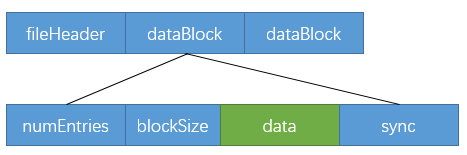
avro文件结构
avro文件格式大致如下(引用自avro官网Specification的Object Container Files一节)
- A file header, followed by
- one or more file data blocks
其中,datablock又可分为
- numEntries:该datablock中的记录条数;
- blockSize:该datablock的大小;
- data:存储的数据;
- sync:同步位
整个avro的文件布局如下:
本文基于avro-1.7.6,看下代码是如何实现的。
avro用于写出数据的关键类是DataFileWriter和ReflectDatumWriter。其中,DataFileWriter负责整个avro的文件格式,即fileHeader + dataBlocks,ReflectDatumWriter只负责dataBlock中的data。
这两个类的使用可在AvroPairOutputFormat中看到,有关代码如下:
public class AvroPairOutputFormat extends ExtFileOutputFormat {
public RecordWriter getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
//声明writer(使用了DataFileWriter和ReflectDatumWriter)
final DataFileWriter> writer = new DataFileWriter>(
new ReflectDatumWriter>((Schema)null,ReflectDataEx.get()));
...
//创建writer
writer.create(Pair.getPairSchema(keySchema, valueSchema), path
.getFileSystem(job.getConfiguration()).create(path));
//返回RecordWriter实例
return new RecordWriter() {
//使用writer写出
@Override
public void write(K key, V value) throws IOException {
//将(key, value)按照各自的schema写出
writer.append(new Pair(key, keySchema, value, valueSchema));
}
...
}
}
}
DataFileWriter
fileHeader
从DataFileWriter的create()中可以看到file header的生成过程,截取的代码如下。源码的注释中也清晰的标注出了magic、metadata和sync(直接以文本打开一个avro文件,可在文件开头看到这些东西)。
public DataFileWriter create(...) {
...
vout.writeFixed(DataFileConstants.MAGIC); // write magic
vout.writeMapStart(); // write metadata
vout.setItemCount(meta.size());
for (Map.Entry entry : meta.entrySet()) {
vout.startItem();
vout.writeString(entry.getKey());
vout.writeBytes(entry.getValue());
}
vout.writeMapEnd();
vout.writeFixed(this.sync); // write initial sync
...
}
dataBlock
DataFileWriter的append()按照schema将当前的这条数据写入缓冲区,并在缓冲区达到一定大小时,写出一个DataBlock(这里的“写出”并非落盘,应该是写到更大的一个缓冲区中去了)。
public void append(D datum) throws IOException {
...
//按照schema将该条数据写入缓冲区(使用的是ReflectDatumWriter)
this.dout.write(datum, this.bufOut);
...
++this.blockCount;
//写出一个DataBlock
this.writeIfBlockFull();
}
writeIfBlockFull()的调用层级如下:
writeIfBlockFull()
----writeBlock()
--------writeBlockTo()
最终在writeBlockTo()中可以看到DataBlock的写出。
void writeBlockTo() {
e.writeLong(this.numEntries);
e.writeLong(this.blockSize);
e.writeFixed(this.data, offset, this.blockSize);
e.writeFixed(sync);
}
ReflectDatumWriter
ReflectDatumWriter按照schema写出data。
schema
通常所说的schema指的是一个json串,每个avro文件的开头有一部分就是schema。一个schema串的示例如下:
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings.",
"fields" : [
{"name": "left", "type": "string"},
{"name": "right", "type": "string" }
]
}
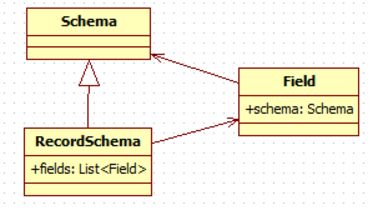
在代码中,有对应的Schema类。Schema在代码里是个抽象类,它有很多具体的实现如IntSchema, LongSchema, RecordSchema等。
以RecordSchema为例,一个recordSchema包含一个field列表,每个field又有自己的schema。下图是RecordSchema、Field、Schema类的关系。
写data
ReflectDatumWriter.write()会调用GenericDatumWriter.write(),GenericDatumWriter.write()会根据不同的schema调用不同的写方法。

本文中类似Class.method()的表达方式并不是指这个method()是静态的,只是为了书写方便而已。
比如schema的type为record时,调用的是writeRecord()。一个recordSchema包含一个field列表,writeRecord()会遍历field列表,对于每个field调用writeField(),而writeField()方法又再次递归的调用了write()。最后,会一直递归到对基本类型的写出,如writeLong()。
GenericDatumWriter.write()的部分代码如下:
protected void write(Schema schema, Object datum, Encoder out)
throws IOException {
try {
switch (schema.getType()) {
case RECORD: writeRecord(schema, datum, out); break;
case ENUM: writeEnum(schema, datum, out); break;
case ARRAY: writeArray(schema, datum, out); break;
case MAP: writeMap(schema, datum, out); break;
......
在写出基本类型时,使用的是BufferedBinaryEncoder(见DataFileWriter.init()中对this.vout的初始化)。BufferedBinaryEncoder维护了一个字节数组buf和一个位置pos。它将数据写入buf中,并将pos向后移对应的大小,下次再从pos处开始写。如果剩余的空间不够存储这次要写的数据,就将buf中的数据先刷出去(刷到哪了不清楚。。。)。BufferedBinaryEncoder在写出基本类型时,会对数据进行一定的编码。所有的编码算法均在BinaryData类中。

Schema
上面,ReflectDatumWriter按照schema写data,那schema又是如何生成的呢?
schema一般有两种生成方式:
- 根据json串生成;
- 根据java类及反射机制生成。
根据json串
解析json串,然后生成一个Schema的实例。avro使用的json解析是org.codehaus.jackson。
这里有段简短的例子,可用来调试。
- 引入依赖
org.apache.avro
avro
1.7.6
- 配置schema文件StringPair.avsc
{
"type": "record",
"name": "StringPair",
"doc": "A pair of strings.",
"fields" : [
{"name": "left", "type": "string"},
{"name": "right", "type": "string" }
]
}
- 主体代码
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(this.getClass().getResourceAsStream("StringPair.avsc"));
parser.parse()根据输入流创建了一个json的解析器,读取json文件,生成了jsonNode。Schema.parse(jsonNode, names)通过jsonNode读取json串中的内容(如type、fields等),根据不同的type构建不同的schema。
Schema.parse(jsonNode, names)参数names:一个parser有一个names,用来缓存解析过的schema。这样在遇到重复的schema时,可以直接从缓存中拿,无需再解析。
根据java类及反射机制
当没有json串时,调用的是ReflectData.createSchema()。
有关类的继承关系如下图所示:

ReflectData.createSchema()根据传入的type调用不同的方法,如Schema.create(Schema.Type.INT), Schema.createMap(), Schema.createRecord()。
一般工作中需要写入avro文件的都是一些复杂的类。下面是type为class时,schema的生成过程。
- 先生成一个不包含任何field的recordSchema;
- 通过java反射机制遍历class中的所有字段,对每个字段:
1)生成该字段的schema;
2)根据schema生成field; - 将所有的field加入到recordSchema中。
对应的关键代码如下:
List fields = new ArrayList();
schema = Schema.createRecord(name, null /* doc */, space, error); //新建recordSchema
for (Field field : getCachedFields(c)) { //通过反射机制遍历class的所有字段
if ((field.getModifiers()&(Modifier.TRANSIENT|Modifier.STATIC))==0 //跳过transient 、static以及注解忽略的字段
&& !field.isAnnotationPresent(AvroIgnore.class)) {
Schema fieldSchema = createFieldSchema(field, names); //生成该field的schema(其中又递归调用了createSchema(),或是其他如Schema.parse())
Schema.Field recordField = new Schema.Field(fieldName, fieldSchema, null, defaultValue); //生成field
fields.add(recordField); //将field加入fields
}
}
schema.setFields(fields); //为recordSchema添加fields
transient: Java的serialization提供了一种持久化对象实例的机制。当持久化对象时,可能有一个特殊的对象数据成员,我们不想用serialization机制来保存它。为了在一个特定对象的一个域上关闭serialization,可以在这个域前加上关键字transient。
也就是说,ReflectData()会基于反射机制获取类包含的字段,以及各字段的类型,并根据这些信息生成schema。