Wide & Deep 模型是谷歌在 2016 年发表的论文中所提到的模型。在论文中,谷歌将 LR 模型与 深度神经网络 结合在一起作为 Google Play 的推荐获得了一定的效果。在这篇论文后,Youtube,美团等公司也进行了相应的尝试并公开了他们的工作(相关链接请看本文底部)
官方提供的 Wide & Deep 模型的(简称,WD 模型)教程 都是使用 TensorFlow (简称,TF )自带的函数来做的特征工程,并且模型也进行了封装,但有时候我们的特征工程还使用到了 sklearn, numpy, pandas 来做,当我们想快速验证 WD 模型是否比旧模型要好的时候则显得不太便利,所以本文就向您展示了如何自己用 TF 搭建一个结构清晰,定制性更高的 WD 模型。在训练好 WD 模型后,我们还需要快速的看到模型预测的效果,所以在本文中我们利用 Docker 来快速部署一个可供服务的 TensorFlow 模型,也即可提供服务的 API。
因此,本文的内容如下:
- 使用 TF 搭建 WD 网络结构
- 使用 Docker 来快速部署模型
其对应的代码地址为:https://github.com/edvardHua/Articles
欢迎 star
本文实现的 WD 模型的结构如下图所示:
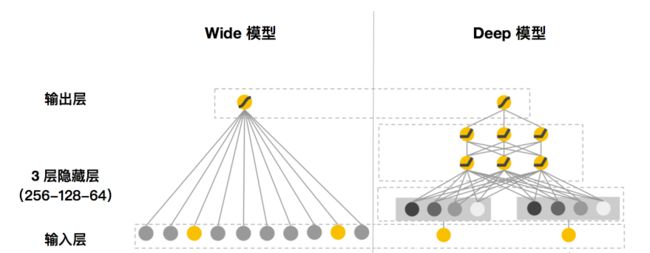
不难看出,Wide 模型这边其实就是一个 LR 模型,而右边 Deep 模型的部分则是一个三层隐藏层的神经网络,这三层隐藏层的神经元数目分别是 256-12-64,最后 Wide 模型 和 Deep 模型的结果进行相加后通过 ReLu 激活函数后输出预测结果。OK,先来看一下 Wide 模型部分的代码
def wide_model(input_data):
"""
一层的神经网络,相当于是 LR
:param input_data:
:return:
"""
input_len = int(input_data.shape[1])
with tf.name_scope("wide"):
# 修正的方式初始化权重,输出层结点只有一个
weights = tf.Variable(tf.truncated_normal([input_len, 1],
stddev=1.0 / math.sqrt(float(input_len))
), name="weights"
)
output = tf.matmul(input_data, weights)
# 沿着行这个纬度来求和
output = tf.reduce_sum(output, 1, name="reduce_sum")
# 输出每个样本经过计算的值
output = tf.reshape(output, [-1, 1])
return output
接下来看一下 Deep 模型的代码。
def deep_model(input_data, hidden1_units, hidden2_units, hidden3_units):
"""
三层的神经网络
:param input_data: 2-D tensor
:param hidden1_units: int
:param hidden2_units: int
:param hidden3_units: int
:return:
"""
# 得到每个样本的维度
input_len = int(input_data.shape[1])
with tf.name_scope("hidden1"):
# 修正的方式初始化权重
weights = tf.Variable(tf.truncated_normal([input_len, hidden1_units],
stddev=1.0 / math.sqrt(float(input_len))
), name="weights1"
)
biases = tf.Variable(tf.zeros([hidden1_units]), name='biases1')
hidden1 = tf.nn.relu(tf.matmul(input_data, weights)) + biases
···
# 另外两层隐藏层代码相似,所以这里省略掉,具体的代码请看 Github 仓库
···
with tf.name_scope("output"):
# 修正的方式初始化权重
weights = tf.Variable(tf.truncated_normal([hidden3_units, 1],
stddev=1.0 / math.sqrt(float(input_len))
), name="weights4"
)
biases = tf.Variable(tf.zeros([1]), name='biases4')
output = tf.nn.relu(tf.matmul(hidden3, weights) + biases)
return tf.nn.relu(output)
虽然 Deep 模型的代码存在一定的冗余,但是这样方便我们修改和调整网络的结构。
最后,将 Wide 模型 和 Deep 模型的结果进行相加后通过 ReLu 激活函数输出预测的结果。
def build_wdl(deep_input, wide_input, y):
"""
得到模型和损失函数
:param deep_input:
:param wide_input:
:param y:
:return:
"""
central_bias = tf.Variable([np.random.randn()], name="central_bias")
dmodel = deep_model(deep_input, 256, 128, 64)
wmodel = wide_model(wide_input)
# 使用 LR 将两个模型组合在一起
dmodel_weight = tf.Variable(tf.truncated_normal([1, 1]), name="dmodel_weight")
wmodel_weight = tf.Variable(tf.truncated_normal([1, 1]), name="wmodel_weight")
network = tf.add(
tf.matmul(dmodel, dmodel_weight),
tf.matmul(wmodel, wmodel_weight)
)
prediction = tf.nn.sigmoid(tf.add(network, central_bias), name="prediction")
loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=prediction)
)
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
return train_step, loss, prediction
搭建好结构后,我们可以生成一些随机数据来测试 Wide & Deep 模型,在这里我们随机生成 1000 个样本,每个样本的维度为 10,作为训练样本,为了简单起见,没有再创建验证样本。
训练只迭代一次,也即只遍历一次训练样本,这里的每个样本的 label 取值都为 0 或 1,所以目标函数为交叉熵,代码如下:
def build_and_saved_wdl():
"""
训练并保存模型
:return:
"""
# 训练数据
x_deep_data = np.random.rand(10000)
x_deep_data = x_deep_data.reshape(-1, 10)
x_wide_data = np.random.rand(10000)
x_wide_data = x_wide_data.reshape(-1, 10)
x_deep = tf.placeholder(tf.float32, [None, 10])
x_wide = tf.placeholder(tf.float32, [None, 10])
y = tf.placeholder(tf.float32, [None, 1])
y_data = np.array(
[random.randint(0, 1) for i in range(1000)]
)
y_data = y_data.reshape(-1, 1)
# 为了简单起见,这里没有验证集,也就没有验证集的 loss
train_step, loss, prediction = build_wdl(x_deep, x_wide, y)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(train_step, feed_dict={x_deep: x_deep_data, x_wide: x_wide_data, y: y_data})
训练完成后,还需要将模型进行保存,若要在 TensorFlow Serving 中使用,则需要用 SavedModelBuilder 来保存模型,代码如下:
def build_and_saved_wdl():
···
# 将训练好的模型保存在当前的文件夹下
builder = tf.saved_model.builder.SavedModelBuilder(join("./model_name", MODEL_VERSION))
inputs = {
"x_wide": tf.saved_model.utils.build_tensor_info(x_wide),
"x_deep": tf.saved_model.utils.build_tensor_info(x_deep)
}
output = {"output": tf.saved_model.utils.build_tensor_info(prediction)}
prediction_signature = tf.saved_model.signature_def_utils.build_signature_def(
inputs=inputs,
outputs=output,
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME
)
builder.add_meta_graph_and_variables(
sess,
[tf.saved_model.tag_constants.SERVING],
{tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: prediction_signature}
)
builder.save()
这里需要注意的是 MODEL_VERSION 必须为数字(代表着模型的版本),TF Serving 默认只会加载数字最大的那个模型,譬如说在这里我们执行完代码后,保存模型的 model_name 的文件夹的目录如下:
λ root [tf_demo/servering/model_name] → tree
.
└── 1
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
2 directories, 3 files
保存完模型后,在这里我们使用容器来部署模型,当然你也可以选择自己在机器上配置相关的环境,我们使用的镜像是由 Bitnami 提供的(Dockerhub 的地址请戳这里),当你需要部署模型时,只需要将模型所在的路径映射到容器中的 /bitnami/model-data 路径下即可,也即是键入如下命令
λ edvard [tf_demo/servering/model_name] → docker run -it -p 5000:9000 --volume /root/tf_demo/servering/model_name:/bitnami/model-data bitnami/tensorflow-serving
Welcome to the Bitnami tensorflow-serving container
...
2017-11-01 03:43:55.983106: I tensorflow_serving/core/loader_harness.cc:86] Successfully loaded servable version {name: inception version: 1}
2017-11-01 03:43:55.986130: I tensorflow_serving/model_servers/main.cc:288] Running ModelServer at 0.0.0.0:9000 ...
这里可能需要一些 Docker 相关的知识,我在参考资料中提供了一份很不错的 Gitbook 入门书籍,感兴趣的可以看看。
我们将容器中的服务映射到了宿主机的 5000 端口,接下来我们来测试一下 API 接口。代码如下:
def test_servable_api():
"""
测试 API
:return:
"""
# 随机产生 10 条测试数据
x_deep_data = np.random.rand(100).reshape(-1, 10)
x_wide_data = np.random.rand(100).reshape(-1, 10)
channel = implementations.insecure_channel('127.0.0.1', int(5000))
stub = prediction_service_pb2.beta_create_PredictionService_stub(channel)
# 发送请求
request = predict_pb2.PredictRequest()
request.model_spec.name = 'inception'
request.model_spec.signature_name = tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY
request.inputs[INPUT_WIDE_KEY].CopyFrom(
tf.contrib.util.make_tensor_proto(x_wide_data, shape=[10, WIDE_DIM], dtype=tf.float32))
request.inputs[INPUT_DEEP_KEY].CopyFrom(
tf.contrib.util.make_tensor_proto(x_deep_data, shape=[10, DEEP_DIM], dtype=tf.float32))
# 10 秒超时
res = stub.Predict(request, 10.0)
pprint(res.outputs[OUTPUT_KEY])
输出的预测结果的结构如下:
dtype: DT_FLOAT
tensor_shape {
dim {
size: 10
}
dim {
size: 1
}
}
float_val: 0.355874538422
float_val: 0.3225004673
float_val: 0.32104665041
float_val: 0.233089879155
float_val: 0.376621931791
float_val: 0.144557282329
float_val: 0.34686845541
float_val: 0.304817527533
float_val: 0.367866277695
float_val: 0.393035560846
参考资料
谷歌 Wide & Deep 论文
Youtube 深度推荐的论文
美团点评深度排序技术文章
Docker 从入门到实践(Gitbook)