CUDA编程(六): 利用好shared memory
CUDA编程(五): 并行规约优化
CUDA编程(四): CPU与GPU的矩阵乘法对比
CUDA编程(三): GPU架构了解一下!
CUDA编程(二): Ubuntu下的CUDA10.x环境搭建
CUDA编程(一): 老黄和他的核弹们
目录
- 前言
- 开发环境一览
- 显卡驱动安装
- 下载驱动
- 禁用nouveau
- 安装驱动
- 安装CUDA8.0
- 第一个CUDA程序
- 向世界问好
- 最后
前言
在Linux下安装驱动真的不是一件简单的事情, 尤其是显卡驱动, 一失败直接进不去系统都是很可能的. 我在经历了无数折磨之后终于搭起了CUDA编程环境.
关于快速搭建CUDA开发环境, 可以参考Ubuntu18.04LTS快速搭建CUDA环境. 前提是你对版本没要求, 能用就行.
我是很心水老黄的, 但是, 我还是想说"So, Nvidia: FUCK YOU!"(Linux之父原话)(手动滑稽).

2007年6月23日 NVIDIA公司发布了CUDA, 透过这个技术, 用户可利用NVIDIA的GeForce 8以后的GPU和较新的Quadro GPU进行计算. 亦是首次可以利用GPU作为C-编译器的开发环境. 近年来, GPU最成功的一个应用就是深度学习领域, 基于GPU的并行计算已经成为训练深度学习模型的标配.
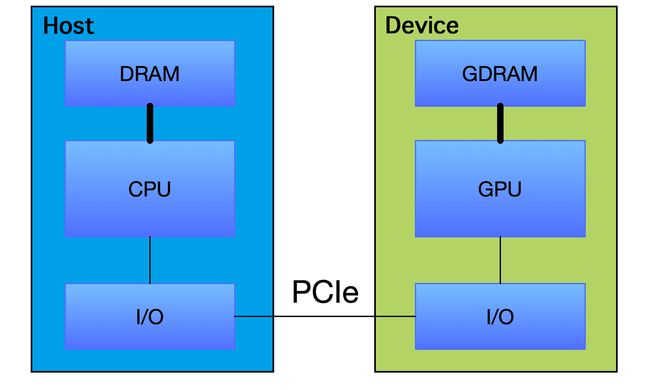
GPU并不是一个独立运行的计算平台, 而需要与CPU协同工作, 可以看成是CPU的协处理器, 因此当我们在说GPU并行计算时, 其实是指的基于CPU + GPU的异构计算架构. 在异构计算架构中, GPU与CPU通过PCIe总线连接在一起来协同工作, CPU所在位置称为为主机端(host), 而GPU所在位置称为设备端(device), 如下图所示:
CUDA技术有下列几个优点:
- 分散读取--代码可以从存储器的任意地址读取
- 统一虚拟内存(CUDA 4)
- 共享存储器--CUDA公开一个快速的共享存储区域(每个处理器48K), 使之在多个进程之间共享.其作为一个用户管理的高速缓存,比使用纹理查找可以得到更大的有效带宽.
- 与GPU之间更快的下载与回读
- 全面支持整型与位操作, 包括整型纹理查找
其实说这些废话你感觉不出来, 简而言之就是, 有矩阵的, 有神经网络的, 并行数很大的, 用它就对了.
开发环境一览
- CPU: Intel core i7 4700MQ
- GPU: NVIDIA GT 750M
- OS: UBUNTU 18.04.1LTS 64位
用指令看下英伟达显卡:
lspci | grep -I nvidia

当你搭建完成环境之后, 可以用代码查看硬件信息, 自己写或者官方的例子, 我的NVIDIA GT 750M信息显示如下图, 当然可以直接到英伟达官网查看显卡信息. 这张信息表目前看来就是些参数, 但是后续的并行算法很多时候是依据这些参数来设计的:
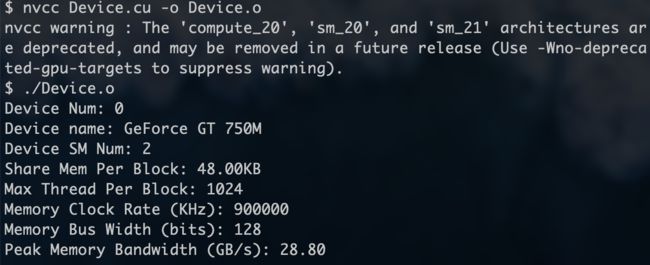
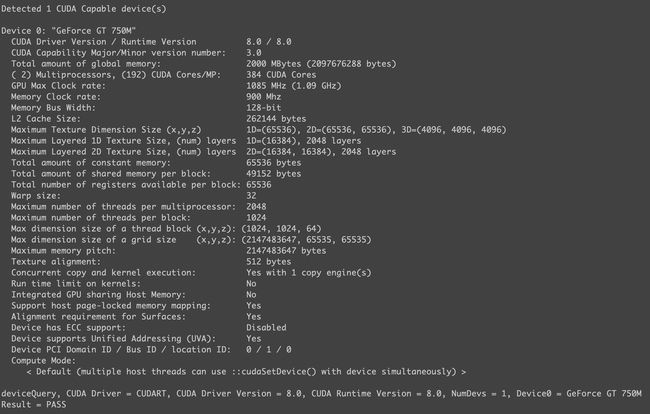
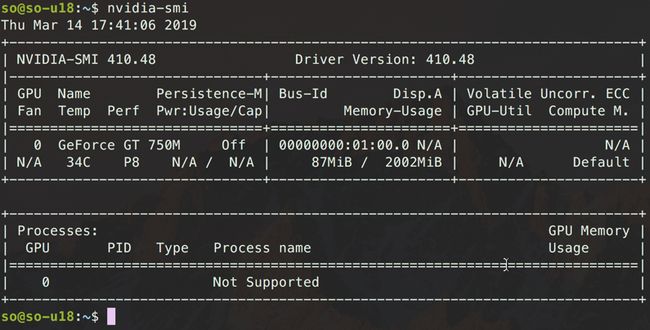
或者你可以使用
nvidia-smi看看显卡信息:
显卡驱动安装
千万不要用UBUNTU附加驱动里提供的显卡驱动!!!
千万不要用UBUNTU附加驱动里提供的显卡驱动!!!
千万不要用UBUNTU附加驱动里提供的显卡驱动!!!
一般来说, 你会遇到一些奇怪的问题, 当然, 锦鲤是不会出问题的(手动滑稽).
这是第一个坑点, 大体有三种展现方式:
- 装完重启进不去系统, 卡住ubuntu加载页面;
- 无限登录;
- 装好了, 进入了系统, 然后输入nvidia-smi指令没有任何反应. 正常情况会弹出一张表, 如下所示:
下载驱动
行了, 来说说我的实操:
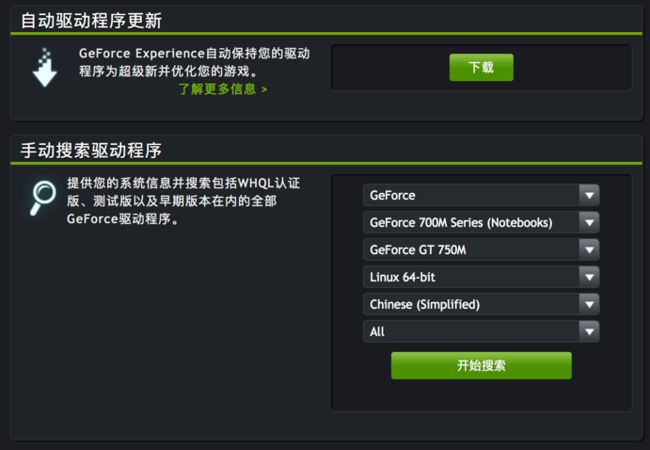
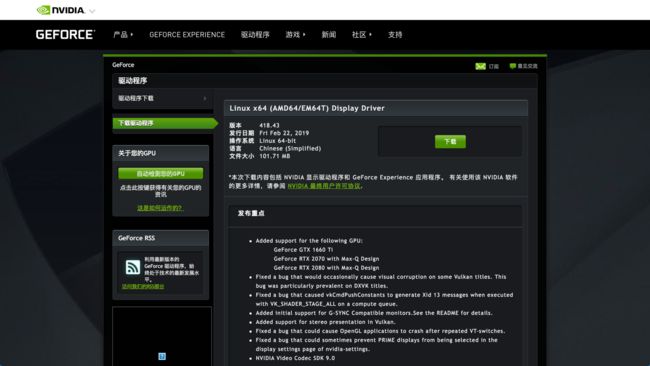
首先到官网下载显卡驱动, 比方说我是GT 750M, 操作系统是64位Linux, 我就找对应的版本进行下载.
删掉以往的驱动. 注意, 就算你啥都没装, 这步也是无害的.
sudo apt-get remove --purge nvidia*
更新并安装一些需要的库, 先装这么多, 之后装CUDA还有一波.
sudo apt-get update
sudo apt-get install dkms build-essential linux-headers-generic
禁用nouveau
打开blacklist.conf, 在最后加入禁用nouveau的设置, 这是一个开源驱动, 如图所示:
sudo vim /etc/modprobe.d/blacklist.conf
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
禁用nouveau内核模块
echo options nouveau modeset=0
sudo update-initramfs -u
重启. 如果运行如下指令没用打印出任何内容, 恭喜你, 禁用nouveau成功了.
lsmod | grep nouveau
安装驱动
来到tty1(快捷键ctrl + alt + f1,如果没反应就f1-f7一个个试, 不同Linux, 按键会略有不同). 运行如下指令关闭图形界面.我在ubuntu18.04.1LTS是ctrl + alt + f3-f6. 然后注意, 以下指令适用于16.04及以前.
sudo service lightdm stop
这不适用于18.04. 18.04可以如下操作:
- 关闭用户图形界面
sudo systemctl set-default multi-user.target
sudo reboot
- 开启用户图形界面
sudo systemctl set-default graphical.target
sudo reboot
安装驱动, 注意有坑, 一定要加-no-opengl-files, 不加这个就算安装成功, 也会出现无限登录问题.但是在最近几次安装环境的时候, 例如系统是18.04, 驱动是418.43, 这个参数变得无效. 所以如果不能开启安装页面, 可以去掉此参数.
sudo chmod u+x NVIDIA-Linux-x86_64-390.87.run
sudo ./NVIDIA-Linux-x86_64-390.87.run –no-opengl-files
如果你已经装了, 但是没有加-no-opengl-files, 按照如下操作可以救一下.或者你安装失败了, 有些库缺少了之类的, 可以用以下命令卸载干净重来.
sudo ./NVIDIA-Linux-x86_64-390.87.run –uninstall
顺带一提, 可能会弹出Unable to find a suitable destination to install 32-bit compatibility libraries on Ubuntu 18.04 Bionic Beaver Linux的bug, 然后你需要下面三条指令:
sudo dpkg --add-architecture i386
sudo apt update
sudo apt install libc6:i386
并且中途的选项都选no比较好, 指不定卡死在安装哪个奇怪的东西上.
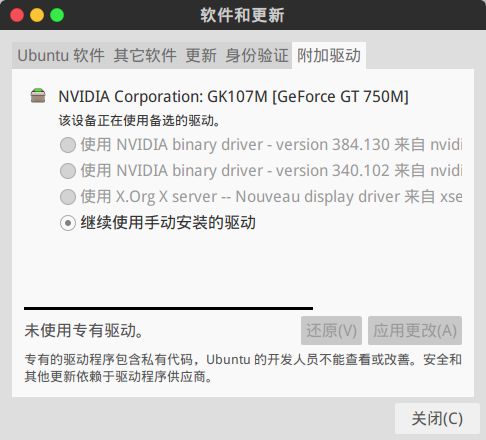
重启. 用nvidia-smi指令试一下, 如果看到类似下图, 恭喜你, 驱动安装成功. 或者看到附加驱动显示继续使用手动安装的驱动.
安装之后在软件和更新当中会显示如下图:
安装CUDA10.0
先来补库.
sudo apt-get install freeglut3-dev libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
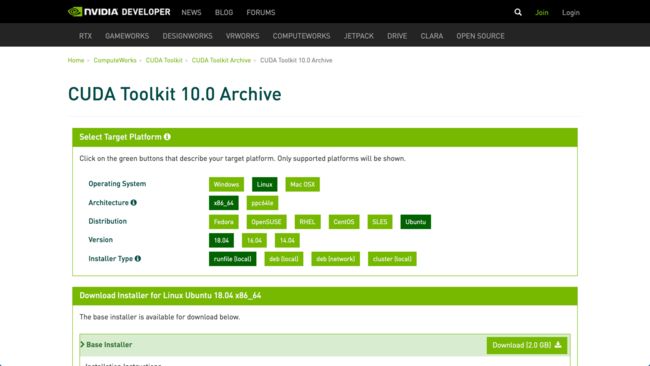
到官网下载要的CUDA版本, 我这里是10.0, 下载runfile(local)版本, 如下图所示:
md5检测一下, 不合格要重新下载. 下图是我的检测结果:
md5sum cuda_10.0.130_410.48_linux.run

再次关闭图形界面
sudo service lightdm stop
这不适用于18.04. 18.04可以如下操作:
- 关闭用户图形界面
sudo systemctl set-default multi-user.target
sudo reboot
- 开启用户图形界面
sudo systemctl set-default graphical.target
sudo reboot
安装时候依旧要加-no-opengl-files参数, 之后一路默认就好.最好不要安装与OpenGL相关的.
sudo sh cuda_10.0.130_410.48_linux.run –no-opengl-files
然后会看到三个installed.
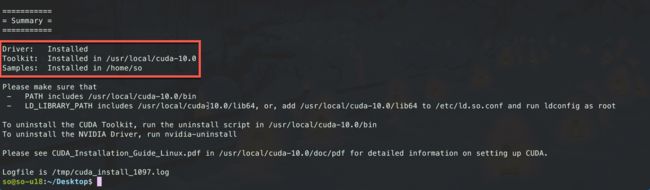
添加环境变量
vim ~/.bashrc
最后写入:
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:$CUDA_HOME/bin
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
保存退出, 并其生效.
source ~/.bashrc
运行一些检测命令, 如果和我显示的类似, 恭喜你, 环境配置完成.
cat /proc/driver/nvidia/version
nvcc -V

可以跑一下英伟达提供的学习案例:
第一个CUDA程序
之前在开发环境部分展示过一个小栗子, 来看看具体代码吧~
vim Device.cu
#include
int main() {
int nDevices;
cudaGetDeviceCount(&nDevices);
for (int i = 0; i < nDevices; i++) {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
printf("Device Num: %d\n", i);
printf("Device name: %s\n", prop.name);
printf("Device SM Num: %d\n", prop.multiProcessorCount);
printf("Share Mem Per Block: %.2fKB\n", prop.sharedMemPerBlock / 1024.0);
printf("Max Thread Per Block: %d\n", prop.maxThreadsPerBlock);
printf("Memory Clock Rate (KHz): %d\n",
prop.memoryClockRate);
printf("Memory Bus Width (bits): %d\n",
prop.memoryBusWidth);
printf("Peak Memory Bandwidth (GB/s): %.2f\n\n",
2.0 * prop.memoryClockRate * (prop.memoryBusWidth / 8) / 1.0e6);
}
return 0;
}
nvcc Device.cu -o Device.o
./Device.o
最后
喜欢记得点赞哦, 有意见或者建议评论区见~