前面一篇文章我们详细介绍了分布式存储 HDFS,想必小伙伴们已经对分布式的 master/slave 架构有了深刻的理解,接下来我们再深入理解一下分布式计算的鼻祖——MapReduce。说到鼻祖,一些老的程序员可能会反驳说,“在 MapReduce 之前,已经有像 MPI 这种非常成熟的并行编程技术了,鼻祖怎么会是 MapReduce 呢?” 这里需要说明一下,MPI 与 MapReduce 本身并不具有可比性,因为 MPI 是一个信息传递应用程序接口,而 MapReduce 是一种分布式计算框架。换句话说,如果你感兴趣的话,完全可以使用 MPI 去重新实现一个类似 MapReduce 框架的功能。MPI 编程原理和多线程逻辑比较类似,需要借助很多的互斥信号量机制(锁)实现不同任务之间的同步,而 MapReduce 给我们屏蔽了底层的技术实现,并抽象出 Map 和 Reduce 两个函数,大大降低了编程难度,而且 MapReduce 具有容错性好,硬件价格低和可扩展性强等众多优点。
MapReduce 模型的设计哲学
MapReduce 作为一个分布式计算编程框架其实早已经被 Spark 所替代了,那既然如此,为什么我们还要花大篇幅去讲解呢?这是因为 MapReduce 的策略和理念实在是太经典了且影响深远,后来的很多分布式计算框架也是遵循这个思路和理念进行相应设计。深入理解 MapReduce 框架的思想原理对我们今后的学习将大有裨益。
MapReduce 采用分而治之的策略 将非常庞大的数据集,切分成非常多的小分片,(分片数默认为文件的 block 数量,可修改)然后为每一个小分片单独地启动一个 map 任务,这样就可以通过多个 map 任务,在多个机器上并行处理。
MapReduce 遵循移动计算而不是移动数据的理念 这个理念我们已经在上一篇讲过了,这里就不再重复介绍了,小伙伴们可以关注我的,去数据科学之路这个系列中找到。
MapReduce 的工作流程
在开始之前,我们首先要先明确一个事实,那就是 Hadoop2.0 对比 Hadoop1.0 是一次里程碑的升级,尤其对于 MapReduce 更是如此,在 MapReduce1.0 中,MapReduce 不仅是作为分布式计算的编程模型,还大包大揽地兼备了资源管理和作业控制这两个大功能,这就导致了当集群中的 MR 任务很多时,会造成 JobTracker 很大的内存开销,严重制约了整个集群的性能,另外 JobTracker 存在单点故障,以及资源利用率低且无法支持多种计算框架等严重问题。当然设计者也意识到了上述问题的存在,所以在 MapReduce2.0 中,将 MapReduce1.0 中的资源管理和作业控制两大功能从 MapReduce 框架中抽取出来,并加以优化形成了 Yarn,而 MapReduce2.0 则变成了纯粹的分布式计算模型,所以我们本篇只讲解 MapReduce 的计算流程,对于资源管理和作业控制的相关内容我们将会在下一篇 Yarn 中详细介绍。

我们可以从以上 MapReduce 任务示意图中发现,整个 MapReduce 任务可以大致分为5个步骤:
- input 阶段 在执行 MR 之前,原始数据被分割成若干 split,然后每个 split 会被分解成一个个
key-value对。(注意这里的key代表的是字符偏移量,并不是行数,类型为 LongWritable,一个 map 会处理一个 split 的所有记录)
public interface InputFormat {
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
RecordReader getRecordReader(InputSplit split,
JobConf job,
Reporter reporter) throws IOException;
}
我们可以看到,上面的 InputFormat 接口主要实现了两个功能,getSplits 方法将输入的数据切分成 splits,其函数默认的切分块大小为 max(minsize,min(maxSize,blockSize)) 即 HDFS 中的块大小。getRecordReader 方法是将每个 split 解析成 RecordReaderfiles → splits → RecordReader
- map 阶段 Mapper 即是对input 阶段输出的 split 中每一条 RecordReader
RecordReader - shuffle 阶段 shuffle 阶段是整个 MR 过程中最为复杂的部分,也是 MR 性能调优的关键点:
- Partition:默认采用 hash 算法进行分区,MR 框架会根据 reduce 任务的个数来确定分区的个数,具有相同的 key 值的键值对最终会被传输到相同的 reduce 任务进行处理
- Sort:将 map 输出的结果进行排序,例如,将
("hello","1"),("hadoop","1")根据字典顺序重新排序为:("hadoop","1"),("hello","1") - Combine:数据传输之前在本地做一次 reduce 操作,例如,将
("hello","1"),("hadoop","1"),("hello","1"),("hadoop","1")在本地合并为("hadoop","2"),("hello","2") - Spill/Merge:map 阶段的输出放入了一个环形缓冲区,当缓冲区数据溢出时,需要将缓冲区中的数据溢写到本地硬盘,在溢写到硬盘成为
spill file之前经历了Partition,Sort,(Combine)两个或者三个阶段,其中(Combine)为可选阶段。之后再将很多spill file在硬盘上做 Merge 处理,得到big spill file
以上 shullfe 为 map 端的 shuffle,接下来是 reduce 端的 shuffle: - Copy:reduce 任务将 map 的输出结果
big spill file拉取到 reduce 端,当接收的数据量不大时,直接存放到缓存中,随着缓存文件增多,MR 将它们合并成一个更大的有序文件,合并的过程也称作 reduce 端的 Merge,最终合并成 Partition 个数个有序文件作为 reduce 阶段的输入,整个 shuffle 阶段的数据格式list(
4.reduce 阶段 Reducer 是对一个列表的元素进行适当的合并,用户自定义的 reduce 函数将并行操作整个 shuffle 阶段的输出
5.output 阶段 MR 框架收集所有的 reduce 阶段的输出,并按照 k2 对整个结果做排序产生最终的结果
第一个也是最后一个 MR 程序——WordCount
上面我们介绍了 MR 框架的分布式计算原理,接下来我们将动手写一个 MR 程序来更深刻地理解一下 MR 的整个分布式计算流程。
首先编辑两个文件 word1.txt 和 word2.txt,内容为:
word1.txt
hadoop mapreduce yarn
hello hi hadoop
oozie azkaban hive hueword2.txt
spark flink spark streaming
spark sql spark mllib
hadoop hdfs
将两个文件存储到 HDFS 中,hadoop fs -put word* /tmp/hive/ainidata/test
以下是一个词频统计程序的 java 代码:
package wordCount;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCountDemo {
public static class Map extends MapReduceBase implements Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer {
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCountDemo.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
// 输入
FileInputFormat.setInputPaths(conf, new Path(args[0]));
// 输出目录不可以存在
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
将代码打包成 wordCount.jar 放到集群上运行命令 hadoop jar wordCount.jar wordCount.WordCountDemo /tmp/hive/ainidata/test /tmp/hive/ainidata/test/output
程序运行结束后,我们用命令 hadoop fs -ls /tmp/hive/ainidata/test/output 和 hadoop fs -cat /tmp/hive/ainidata/test/output/part-00000 查看结果:

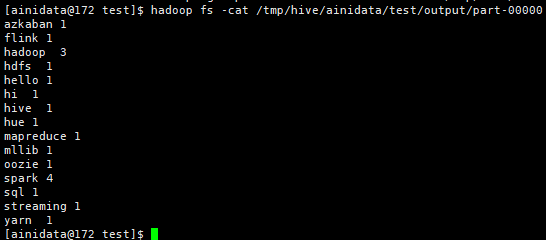
下面,我们将上面的代码例子,画成流程图,进一步加深小伙伴们对 MR 程序过程的理解:
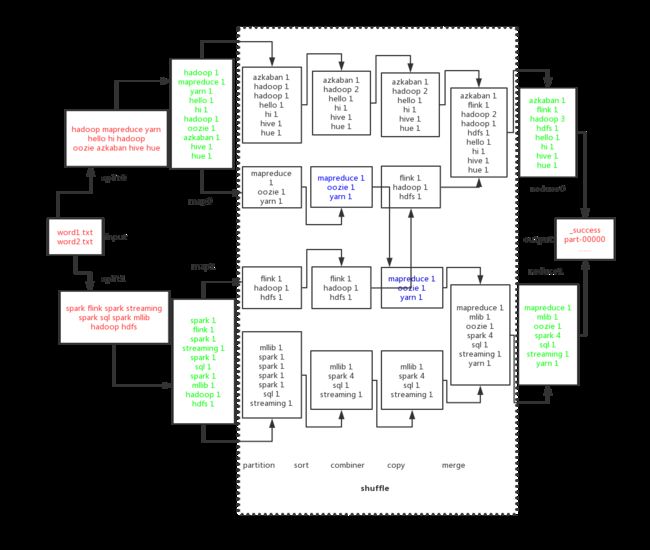
1、Input 阶段
word1.txt
hadoop mapreduce yarn
hello hi hadoop
oozie azkaban hive hueword2.txt
spark flink spark streaming
spark sql spark mllib
hadoop hdfs
将以上两个文件 word1.txt 和 word2.txt 作为 wordCount 程序的输入,InputFormat 默认将两个文件切分成如下两个 split:
split0
hadoop mapreduce yarn
hello hi hadoop
oozie azkaban hive huesplit1
spark flink spark streaming
spark sql spark mllib
hadoop hdfs
2、Map 阶段
两个 split 默认会分配给两个 Mapper 来处理,在 wordCount 例子中,这一阶段直接把输入的 split 分解为 单词 和 1,其中单词就是 key,对应的 1 就是 value,那么对应的两个 Mapper 输出就是:
map0
hadoop 1
mapreduce 1
yarn 1
hello 1
hi 1
hadoop 1
oozie 1
azkaban 1
hive 1
hue 1map1
spark 1
flink 1
spark 1
streaming 1
spark 1
sql 1
spark 1
mllib 1
hadoop 1
hdfs 1
3、Shuffle 阶段
从上图可以发现,整个 shuffle 阶段包含 Partition、Sort、Combine、Copy 和 Merge 5个主要部分:
- Partition 分区,具有相同的 key 会在相同的分区,结合我们上述的例子,这里假设有两个 Reducer,对于两个 split 的 Partition 结果为:
map0 partition1
azkaban 1
hadoop 1
hadoop 1
hello 1
hi 1
hive 1
hue 1
map0 partition2
mapreduce 1
oozie 1
yarn 1map1 partition1
flink 1
hadoop 1
hdfs 1
map1 partition2
mllib 1
spark 1
spark 1
spark 1
spark 1
sql 1
streaming 1
- Sort 排序,按照字典顺序对
key进行排序,为了能将主流程放进一张图中,例子示意图中,我们压缩了 Partition 和 Sort,所以 Partition 的输出其实是经过排序之后结果,这里不再重复列出了 - Combine 在 Map 端做一次 Reduce 操作,为了缓解 Reduce 的计算压力和 Copy 部分的网络传输压力,Combine 的输出结果为:
map0 partition1
azkaban 1
hadoop 2
hello 1
hi 1
hive 1
hue 1
map0 partition2
mapreduce 1
oozie 1
yarn 1map1 partition1
flink 1
hadoop 1
hdfs 1
map1 partition2
mllib 1
spark 4
sql 1
streaming 1
- Copy 这个过程是将 map 阶段的输出拉取到 reduce 端,那么根据前面的 partition,输出到 reduce 端的结果为:
reduce0 partition1 = map0 partition1
azkaban 1
hadoop 2
hello 1
hi 1
hive 1
hue 1
reduce0 partition2 = map1 partition1
flink 1
hadoop 1
hdfs 1reduce1 partition1 = map0 partition2
mapreduce 1
oozie 1
yarn 1
reduce1 partition2 = map1 partition2
mllib 1
spark 4
sql 1
streaming 1
- Merge Copy 得到的文件是从不同的 Mapper 拉取获得,所以需要对他们进行合并成为一个文件,即一个 Reduce 对应一个文件,这步操作就是 Merge 的工作,Merge 之后的结果为:
reduce0
azkaban 1
flink 1
hadoop 2
hadoop 1
hdfs 1
hello 1
hi 1
hive 1
hue 1reduce1
mapreduce 1
mlib 1
oozie 1
spark 4
sql 1
streaming 1
yarn 1
4、Reduce 阶段
根据输入内容做最后的统计,结果如下:
reduce0
azkaban 1
flink 1
hadoop 3
hdfs 1
hello 1
hi 1
hive 1
hue 1reduce1
mapreduce 1
mlib 1
oozie 1
spark 4
sql 1
streaming 1
yarn 1
5、Output 阶段
至此整个 wordCount 流程就结束了,我们将统计的结果会存入两个输出文件,注意,有几个
Reduce 就会有几个输出文件,我们这里只有一个输出文件是因为没有设置 Reduce 的数量,默认只有1个,可以在代码中加入 job.setNumReduceTasks(2) 来指定输出文件个数为 2。
至此,我想小伙伴们都明白了 MR 的计算过程了吧!