1.两种本地窗口
1.面向管理者SurfaceFlinger:FrameBufferNativeWindow
2.面向应用程序:Surface
2.为什么需要两种类型的本地窗口
2.1 一种本地窗口的情况
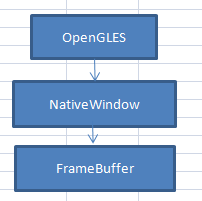
NativeWindow管理FrameBuffer,OpenGL就像一台通用的打印机,只要输入正确的命令,就能按照要求输出结果,而NativeWindow就是画布,用来承载OpenGL的输出结果。
加入系统中只有一个需要显示UI的程序,那么这种模型是可以的,但是如果有多个UI程序呢?一个系统设备只会有一个帧缓冲区FrameBuffer,而这种模型中,每个应用程序都需要自己使用和管理FrameBuffer,这就是说肯定会造成因同时操作而引起混乱。
2.2 改进
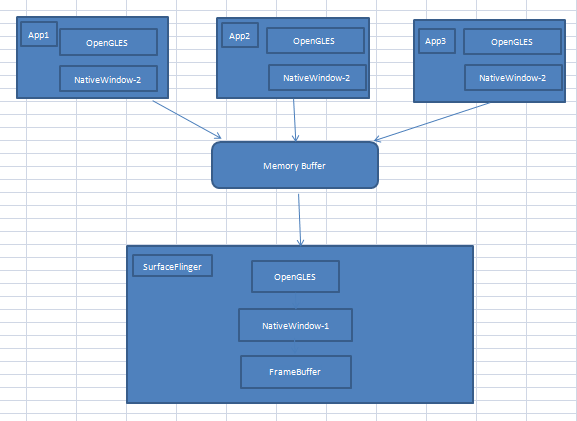
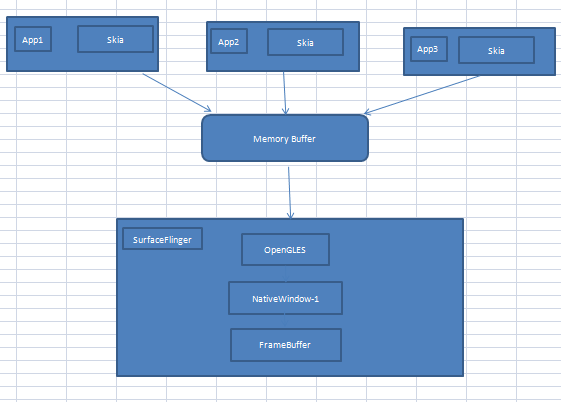
这个模型中,我们有了两个本地窗口,第一类窗口时能直接显示在终端屏幕上的,它使用了帧缓冲区,而第二类本地窗口实际上是从内存缓冲区中分配空间。
当系统中存在多个需要显示UI的应用程序时,一方面这种改进保证了每个应用程序都能获得一个本地窗口,另一方面这些窗口也都可以被有序的显示到终端屏幕上,因为SurfaceFlinger会收集所有程序的显示需求,对它们进行统一的图像混合操作,然后输出到自己的NativeWindow-1上。
应用程序可以采用OpenGLES也可采用Skia等第三方的图形库,只要与SurfaceFlinger之间的协议保持不变即可。Android系统同时采用了这两种方案。
3.NativeWindowType
EGL需要通过本地窗口来为OpenGLES创建环境
EGLSurface eglCreateWindowSurface(EGLDisplay dpy,
EGLConfig config,NativeWindowType window,const EGLint *attrib_list)
由于OpenGLES并不是针对某一特定类型的操作系统设计的,因而需要考虑兼容性和移植性,对于android系统,NativeWindowType 指的是ANativeWindow。
struct ANativeWindow
{
struct android_native_base_t common;
const uint32_t flags;
const int minSwapInterval;//最小交换时间间隔
const int maxSwapInterval; //最大交换时间间隔
//密度,以dpi为单位
const float xdpi;
const float ydpi;
//为OEM定制驱动预留的空间
intptr_t oem[4];
int (*setSwapInterval)(struct ANativeWindow* window,
int interval);
int (*query)(const struct ANativeWindow* window,
int what, int* value);
int (*perform)(struct ANativeWindow* window,
int operation, ... );
int (*dequeueBuffer)(struct ANativeWindow* window,
struct ANativeWindowBuffer** buffer, int* fenceFd);
int (*queueBuffer)(struct ANativeWindow* window,
struct ANativeWindowBuffer* buffer, int fenceFd);
int (*cancelBuffer)(struct ANativeWindow* window,
struct ANativeWindowBuffer* buffer, int fenceFd);
};
ANativeWindow描述了一个本地窗口的形态和功能
4.FrameBufferNativeWindow
4.1 构造方法
FramebufferNativeWindow::FramebufferNativeWindow()
: BASE(), fbDev(0), grDev(0), mUpdateOnDemand(false)
{
hw_module_t const* module;
//加载驱动层的Gralloc
if (hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module) == 0) {
//打开framebuffer
err = framebuffer_open(module, &fbDev);
//打开gralloc
err = gralloc_open(module, &grDev);
// 根据fb属性获取buffer数,如果没有就是用最小的(2)
if(fbDev->numFramebuffers >= MIN_NUM_FRAME_BUFFERS &&
fbDev->numFramebuffers <= MAX_NUM_FRAME_BUFFERS){
mNumBuffers = fbDev->numFramebuffers;
} else {
mNumBuffers = MIN_NUM_FRAME_BUFFERS;
}
//可用的buffer数,最初是所有都可用
mNumFreeBuffers = mNumBuffers;
mBufferHead = mNumBuffers-1;
//初始化每个buffer
for (i = 0; i < mNumBuffers; i++) {
buffers[i] = new NativeBuffer(
static_cast(fbDev->width),
static_cast(fbDev->height),
fbDev->format, GRALLOC_USAGE_HW_FB);
}
//通过grDev为每个buffer分配空间
for (i = 0; i < mNumBuffers; i++) {
err = grDev->alloc(grDev,
static_cast(fbDev->width),
static_cast(fbDev->height),
fbDev->format, GRALLOC_USAGE_HW_FB,
&buffers[i]->handle, &buffers[i]->stride);
}
//为本地窗口赋属性值
const_cast(ANativeWindow::flags) = fbDev->flags;
const_cast(ANativeWindow::xdpi) = fbDev->xdpi;
const_cast(ANativeWindow::ydpi) = fbDev->ydpi;
const_cast(ANativeWindow::minSwapInterval) =
fbDev->minSwapInterval;
const_cast(ANativeWindow::maxSwapInterval) =
fbDev->maxSwapInterval;
} else {
ALOGE("Couldn't get gralloc module");
}
//接口实现
ANativeWindow::setSwapInterval = setSwapInterval;
ANativeWindow::dequeueBuffer = dequeueBuffer;
ANativeWindow::queueBuffer = queueBuffer;
ANativeWindow::query = query;
ANativeWindow::perform = perform;
}
1.加载HAL层的Gralloc模块
2.打开fb和gralloc设备
3.根据设备属性来给FrameBufferNativeWindow赋初始值
4.根据FrameBufferNativeWindow的实现来填充ANativeWindow的协议
5.其他一些必要的初始化
4.1.1 双缓冲机制(为什么有多个buffer,最少两个)
假设只采用一个buffer,那么意味着我们直接以屏幕为画板实时画画,我们画什么屏幕就显示什么,如果现在有一个画面其中有多个图形,每个图形需要1秒能画完,那么画完这个画面需要5秒,不同的时间点用户在屏幕上看到不同的画面(随意时间推移五个图形逐渐出现),也就是说用户将看到一个不断刷新的画面,通俗的讲就是画面很卡,特别是对于图像刷新很频繁的场景用户体验就会很差。
如果可以等到这个画面绘制完成在刷新到屏幕,那么用户任何时候看到的都是完整的画面,问题就解决了。
4.1.2 buffer空间的分配
在FrameBufferNativeWindow的构造函数中,第一个for循环先给各个buffer创建相应的实例,其中的属性都来源于fbDev,然后就是调用alloc方法
err = grDev->alloc(grDev,
static_cast(fbDev->width),
static_cast(fbDev->height),
fbDev->format, GRALLOC_USAGE_HW_FB,
&buffers[i]->handle, &buffers[i]->stride);
GRALLOC_USAGE_HW_FB:缓冲区用于framebuffer设备
当前可用的缓冲区数量有mNumFreeBuffers管理,在程序的后续运行中,始终由mBufferHead来指向下一个将被申请的buffer,也就是说每当用户想FrameBufferNativeWidonw申请一个buffer(dequeueBuffer),mBufferHead就会增加1,一旦超过最大值,就会变为0,如此实现了循环管理。
4.2dequeueBuffer
int FramebufferNativeWindow::dequeueBuffer(ANativeWindow* window,
ANativeWindowBuffer** buffer, int* fenceFd)
{
FramebufferNativeWindow* self = getSelf(window);
Mutex::Autolock _l(self->mutex);
int index = self->mBufferHead++;
if (self->mBufferHead >= self->mNumBuffers)
self->mBufferHead = 0;
// 如果没有可用的缓冲区
while (self->mNumFreeBuffers < 2) {
self->mCondition.wait(self->mutex);
}
// 被唤醒,也就是有了可用的缓冲区
self->mNumFreeBuffers--;
self->mCurrentBufferIndex = index;
*buffer = self->buffers[index].get();
*fenceFd = -1;
return 0;
}
1.把参数ANativeWindow转成FramebufferNativeWindow
2.获取一个锁,这里采用的是AutoLock,也就是函数结束会自动释放
3.首先index得到的是mBufferHead所代表的当前位置,然后mBufferHead加1,由于我们循环使用多个缓冲区,所以如果这个变量值大于等于mNumBuffers,就需要将它置为0
4.mBufferHead并不代表它所指向的buffer是可用的,如果当前mNumFreeBuffers表名已经没有多余的缓冲空间,我们就需要等待有人释放buffer后才能继续操作
5.获取到一个可用的buffer,mNumFreeBuffers减1,另外mBufferHead做自增处理
5.Surface
同样继承自ANativeWindow,Surface是面向android系统中所有UI应用程序的,它承担着应用程序中UI的显示需求,因此它的内部实现至少需要考虑如下几点
1.面向上层实现提供绘制图像的画板,这个本地窗口分配的内存空间不属于帧缓冲区,那么是谁分配?如何管理?
2.与SurfaceFlnger如何分工?显然SurfaceFlinger需要收集系统中所有应用程序绘制的图像数据,然后集中显示到物理屏幕上,这个过程中,Surface扮演了什么角色?
Surface::Surface(
const sp& bufferProducer,
bool controlledByApp)
: mGraphicBufferProducer(bufferProducer),
mGenerationNumber(0)
{
// 为AnativeWindow中的函数赋值Initialize the ANativeWindow function pointers.
ANativeWindow::setSwapInterval = hook_setSwapInterval;
ANativeWindow::dequeueBuffer = hook_dequeueBuffer;
ANativeWindow::cancelBuffer = hook_cancelBuffer;
ANativeWindow::queueBuffer = hook_queueBuffer;
ANativeWindow::query = hook_query;
ANativeWindow::perform = hook_perform;
//变量赋值,因为用户还没有发起申请,所以大部分初值是0
mReqWidth = 0;
mReqHeight = 0;
mReqFormat = 0;
mReqUsage = 0;
//......
}
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
uint32_t reqWidth;
uint32_t reqHeight;
bool swapIntervalZero;
PixelFormat reqFormat;
uint32_t reqUsage;
{
Mutex::Autolock lock(mMutex);
reqWidth = mReqWidth ? mReqWidth : mUserWidth;
reqHeight = mReqHeight ? mReqHeight : mUserHeight;
swapIntervalZero = mSwapIntervalZero;
reqFormat = mReqFormat;
reqUsage = mReqUsage;
}
int buf = -1;
sp fence;
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, swapIntervalZero,
reqWidth, reqHeight, reqFormat, reqUsage);
Mutex::Autolock lock(mMutex);
sp& gbuf(mSlots[buf].buffer);
if ((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == 0) {
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
if (result != NO_ERROR) {
mGraphicBufferProducer->cancelBuffer(buf, fence);
return result;
}
}
*buffer = gbuf.get();
return OK;
}
1.图形缓冲区一定有宽高属性
2.真正执行dequeueBuffer操作的是mGraphicBufferProducer,Surface的这个核心成员可以是构造参数传入,也可以是子类通过调用setGraphicBufferProducer
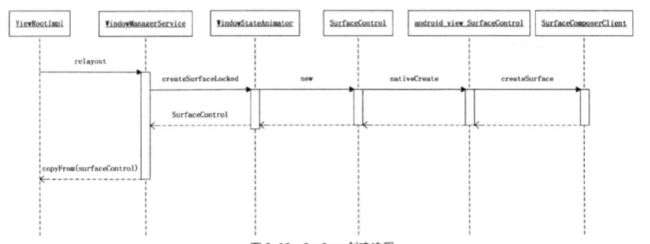
ViewRootImpl持有一个java层的Surface对象,初始时是空的,后续ViewRootImpl将向WindowManagerService发起relayout请求,此时Surface才被赋值。WindowManagerService会先让WindowStateAnimator生成一个SurfaceControl,然后通过Surface.copyFrom函数将其复制到Surface。这个复制函数会通过native接口生成本地Surface对象,JNI函数nativeCreateFromSurfaceControl将从SurfaceControl中提取出本地Surface对象,最后记录到java层Surface对象中。
Surface由SurfaceControl管理,而后者又由SurfaceComposerClient创建
sp SurfaceComposerClient::createSurface(
const String8& name,
uint32_t w,
uint32_t h,
PixelFormat format,
uint32_t flags)
{
sp sur;
if (mStatus == NO_ERROR) {
sp handle;
sp gbp;
//创建Surface,注意gbp
status_t err = mClient->createSurface(name, w, h, format, flags,
&handle, &gbp);
//SurfaceControl是在“本地”创建的
if (err == NO_ERROR) {
sur = new SurfaceControl(this, handle, gbp);
}
}
return sur;
}
SurfaceComposerClient的服务端是谁?
void SurfaceComposerClient::onFirstRef() {
sp sm(ComposerService::getComposerService());
if (sm != 0) {
sp conn = sm->createConnection();
if (conn != 0) {
mClient = conn;
mStatus = NO_ERROR;
}
}
}
5.1 三个匿名binder
ISurfaceComposer:crateConnection创建ISurfaceComposerClient
ISurfaceComposerClient:crateSurface创建Surface,其中使用到IGraphicBufferProducer
IGraphicBufferProducer:管理buffer
SurfaceFlinger虽然在ServiceManager中注册的名字是“SurfaceFlinger”,但是在服务器端实现的Binder接口确实ISurfaceComposer,