey(具体函数)操作:


每遇到一次动作操作就会从头到尾计算一次RDD,生成一个job;如果需要前一次的动作操作生成的值,则需要将生成的值缓存


![]()
3,RDD持久化
每遇到一次动作操作就会从头到尾计算一次RDD,生成一个job;如果需要前一次的动作操作生成的值,则需要将生成的值缓存
RDD持久化方法:调用.persist()方法对一个RDD标记为持久化,但不会真正持久化;等遇到下一次动作操作就会真正持久化
 会将值存入内存;当内存不足,则替换之前内存存的值
会将值存入内存;当内存不足,则替换之前内存存的值
RDD.persist(MEMORY_ONLY)<=>RDD.cache()
 将值存入内存,当内存不足,会将存不下的值存入磁盘
将值存入内存,当内存不足,会将存不下的值存入磁盘
将缓存中的持久化的RDD从内存中移除: .unpersist()方法

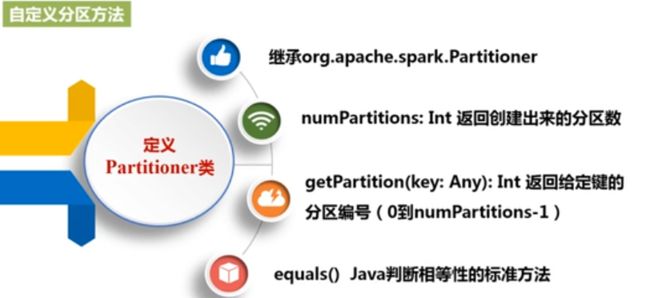
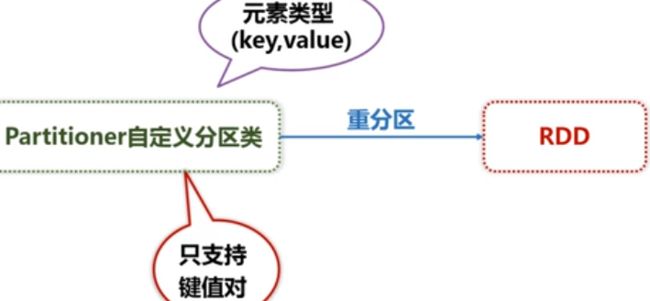
4,RDD分区:增加程序的并行度实现分布式的计算;减少通信开销;与hdfs的分块不一样
分区原则:

默认分区命令:如果设置local【n】,则分区为n;Apache Mesos模式会默认设置分区为8;standalone和yarn模式设置时,当集群中所有CPU数为n;与另一个?(是什么)比较,值最大的设置为分区数

设置分区数:

重设分区数:使用.repartition(n)方法

分区信息:



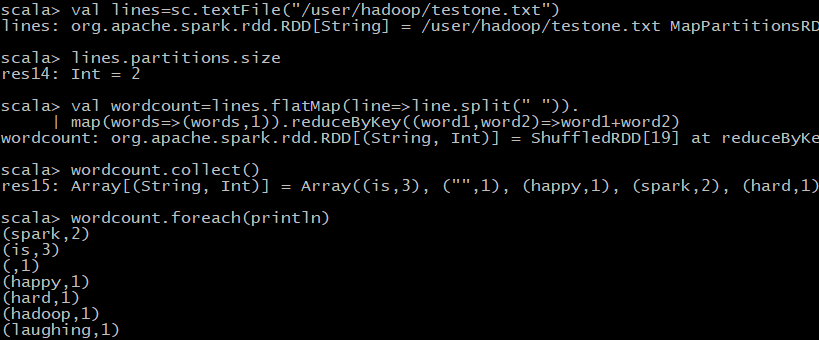
5,案例:单词统计:
spark异常关闭导致再次启动时端口占用错误: https://blog.csdn.net/weixin_40040107/article/details/90745038
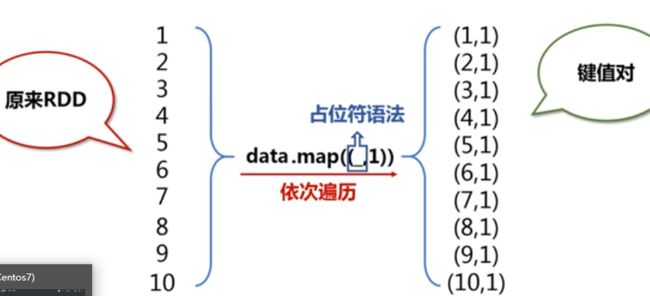
3,键值对RDD:
keys的功能:Pair RDD指键值对RDD
![]()
values的功能:
![]()
sortByKey()方法:常用,根据key进行排序,默认升序排序(默认参数为true)
sortBy()方法:根据value进行排序

mapValues()方法:

join:
![]()
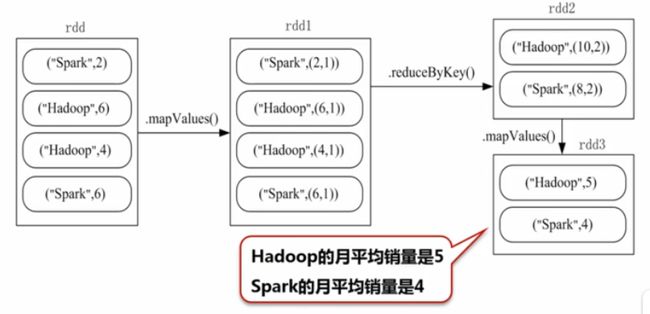
例子:求图书馆每个书的月平均销量

文件数据读写:
1,本地数据文件读写:输入错误语句,不会报错,只有遇到一次动作类型操作才会报错(惰性机制)
读操作:当读取的是一个目录时,会把目录下所有文件都读进去生成一个RDD
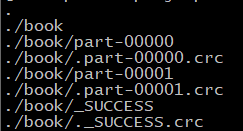
写操作:指定的目录中writeback文件必须是不存在的,执行写操作时才创建

写入后会在指定目录下会生成的,当只有一个分区时,只会生成part-00000开头文件和_SUCCESS开头文件
2,hdfs文件内容读写:与读取本地文件的操作一致
3,JSON文件内容读写:scala中与json解析操作有关的库(scala.util.parsing.json.JSON)


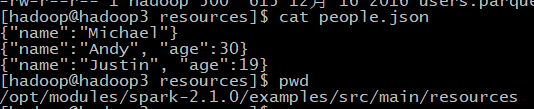
读取:

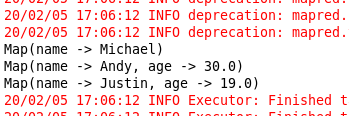
package WordCount import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import scala.util.parsing.json.JSON object WordCount { def main(args: Array[String]) { val inputFile = "file:///opt/modules/spark-2.1.0/examples/src/main/resources/people.json" val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]") val sc = new SparkContext(conf) //生成一个SparkContext对象 val jsonStrs = sc.textFile(inputFile) //加载json文件 val result = jsonStrs.map(s => JSON.parseFull(s)) result.foreach( {r => r match { case Some(map: Map[String, Any]) => println(map) //解析成功封装为Some对象 case None => println("Parsing failed") //解析失败返回None对象 case other => println("Unknown data structure: " + other) } } ) } }
运行截图:
4,读取HBASE数据:HBASE通过(表名,行键,列族,列限定符)确定一个单元格,一个数据


回顾HBASE操作:
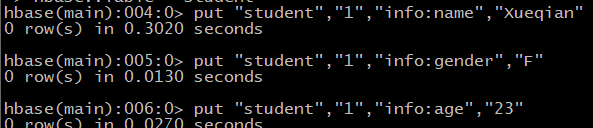
1,创建表student:
![]()
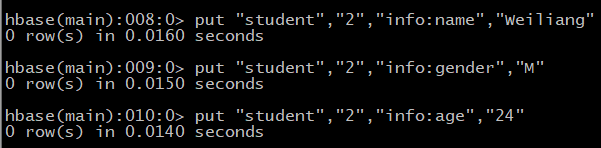
2,向表student中添加数据:
3,查看表:scan “student”