- OOM系列之一:java.lang.OutOfMemoryError: Java堆空间问题详解
马小瑄
经验分享开发语言程序人生java性能优化
第一篇:java.lang.OutOfMemoryError:JavaheapspaceJava应用程序只允许使用有限的内存量。此限制是在应用程序启动期间指定的。为了让事情变得更复杂,Java内存被分成两个不同的区域。这些区域称为堆空间和Permgen(用于永久代):这些区域的大小是在Java虚拟机(JVM)启动期间设置的,可以通过指定JVM参数-Xmx和-XX:MaxPermSize进行自定义。
- 【Linux】日志插件
s_little_monster_
Linuxlinux数据库oracle运维学习经验分享笔记
个人主页~日志插件一、日志文件的重要性二、日志文件的简单实现1、comm.hpp2、log.hpp三、测试用例一、日志文件的重要性故障排查与问题定位快速发现问题:日志能够实时记录系统运行过程中的各种事件和状态信息,当系统出现故障或异常时,通过查看日志可以快速察觉到问题的发生,例如,服务器突然崩溃,日志中可能会记录下崩溃前的错误信息、异常堆栈,帮助运维人员第一时间得知系统出现了故障精准定位根源:详细
- JVMGC的分类详解
qq_17805795
JVMJVMGC的分类详解
JVMGC的分类详解首先JVM有4种GC第一种为单线程GC,也是默认的GC。,该GC适用于单CPU机器。第二种为ThroughputGC,是多线程的GC,适用于多CPU,使用大量线程的程序。第二种GC与第一种GC相似,不同在于GC在收集Young区是多线程的,但在Old区和第一种一样,仍然采用单线程。-XX:+UseParallelGC参数启动该GC。第三种为ConcurrentLowPauseG
- 【CSS 面经】元素的层叠顺序
Peter-Lu
#CSS面经css前端htmlecmascriptjavascript
文章目录一、层叠顺序的基本概念1.视觉层叠2.默认层叠顺序二、如何控制元素的层叠顺序?1.`z-index`属性示例:使用`z-index`控制元素层叠顺序2.`position`属性与层叠顺序示例:不同`position`设置下的层叠顺序3.`z-index`和堆叠上下文示例:堆叠上下文三、总结在网页设计中,元素的层叠顺序(StackingOrder)是指在同一页面上,多个元素如何相互叠加的规则
- Vue2快速入门
Vic2334
前端vue.js前端框架vue快速入门
1.概念理解什么是vue?Vue.js是一套构建用户界面的渐进式框架。Vue从设计角度来讲,虽然能够涵盖这张图上所有的东西,但是你并不需要一上手就把所有东西全用上,因为没有必要。无论从学习角度,还是实际情况,这都是可选的。声明式渲染和组件系统是Vue的核心库所包含内容,而客户端路由、状态管理、构建工具都有专门解决方案。这些解决方案相互独立,你可以在核心的基础上任意选用其他的部件,不一定要全部整合在
- Spring Data JPA
Vic2334
JAVASpringspring后端java开源
SpringDataJPA什么是JPA?相同处:1.都跟数据库操作有关,JPA是jdbc的升华,升级版。2.JDBC和JPA都是一组规范1接口。3.都是由SUN公司推出的不同处:1.JDBC是有各个关系型数据库实现的,JPA是有ORM框架实现。2.JDBC使用SQL语句和数据库通信,JPA用面向对象方式,通过ORM框架生成SQL,进行操作。3.JPA在JDBC之上,JPA也要依赖JDBC才能操作数
- FastDVDnet:基于深度学习的视频去噪框架
陆可鹃Joey
FastDVDnet:基于深度学习的视频去噪框架项目地址:https://gitcode.com/gh_mirrors/fa/fastdvdnet项目介绍FastDVDnet是一个高效、开源的深度学习模型,专注于视频去噪。该项目由MatteoTassano开发并维护,旨在提供一种快速且有效的解决方案,以消除视频中的噪声,同时保持图像细节和自然纹理。它利用了时间域的连续性和深层神经网络的力量,确保在
- 手撕multi-head self attention 代码
心若成风、
自然语言处理语言模型transformer
在深度学习和自然语言处理领域,多头自注意力(Multi-HeadSelf-Attention)机制是Transformer模型中的核心组件之一。它允许模型在处理序列数据时,能够同时关注序列中的不同位置,从而捕获到丰富的上下文信息。下面,我们将详细解析多头自注意力机制的实现代码。一、概述多头自注意力机制的核心思想是将输入序列进行多次线性变换,然后分别计算自注意力得分,最后将所有头的输出进行拼接,并通
- js实现关于分页的一种实现方式
番薯(Koali)
Javajavaweb分页数据javascript
项目中用到列表的地方很多,二页面列表的显示必然要求分页,所以分页和查询几乎密不可分,如果说你不会分页查询数据,那你基本上还属于菜鸟。分页的原理很简单,从sql上看就是从哪一条开始,往后差几条。所以sql只需要传2个参数,这只是原理罢了,关键是实现。而实现的方法就多了去了,架构师干这个是小菜一碟。在我的项目中,关于分页架构师已经写好了一个管理分页的类,这个类与sql耦合,控制分页只需哟啊控制这个类的
- 算法手撕面经系列(1)--手撕多头注意力机制
夜半罟霖
算法python深度学习
多头注意力机制 一个简单的多头注意力模块可以分解为以下几个步骤:先不分多头,对输入张量分别做变换,得到Q,K,VQ,K,VQ,K,V对得到的Q,K,VQ,K,VQ,K,V按头的个数进行split;用Q,KQ,KQ,K计算向量点积考虑是否要添因果mask利softmax计算注意力得分矩阵atten对注意力得分矩阵施加Dropout将atten矩阵和VVV矩阵相乘再过一道最终的输出变换代码 给出一个d
- 【STM32】USART串口收发HEX数据包&收发文本数据包
傍晚冰川
stm32网络嵌入式硬件单片机笔记学习c语言
有关串口知识参考:【STM32】USART串口协议&串口外设-学习笔记-CSDN博客HEX模式/十六进制模式/二进制模式:以原始数据的形式显示文本模式/字符模式:以原始数据编码后的形式显示参考上面文章查看ASCII编码表HEX数据包包头包尾和载荷数据重复问题的解决方法:解决思路方法文本数据包文本模式有大量的字符可以作为包头包尾,可以有效避免载荷数据和包头包尾重复的问题HEX数据包和文本数据包两者的
- 深度学习 Deep Learning 第2章 线性代数
odoo中国
AI编程人工智能深度学习线性代数人工智能
深度学习第2章线性代数线性代数是深度学习的语言。张量操作是神经网络计算的基石,矩阵乘法是前向传播的核心,范数约束模型复杂度,而生成空间理论揭示模型表达能力的本质。本章介绍线性代数的基本内容,为进一步学习深度学习做准备。主要内容2.1标量、向量、矩阵和张量标量:单个数字,用斜体表示,通常赋予小写字母变量名。向量:数字数组,按顺序排列,用粗体小写字母表示,元素通过下标访问。矩阵:二维数字数组,用粗体大
- 大白话讲解MIPI DPHY、C PHY与M PHY的不同应用与优势
空间机器人
Serdes知识合集汽车
1.MIPIDPHY:高速公路上的小跑车想象一下你在高速公路上开着一辆小跑车,这辆车虽然不如跑车那样极速,但它能在城市和乡村之间快速穿梭,满足大多数日常需求。MIPIDPHY就像这辆小跑车,适合那些需要高速、高效,但不要求极限速率的场景,比如手机显示屏和摄像头之间的连接。在这个“跑车”里,时钟信号和数据信号分别通过两条“车道”——一条是时钟车道(CLK),另一条是数据车道(Data)。这两条车道的
- DeepSeek-辅助NS3学习和功能调试
wenxin-
学习php开发语言DeepSeekNS3
文章目录一、前言二、DeepSeek回答**1.MAC层替换导致的兼容性问题****可能原因**:**验证方法**:**2.路由表未正确建立****可能原因**:**验证方法**:**3.LR-WPAN物理层限制****可能原因**:**验证方法**:**4.AODV协议配置错误****可能原因**:**验证方法**:**5.网络层与MAC层地址映射问题****可能原因**:**验证方法**:**
- springboot2.2.x对接elasticsearch7.2.0,实现分页搜索情况下的高亮和摘要功能
lyc613
elasticsearch
springboot2.2.x对接elasticsearch7.2.0,实现分页搜索情况下的高亮和摘要功能相关依赖2.2.0.RELEASEorg.springframework.bootspring-boot-starter-data-elasticsearches配置spring:elasticsearch:rest:#es地址uris:http://192.168.125.12:9200功能
- Matlab多种算法解决未来杯B的多分类问题
Subject.625Ruben
算法分类机器学习数学建模未来杯matlab人工智能
1.读取数据首先,我们从Excel文件中读取训练集和测试集:2.训练集划分我们将80%的数据用于训练,20%用于验证。3.训练多个模型我们选取8种常见分类模型,并存储预测结果。fori=1:length(modelNames)switchmodelNames{i}case'MultinomialLogisticRegression'B=mnrfit(X_train,Y_train,'model',
- Windows C盘清理技巧分享
qzw1210
windows
清理C盘是保持计算机性能和存储空间的关键步骤。C盘通常是系统盘,存储着操作系统和许多重要的系统文件,因此在清理时需要格外小心,以免误删重要文件。以下是一些详细的C盘清理技巧,帮助你有效释放空间。1.使用磁盘清理工具Windows自带的磁盘清理工具是清理C盘的首选工具。它可以安全地删除不必要的系统文件。步骤:打开“此电脑”。右键点击C盘,选择“属性”。点击“磁盘清理”按钮。在弹出的窗口中,选择要删除
- Hive SQL 精进系列: JSON_TUPLE 快速提取多键值
进一步有进一步的欢喜
HiveSQL精进系列hivesqlhadoop
目录一、引言二、json_tuple函数基础2.1基本语法参数解释返回值简单示例三、应用场景3.1数据提取与分析3.2数据集成与转换3.3复杂JSON数据处理四、json_tuple、get_json_object和from_json的对比4.1功能特点4.2语法和使用复杂度4.3性能表现4.4示例对比使用json_tuple使用get_json_object使用from_json五、使用注意事项
- 基于群智能算法的三维无线传感网络覆盖优化数学模型-可以使用群智能算法直接调用进行优化,完整MATLAB代码
算法小狂人
算法应用matlabphp开发语言
1.1三维覆盖模型由于节点随机抛洒,而传感器节点的分布情况会影响网络覆盖率,以RcovR_{\text{cov}}Rcov作为覆盖率评价标准。在三维覆盖区域中,传感器节点的覆盖区域是某一半径确定的球。在三维监测区域中随机抛洒NNN个传感器节点,形成节点集S={s1,s2,s3,⋯ ,sN}S=\{s_1,s_2,s_3,\cdots,s_N\}S={s1,s2,s3,⋯,sN},第iii个节点的坐
- 回溯法--力扣第17题“电话号码的字母组合”(java)
27xixi
数据结构与算法leetcodejava算法
力扣第17题“电话号码的字母组合”回溯法(DFS)回溯法通过递归遍历每个数字对应的字母,生成所有可能的组合。核心思想是构建搜索树,每次选择一个字母后进入下一层递归,回溯时撤销选择以尝试其他分支。实现步骤:构建数字到字母的映射表:使用数组或哈希表存储每个数字对应的字母。递归回溯:终止条件:当前路径长度等于输入数字字符串长度时,将结果加入列表。遍历当前数字对应的所有字母,依次选择、递归、撤销选择。Ja
- 开博尔支持超高清8K显示HDMI2.1线材评测体验
只你不知
测评文HDMI2.1HDMI2.1高清线8K电视线4K高清线
前言(网络整理):虽然目前没有真正的HDMI2.1的电视机,但是HDMI协会针对HDMI2.1标准做出了临时参数标准和HDMI2.1连接器认证授权,经开博尔技术咨询后得知,开博尔对于HDMI协会当前对HDMI2.1的研产要求均满足,采用定制HDMI2.1认证连接器。HDMI2.0能够实现60FPS的4K图像或30FPS的8K图像。而新的HDMI2.1则可以显示120FPS的4K图像或60FPS的8
- 如何使用 Spring Boot 实现分页和排序
大G哥
springboot后端javaspring
在SpringBoot中实现分页和排序通常是通过SpringDataJPA或者SpringDataMongoDB提供的分页功能来完成的。以下是一个基于SpringDataJPA的分页和排序实现的基本步骤。1.添加依赖首先,确保你在pom.xml中包含了SpringDataJPA和数据库驱动的依赖。org.springframework.bootspring-boot-starter-data-jp
- 开源框架--Glide源码阅读下
Bonnie_cat
开源glide
接上半部分开源框架–Glide源码阅读上,我们接着看Glide源码的with和load。3.源码阅读3.2load上半部分分析知道了with()方法返回的是RequestManager,下面看RequestManager的load()方法,@OverridepublicRequestBuilderload(@NullableStringstring){returnasDrawable().load
- Manus 一码难求,MetaGPT、OpenManus、Camel AI 会是替代方案吗?
全干程序员demo
技术热文人工智能
Manus一码难求,MetaGPT、OpenManus、CamelAI会是替代方案吗?一、Manus的现象与问题Manus作为一款号称“全球首个通用AI智能体”的产品,凭借其强大的功能和新颖的营销策略迅速走红。然而,其封闭的邀请码机制和高昂的使用门槛,让普通开发者望而却步。Manus的邀请码被炒至高价,甚至出现账号冻结等现象,这引发了用户对其技术壁垒和实际应用价值的质疑。二、MetaGPT、Ope
- 【大模型对话 的界面搭建-Open WebUI】
y_dd
人工智能深度学习人工智能llama语言模型
OpenWebUI前身就是OllamaWebUI,为Ollama提供一个可视化界面,可以完全离线运行,支持Ollama和兼容OpenAI的API。github网址https://github.com/open-webui/open-webui安装第一种docker安装如果ollama安装在同一台服务器上:dockerrun-d-p3000:8080--add-host=host.docker.in
- 信息学奥赛一本通C++语言-----1119:矩阵交换行
宝祺祺吖
c++算法
【题目描述】给定一个5×55×5的矩阵(数学上,一个r×cr×c的矩阵是一个由rr行cc列元素排列成的矩形阵列),将第nn行和第mm行交换,输出交换后的结果。【输入】输入共66行,前55行为矩阵的每一行元素,元素与元素之间以一个空格分开。第66行包含两个整数m、nm、n,以一个空格分开(1≤m,n≤5)(1≤m,n≤5)。【输出】输出交换之后的矩阵,矩阵的每一行元素占一行,元素之间以一个空格分开。
- 程序员必看!DeepSeek全栈开发指南:从代码生成到分布式训练的黑科技解析
AI创享派
后端
一、DeepSeek技术新突破:程序员必须掌握的MoE架构实战2025年2月25日,DeepSeek开源了专为MoE模型设计的DeepEP通信库,这项技术革新直接影响了分布式训练和推理效率。该库支持FP8精度与NVLink/RDMA技术,吞吐量提升3倍以上,特别适合处理千亿级参数的分布式任务。对于后端工程师而言,DeepEP的以下特性值得关注:计算-通信重叠机制:通过回调函数实现GPU资源动态分配
- elasticsearch analyzer 学习笔记
weixin_40455124
elasticsearch代码分析及扩展elasticsearchanalyzertoken
基本定义analyzer执行将输入字符流分解为token的过程使用场景在indexing的时候,也即在建立索引的时候在searching的时候,也即在搜索时,分析需要搜索的词语analysisCharacterfiltering(字符过滤器):使用字符过滤器转换字符Breakingtextintotokens(把文字转化为标记):将文本分成一组一个或多个标记Tokenfiltering:使用标记过
- Android StrictMode 使用与原理深度解析
伟江.Zeng
Android基础androidStrictMode性能优化内存泄漏代码规范耗时检测kotlin
AndroidStrictMode是Android系统提供的一种开发者工具,用于检测应用主线程中不合理的耗时操作(如磁盘I/O、网络请求等)和内存泄漏问题。通过配置策略和惩罚机制,它帮助开发者在早期发现潜在性能问题,提升应用流畅性。以下从使用方式和实现原理两方面进行深度解析。一、StrictMode使用详解1.基础配置在Application或Activity的onCreate()中初始化Stri
- MATLAB算法实战应用案例精讲-【深度学习】归一化
林聪木
matlab算法深度学习
目录为什么要做特征归一化/标准化?常用featurescaling方法计算方式上对比分析featurescaling需要还是不需要什么时候需要featurescaling?什么时候不需要FeatureScaling?归一化基础知识点1.什么是归一化2.为什么要归一化3.为什么归一化能提高求解最优解的速度4.归一化有哪些类型5.不同归一化的使用条件6.归一化和标准化的联系与区别层归一化综述提出背景概
- web前段跨域nginx代理配置
刘正强
nginxcmsWeb
nginx代理配置可参考server部分
server {
listen 80;
server_name localhost;
- spring学习笔记
caoyong
spring
一、概述
a>、核心技术 : IOC与AOP
b>、开发为什么需要面向接口而不是实现
接口降低一个组件与整个系统的藕合程度,当该组件不满足系统需求时,可以很容易的将该组件从系统中替换掉,而不会对整个系统产生大的影响
c>、面向接口编口编程的难点在于如何对接口进行初始化,(使用工厂设计模式)
- Eclipse打开workspace提示工作空间不可用
0624chenhong
eclipse
做项目的时候,难免会用到整个团队的代码,或者上一任同事创建的workspace,
1.电脑切换账号后,Eclipse打开时,会提示Eclipse对应的目录锁定,无法访问,根据提示,找到对应目录,G:\eclipse\configuration\org.eclipse.osgi\.manager,其中文件.fileTableLock提示被锁定。
解决办法,删掉.fileTableLock文件,重
- Javascript 面向对面写法的必要性?
一炮送你回车库
JavaScript
现在Javascript面向对象的方式来写页面很流行,什么纯javascript的mvc框架都出来了:ember
这是javascript层的mvc框架哦,不是j2ee的mvc框架
我想说的是,javascript本来就不是一门面向对象的语言,用它写出来的面向对象的程序,本身就有些别扭,很多人提到js的面向对象首先提的是:复用性。那么我请问你写的js里有多少是可以复用的,用fu
- js array对象的迭代方法
换个号韩国红果果
array
1.forEach 该方法接受一个函数作为参数, 对数组中的每个元素
使用该函数 return 语句失效
function square(num) {
print(num, num * num);
}
var nums = [1,2,3,4,5,6,7,8,9,10];
nums.forEach(square);
2.every 该方法接受一个返回值为布尔类型
- 对Hibernate缓存机制的理解
归来朝歌
session一级缓存对象持久化
在hibernate中session一级缓存机制中,有这么一种情况:
问题描述:我需要new一个对象,对它的几个字段赋值,但是有一些属性并没有进行赋值,然后调用
session.save()方法,在提交事务后,会出现这样的情况:
1:在数据库中有默认属性的字段的值为空
2:既然是持久化对象,为什么在最后对象拿不到默认属性的值?
通过调试后解决方案如下:
对于问题一,如你在数据库里设置了
- WebService调用错误合集
darkranger
webservice
Java.Lang.NoClassDefFoundError: Org/Apache/Commons/Discovery/Tools/DiscoverSingleton
调用接口出错,
一个简单的WebService
import org.apache.axis.client.Call;import org.apache.axis.client.Service;
首先必不可
- JSP和Servlet的中文乱码处理
aijuans
Java Web
JSP和Servlet的中文乱码处理
前几天学习了JSP和Servlet中有关中文乱码的一些问题,写成了博客,今天进行更新一下。应该是可以解决日常的乱码问题了。现在作以下总结希望对需要的人有所帮助。我也是刚学,所以有不足之处希望谅解。
一、表单提交时出现乱码:
在进行表单提交的时候,经常提交一些中文,自然就避免不了出现中文乱码的情况,对于表单来说有两种提交方式:get和post提交方式。所以
- 面试经典六问
atongyeye
工作面试
题记:因为我不善沟通,所以在面试中经常碰壁,看了网上太多面试宝典,基本上不太靠谱。只好自己总结,并试着根据最近工作情况完成个人答案。以备不时之需。
以下是人事了解应聘者情况的最典型的六个问题:
1 简单自我介绍
关于这个问题,主要为了弄清两件事,一是了解应聘者的背景,二是应聘者将这些背景信息组织成合适语言的能力。
我的回答:(针对技术面试回答,如果是人事面试,可以就掌
- contentResolver.query()参数详解
百合不是茶
androidquery()详解
收藏csdn的博客,介绍的比较详细,新手值得一看 1.获取联系人姓名
一个简单的例子,这个函数获取设备上所有的联系人ID和联系人NAME。
[java]
view plain
copy
public void fetchAllContacts() {
- ora-00054:resource busy and acquire with nowait specified解决方法
bijian1013
oracle数据库killnowait
当某个数据库用户在数据库中插入、更新、删除一个表的数据,或者增加一个表的主键时或者表的索引时,常常会出现ora-00054:resource busy and acquire with nowait specified这样的错误。主要是因为有事务正在执行(或者事务已经被锁),所有导致执行不成功。
1.下面的语句
- web 开发乱码
征客丶
springWeb
以下前端都是 utf-8 字符集编码
一、后台接收
1.1、 get 请求乱码
get 请求中,请求参数在请求头中;
乱码解决方法:
a、通过在web 服务器中配置编码格式:tomcat 中,在 Connector 中添加URIEncoding="UTF-8";
1.2、post 请求乱码
post 请求中,请求参数分两部份,
1.2.1、url?参数,
- 【Spark十六】: Spark SQL第二部分数据源和注册表的几种方式
bit1129
spark
Spark SQL数据源和表的Schema
case class
apply schema
parquet
json
JSON数据源 准备源数据
{"name":"Jack", "age": 12, "addr":{"city":"beijing&
- JVM学习之:调优总结 -Xms -Xmx -Xmn -Xss
BlueSkator
-Xss-Xmn-Xms-Xmx
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。典型设置:
java -Xmx355
- jqGrid 各种参数 详解(转帖)
BreakingBad
jqGrid
jqGrid 各种参数 详解 分类:
源代码分享
个人随笔请勿参考
解决开发问题 2012-05-09 20:29 84282人阅读
评论(22)
收藏
举报
jquery
服务器
parameters
function
ajax
string
- 读《研磨设计模式》-代码笔记-代理模式-Proxy
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/*
* 下面
- 应用升级iOS8中遇到的一些问题
chenhbc
ios8升级iOS8
1、很奇怪的问题,登录界面,有一个判断,如果不存在某个值,则跳转到设置界面,ios8之前的系统都可以正常跳转,iOS8中代码已经执行到下一个界面了,但界面并没有跳转过去,而且这个值如果设置过的话,也是可以正常跳转过去的,这个问题纠结了两天多,之前的判断我是在
-(void)viewWillAppear:(BOOL)animated
中写的,最终的解决办法是把判断写在
-(void
- 工作流与自组织的关系?
comsci
设计模式工作
目前的工作流系统中的节点及其相互之间的连接是事先根据管理的实际需要而绘制好的,这种固定的模式在实际的运用中会受到很多限制,特别是节点之间的依存关系是固定的,节点的处理不考虑到流程整体的运行情况,细节和整体间的关系是脱节的,那么我们提出一个新的观点,一个流程是否可以通过节点的自组织运动来自动生成呢?这种流程有什么实际意义呢?
这里有篇论文,摘要是:“针对网格中的服务
- Oracle11.2新特性之INSERT提示IGNORE_ROW_ON_DUPKEY_INDEX
daizj
oracle
insert提示IGNORE_ROW_ON_DUPKEY_INDEX
转自:http://space.itpub.net/18922393/viewspace-752123
在 insert into tablea ...select * from tableb中,如果存在唯一约束,会导致整个insert操作失败。使用IGNORE_ROW_ON_DUPKEY_INDEX提示,会忽略唯一
- 二叉树:堆
dieslrae
二叉树
这里说的堆其实是一个完全二叉树,每个节点都不小于自己的子节点,不要跟jvm的堆搞混了.由于是完全二叉树,可以用数组来构建.用数组构建树的规则很简单:
一个节点的父节点下标为: (当前下标 - 1)/2
一个节点的左节点下标为: 当前下标 * 2 + 1
&
- C语言学习八结构体
dcj3sjt126com
c
为什么需要结构体,看代码
# include <stdio.h>
struct Student //定义一个学生类型,里面有age, score, sex, 然后可以定义这个类型的变量
{
int age;
float score;
char sex;
}
int main(void)
{
struct Student st = {80, 66.6,
- centos安装golang
dcj3sjt126com
centos
#在国内镜像下载二进制包
wget -c http://www.golangtc.com/static/go/go1.4.1.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.4.1.linux-amd64.tar.gz
#把golang的bin目录加入全局环境变量
cat >>/etc/profile<
- 10.性能优化-监控-MySQL慢查询
frank1234
性能优化MySQL慢查询
1.记录慢查询配置
show variables where variable_name like 'slow%' ; --查看默认日志路径
查询结果:--不用的机器可能不同
slow_query_log_file=/var/lib/mysql/centos-slow.log
修改mysqld配置文件:/usr /my.cnf[一般在/etc/my.cnf,本机在/user/my.cn
- Java父类取得子类类名
happyqing
javathis父类子类类名
在继承关系中,不管父类还是子类,这些类里面的this都代表了最终new出来的那个类的实例对象,所以在父类中你可以用this获取到子类的信息!
package com.urthinker.module.test;
import org.junit.Test;
abstract class BaseDao<T> {
public void
- Spring3.2新注解@ControllerAdvice
jinnianshilongnian
@Controller
@ControllerAdvice,是spring3.2提供的新注解,从名字上可以看出大体意思是控制器增强。让我们先看看@ControllerAdvice的实现:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Co
- Java spring mvc多数据源配置
liuxihope
spring
转自:http://www.itpub.net/thread-1906608-1-1.html
1、首先配置两个数据库
<bean id="dataSourceA" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close&quo
- 第12章 Ajax(下)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- BW / Universe Mappings
blueoxygen
BO
BW Element
OLAP Universe Element
Cube Dimension
Class
Charateristic
A class with dimension and detail objects (Detail objects for key and desription)
Hi
- Java开发熟手该当心的11个错误
tomcat_oracle
java多线程工作单元测试
#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为
- 推行国产操作系统的优劣
yananay
windowslinux国产操作系统
最近刮起了一股风,就是去“国外货”。从应用程序开始,到基础的系统,数据库,现在已经刮到操作系统了。原因就是“棱镜计划”,使我们终于认识到了国外货的危害,开始重视起了信息安全。操作系统是计算机的灵魂。既然是灵魂,为了信息安全,那我们就自然要使用和推行国货。可是,一味地推行,是否就一定正确呢?
先说说信息安全。其实从很早以来大家就在讨论信息安全。很多年以前,就据传某世界级的网络设备制造商生产的交
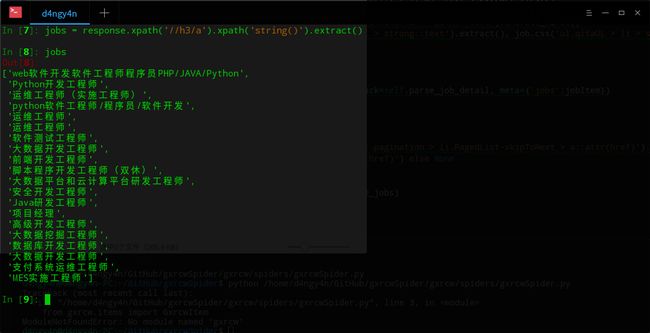
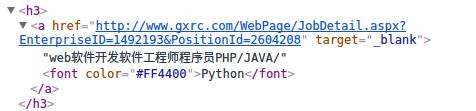
 XPath常用表达式
XPath常用表达式 Xpath表达式通配符
Xpath表达式通配符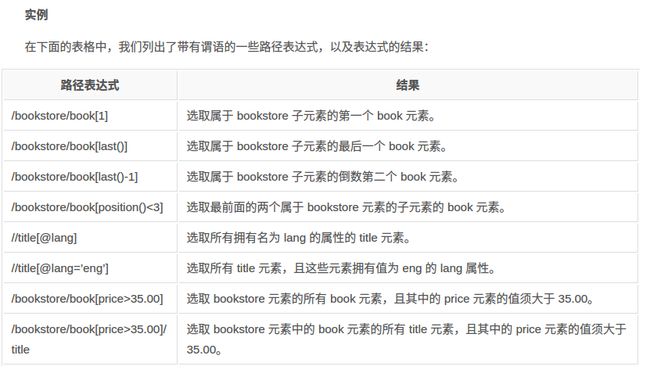 Xpath表达式实例
Xpath表达式实例