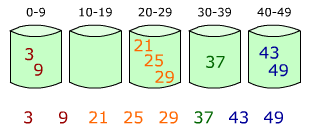时间复杂度
n^2表示n的平方,选择排序有时叫做直接选择排序或简单选择排序
O(n)这样的标志叫做渐近时间复杂度,是个近似值.各种渐近时间复杂度由小到大的顺序如下
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
一般时间复杂度到了2n(指数阶)及更大的时间复杂度,这样的算法我们基本上不会用了,太不实用了.比如递归实现的汉诺塔问题算法就是O(2n).
平方阶(n^2)的算法是勉强能用,而nlogn及更小的时间复杂度算法那就是非常高效的算法了啊.
空间复杂度
冒泡排序,简单选择排序,堆排序,直接插入排序,希尔排序的空间复杂度为O(1),因为需要一个临时变量来交换元素位置,(另外遍历序列时自然少不了用一个变量来做索引)
快速排序空间复杂度为logn(因为递归调用了) ,归并排序空间复杂是O(n),需要一个大小为n的临时数组.
基数排序的空间复杂是O(n),桶排序的空间复杂度不确定
最快的排序算法是桶排序
所有排序算法中最快的应该是桶排序(很多人误以为是快速排序,实际上不是.不过实际应用中快速排序用的多)但桶排序一般用的不多,因为有几个比较大的缺陷.
1.待排序的元素不能是负数,小数.
2.空间复杂度不确定,要看待排序元素中最大值是多少.
所需要的辅助数组大小即为最大元素的值.
稳定性
1.简单选择排序 2.堆排序 (1和2是属于选择排序)
3.直接插入排序 4.希尔排序 (3和4属于插入排序,有时把改进后的直接插入排序叫做二分插入)
5.冒泡排序 6.快速排序 (5和6属于交换排序.交换排序顾名思义是不停的交换数据位置.但实际上选择排序也在不停的交换元素,但次数较少,只有找到最大值才一次交换.侧重点还是在通过遍历或堆来选择出最值.而冒泡排序就是通过不停交换相邻元素得出最大值,快速排序也在不停交换元素使序列一步步接近有序.侧重在交换)
7.基数排序 8.桶排序 (7和8属于分配排序)
9.归并排序
面对这以多排序算法你可能郁闷着要自己排序时用哪种算法好呢? 每种算法适用哪些场景?
为了对比上面各种不同算法,可以从如下几个方面来考虑.
1.排序算法的稳定性
2.排序算法时间复杂度
3.排序算法空间复杂度
4.各种算法适用的最佳场景.
排序算法稳定性
所谓稳定性是指待排序的序列中有两元素相等,排序之后它们的先后顺序不变.假如为A1,A2.它们的索引分别为1,2.则排序之后A1,A2的索引仍然是1和2.
稳定也可以理解为一切皆在掌握中,元素的位置处在你在控制中.而不稳定算法有时就有点碰运气,随机的成分.当两元素相等时它们的位置在排序后可能仍然相同.但也可能不同.是未可知的.
另外要注意的是:算法思想的本身是独立于编程语言的,所以你写代码去实现算法的时候很多细节可以做不同的处理.采用不稳定算法不管你具体实现时怎么写代码,最终相同元素位置总是不确定的(可能位置没变也可能变了).而稳定排序算法是你在具体实现时如果细节方面处理的好就会是稳定的,但有些细节没处理得到的结果仍然是不稳定的.
比如冒泡排序,直接插入排序,归并排序虽然是稳定排序算法,但如果你实现时细节没处理好得出的结果也是不稳定的.
稳定性的用处
我们平时自己在使用排序算法时用的测试数据就是简单的一些数值本身.没有任何关联信息.这在实际应用中一般没太多用处.实际应该中肯定是排序的数值关联到了其他信息,比如数据库中一个表的主键排序,主键是有关联到其他信息.另外比如对英语字母排序,英语字母的数值关联到了字母这个有意义的信息.
可能大部分时候我们不用考虑算法的稳定性.两个元素相等位置是前是后不重要.但有些时候稳定性确实有用处.它体现了程序的健壮性.比如你网站上针对最热门的文章或啥音乐电影之类的进行排名.由于这里排名不会像我们成绩排名会有并列第几名之说.所以出现了元素相等时也会有先后之分.如果添加进新的元素之后又要重新排名了.之前并列名次的最好是依然保持先后顺序才比较好.
哪些算法是稳定的呢
稳定性算法: 基数排序 , 直接插入排序 , 冒泡排序, 归并排序
**不稳定性算法: **桶排序, 二分插入排序,希尔排序, 快速排序, 简单选择排序,堆排序
各种算法稳定性详解
(1)基数排序(稳定)与桶排序(不稳定)
这两种算法都是属于分配排序算法.(利用元素值本身的信息直接映射到一个辅助序列中变成有序的.而不是通过与其他元素比较确定顺序位置)
基数排序因为在是把低位按顺序映射到一个临时序列中去,是依次序映射,没有涉及到数据位置的变动.然后再按高位顺序映射.所以相同元素也是按次序映射过去.所以是稳定的
如果数据元素没有重复的则采用简单桶排序,此时没有重复元素,所以自然不存在稳不稳定这一说.如果有重复元素得用改进的桶排序.此时辅助的临时数组只是通过索引来识别待排序元素的键值.丢失了其他信息(这是所有采用辅助的临时序列的算法中唯一一个会丢失信息的算法).假如待排序元素是一个map类型,按它的键值来排序.其他算法采用辅助序列时是把map类型做为元素去考虑的.而只有改进的桶排序不会把map类型当元素,只是利用到了键值信息. 这样一来就无法区分键值相同的信息,因此自然是不稳定的算法了啊.
(2)归并排序(稳定)
归并排序使得了递归的思想,把序列递归的分割成小序列,然后合并排好序的子序列.当有序列的左右两子序列合并的时候一般是先遍历左序列,所在左右序列如果有相等元素,则处在左边的仍然在前,这就稳定了.但是如果你非得先遍历右边序列则算法变成不稳定的了.虽然这样排出来的序也是对的,但变成了不稳定的,所以是不太好的实现.
(3)简单选择排序(不稳定)与堆排序(不稳定)
这两种算法都属于选择排序.(从待排序的元素中挑选出最大或最小值.下面的例子以最小值为例)
简单选择排序由于选出最小值后需要交换位置,位置一变就会变得不稳定.例如8 3 8 1.当从左往右遍历找最小值时,找到了1,这就需要把8跟1交换.这样两个相等元素8的位置就变了.
堆排序的话,也会存在跟上面一样的交换最大值的位置会导致不稳定.例如有大堆 8 8 6 5 2.先选出第一个最大值8,放最末尾.此时就不稳定了.因为第二个8就跑它前面去了.
(4)冒泡排序(稳定)与快速排序(不稳定)
这两种算法都属于交换排序.
冒泡是通过不停的遍历,以升序为例,如果相邻元素中左边的大于右边的则交换.碰到相等的时就不交换保持原位.所以是稳定的.当然如果你非得吃饱了撑着了,在碰到相等的时也交换下,那肯定变成不稳定的算法了.
快速排序是不稳定的.举例8 5 6 6 .以8为基准,第一趟交换后最后一个6跑到第一位,8到最后.第二趟交换.这个6跑到5的位置.变成有序的了.两个6位置变了,所以是不稳定的.
def quick_sort(alist, start, end):
"""快速排序"""
# 递归的退出条件
if start >= end:
return
# 设定起始元素为要寻找位置的基准元素
mid = alist[start]
# low为序列左边的由左向右移动的游标
low = start
# high为序列右边的由右向左移动的游标
high = end
while low < high:
# 如果low与high未重合,high指向的元素不比基准元素小,则high向左移动
while low < high and alist[high] >= mid:
high -= 1
# 将high指向的元素放到low的位置上
alist[low] = alist[high]
# 如果low与high未重合,low指向的元素比基准元素小,则low向右移动
while low < high and alist[low] < mid:
low += 1
# 将low指向的元素放到high的位置上
alist[high] = alist[low]
# 退出循环后,low与high重合,此时所指位置为基准元素的正确位置
# 将基准元素放到该位置
alist[low] = mid
# 对基准元素左边的子序列进行快速排序
quick_sort(alist, start, low-1)
# 对基准元素右边的子序列进行快速排序
quick_sort(alist, low+1, end)
alist = [54,26,93,17,77,31,44,55,20]
quick_sort(alist,0,len(alist)-1)
print(alist)
(5)直接插入(稳定),二分插入排序(不稳定)与希尔排序(不稳定)
直接插入时是先在已排序好的的子序列中找到合适的位置再插入.假设左边是已排序的,右边是没排序的.通过从后向前遍历已排序序列,然后插入,此时相等元素依然可以保持原有位置.但是如果你从前向后遍历已排序序列就会是不稳定排序了.
二分插入排序是不稳定的,因为通过二分查找时得到的位置不稳定.例如3 4 4 5 4.但把最后一个4插入时肯定会跑到第二个4前面去了.所以是不稳定的.
通过上面的分析我们可以得出这样一个经验之谈.
1.只要不涉及到两个元素之间位置的交换就肯定是稳定的排序算法.比如归并排序,基数排序.(桶排序不稳定是个特例,因为它丢失了附带信息,不然的话可以弄成稳定排序的)
2.在涉及到不同位置元素交换的算法中除了冒泡和直接插入排序是稳定的,其他都是不稳定的.
你可以这样想,之所以出现相同元素位置变了就是其中一个交换位置时从另一个头顶跳过去了,而冒泡算法是相邻位置互换,跳不过去的,碰到相等元素的时候就停住不交换了.
而直接插入排序是往已排好序的序列中插入.所以你通过由后往前遍历碰到相等的时就停住,这样也能保持稳定.但记住一定得从后往前遍历,不然也会不稳定.(所以说直接插入是半稳吧,而冒泡是非常的稳啊,除非你闲得蛋痛非得把两相等的元素两两交换)
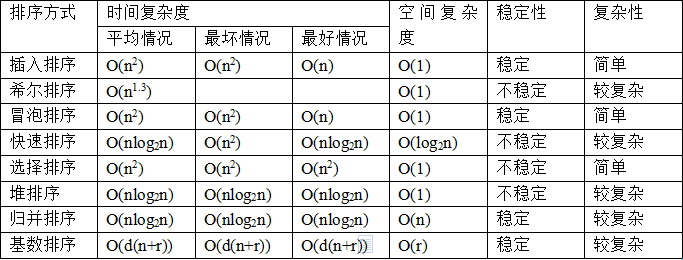
基数排序
算法原理
基数排序 (Radix Sort) 是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。基数排序的发明可以追溯到 1887 年赫尔曼·何乐礼在打孔卡片制表机 (Tabulation Machine)上的贡献。
排序过程:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序法会使用到桶 (Bucket),顾名思义,通过将要比较的位(个位、十位、百位…),将要排序的元素分配至 0~9 个桶中,借以达到排序的作用,在某些时候,基数排序法的效率高于其它的比较性排序法。
桶排序
算法原理
桶排序 (Bucket sort)或所谓的箱排序的原理是将数组分到有限数量的桶子里,然后对每个桶子再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序),最后将各个桶中的数据有序的合并起来。
排序过程:
- 假设待排序的一组数统一的分布在一个范围中,并将这一范围划分成几个子范围,也就是桶
- 将待排序的一组数,分档规入这些子桶,并将桶中的数据进行排序
- 将各个桶中的数据有序的合并起来
Data Structure Visualizations 提供了一个桶排序的分步动画演示。
实例分析
设有数组 array = [29, 25, 3, 49, 9, 37, 21, 43],那么数组中最大数为 49,先设置 5 个桶,那么每个桶可存放数的范围为:09、1019、2029、3039、40~49,然后分别将这些数放人自己所属的桶,如下图:
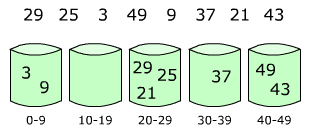
然后,分别对每个桶里面的数进行排序,或者在将数放入桶的同时用插入排序进行排序。最后,将各个桶中的数据有序的合并起来,如下图: