前言
上一篇文章,在解析初始化GraphicBuffer中,遇到一个ion驱动,对图元进行管理。首先看看ion是怎么使用的:
- 1.打开驱动:
mIonFd = open(ION_DEVICE, O_RDONLY);
- 2.ioctl 发送ION_IOC_ALLOC命令
if(ioctl(mIonFd, ION_IOC_ALLOC, &ionAllocData)) {
err = -errno;
ALOGE("ION_IOC_ALLOC failed with error - %s", strerror(errno));
return err;
}
- 3.ioctl发送ION_IOC_MAP命令
ioctl(mIonFd, ION_IOC_MAP, &fd_data)
- 4.mmap 映射一段共享内存
base = mmap(0, ionAllocData.len, PROT_READ|PROT_WRITE,
MAP_SHARED, fd_data.fd, 0);
- 5.ioctl ION_IOC_FREE 释放底层的句柄
ioctl(mIonFd, ION_IOC_FREE, &handle_data);
我们按照这个流程分析ion的源码。
如果对ion使用感兴趣,可以去这篇文章下面看https://blog.csdn.net/hexiaolong2009/article/details/102596744
本文基于Android的Linux内核版本3.1.8
遇到什么问题欢迎来本文讨论https://www.jianshu.com/p/5fe57566691f
正文
什么是ion?如果是音视频,Camera的工程师会对这个驱动比较熟悉。最早的GPU和其他驱动协作申请一块内存进行绘制是使用比较粗暴的共享内存。在Android系统中使用的是匿名内存。最早由三星实现了一个Display和Camera共享内存的问题,曾经在Linux社区掀起过一段时间。之后各路大牛不断的改进之下,就成为了dma_buf驱动。并在 Linux-3.3 主线版本合入主线。现在已经广泛的运用到各大多媒体开发中。
首先介绍dma_buf的2个角色,importer和exporter。importer是dma_buf驱动中的图元消费者,exporter是dma_buf驱动中的图元生产者。
这里借用大佬的图片:
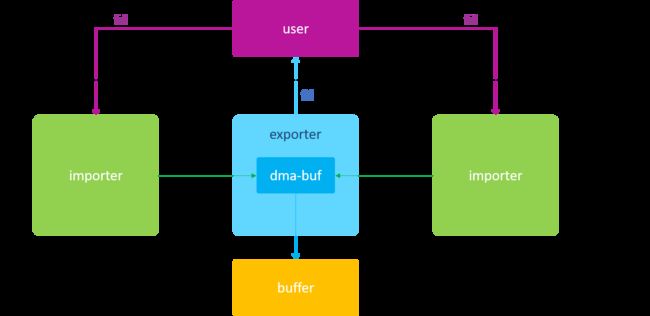
ion是基于dma_buf设计完成的。经过阅读源码,其实不少思路和Android的匿名内存有点相似。阅读本文之前就算不知道dma_buf的设计思想也没关系,我不会仔细到每一行,我会注重其在gralloc服务中的申请流程,看看ion是如何管理共享内存,为什么要抛弃ashmem。
ion初始化
我们先来看看ion的file_operation:
static const struct file_operations ion_fops = {
.owner = THIS_MODULE,
.open = ion_open,
.release = ion_release,
.unlocked_ioctl = ion_ioctl,
.compat_ioctl = compat_ion_ioctl,
};
只有一个open和ioctl函数。但是没有mmap映射。因此mmap映射的时候一定其他对象在工作。
我们关注显卡英伟达的初始化模块。
文件:/drivers/staging/android/ion/tegra/tegra_ion.c
static struct platform_driver ion_driver = {
.probe = tegra_ion_probe,
.remove = tegra_ion_remove,
.driver = { .name = "ion-tegra" }
};
module_platform_driver(ion_driver);
module_platform_driver实际上就是我之前经常提到过的module_init的一个宏,多了一个register注册到对应名字的平台中的步骤。在这里面注册了一个probe方法指针,probe指向的tegra_ion_probe是加载内核模块注册的时候调用。
static struct ion_device *idev;
static int num_heaps;
static struct ion_heap **heaps;
static int tegra_ion_probe(struct platform_device *pdev)
{
struct ion_platform_data *pdata = pdev->dev.platform_data;
int err;
int i;
num_heaps = pdata->nr;
heaps = devm_kzalloc(&pdev->dev,
sizeof(struct ion_heap *) * pdata->nr,
GFP_KERNEL);
idev = ion_device_create(NULL);
if (IS_ERR_OR_NULL(idev))
return PTR_ERR(idev);
/* create the heaps as specified in the board file */
for (i = 0; i < num_heaps; i++) {
struct ion_platform_heap *heap_data = &pdata->heaps[i];
heaps[i] = ion_heap_create(heap_data);
if (IS_ERR_OR_NULL(heaps[i])) {
err = PTR_ERR(heaps[i]);
goto err;
}
ion_device_add_heap(idev, heaps[i]);
}
platform_set_drvdata(pdev, idev);
return 0;
err:
for (i = 0; i < num_heaps; i++) {
if (heaps[i])
ion_heap_destroy(heaps[i]);
}
return err;
}
先来看看对应的结构体:
struct ion_platform_data {
int nr;/*有多少ion_platform_heap*/
struct ion_platform_heap *heaps;/*ion_platform_heap 指针数组*/
};
再来看看对应ion内的堆结构体:
struct ion_platform_heap {
enum ion_heap_type type;/*heap 类型*/
unsigned int id;
const char *name;
ion_phys_addr_t base;/*heap 起始地址*/
size_t size;/*heap 大小*/
ion_phys_addr_t align;/*heap需要对齐*/
void *priv;
};
完成的事情如下几个步骤:
- 1.ion_device_create 初始化注册ion驱动
- 2.ion_heap_create和ion_device_add_heap 初始化ion_platform_data中申请内存的堆,并添加到ion驱动中管理
ion_device_create 初始化注册ion驱动
struct ion_device *ion_device_create(long (*custom_ioctl)
(struct ion_client *client,
unsigned int cmd,
unsigned long arg))
{
struct ion_device *idev;
int ret;
idev = kzalloc(sizeof(struct ion_device), GFP_KERNEL);
..
idev->dev.minor = MISC_DYNAMIC_MINOR;
idev->dev.name = "ion";
idev->dev.fops = &ion_fops;
idev->dev.parent = NULL;
ret = misc_register(&idev->dev);
...
idev->debug_root = debugfs_create_dir("ion", NULL);
if (!idev->debug_root) {
...
goto debugfs_done;
}
...
debugfs_done:
idev->custom_ioctl = custom_ioctl;
idev->buffers = RB_ROOT;
mutex_init(&idev->buffer_lock);
init_rwsem(&idev->lock);
plist_head_init(&idev->heaps);
idev->clients = RB_ROOT;
return idev;
}
我们不关注debug模式。其实整个就是我们分析了很多次的方法。把这个对象注册miscdevice中。等到insmod就会把整个整个内核模块从dev_t的map中关联出来。
我们来看看这个驱动结构体:
struct ion_device {
struct miscdevice dev;/*驱动设备符*/
struct rb_root buffers;/*ion_buffer ion内核缓冲区 红黑树*/
struct mutex buffer_lock;
struct rw_semaphore lock;
struct plist_head heaps;/*ion_buffer ion内核堆链表*/
long (*custom_ioctl)(struct ion_client *client, unsigned int cmd,
unsigned long arg);
struct rb_root clients;/*每一个open进来的对象*/
struct dentry *debug_root;
struct dentry *heaps_debug_root;
struct dentry *clients_debug_root;
};
ion_heap_create 创建ion内存申请堆
文件:/drivers/staging/android/ion/ion_heap.c
struct ion_heap *ion_heap_create(struct ion_platform_heap *heap_data)
{
struct ion_heap *heap = NULL;
switch (heap_data->type) {
case ION_HEAP_TYPE_SYSTEM_CONTIG:
heap = ion_system_contig_heap_create(heap_data);
break;
case ION_HEAP_TYPE_SYSTEM:
heap = ion_system_heap_create(heap_data);
break;
case ION_HEAP_TYPE_CARVEOUT:
heap = ion_carveout_heap_create(heap_data);
break;
case ION_HEAP_TYPE_CHUNK:
heap = ion_chunk_heap_create(heap_data);
break;
case ION_HEAP_TYPE_DMA:
heap = ion_cma_heap_create(heap_data);
break;
default:
return ERR_PTR(-EINVAL);
}
...
heap->name = heap_data->name;
heap->id = heap_data->id;
return heap;
}
这里有四个不同堆会申请出来,我们主要来看看默认的ION_HEAP_TYPE_SYSTEM对应的heap流程。
ion_system_heap_create
static const unsigned int orders[] = {8, 4, 0};
static struct ion_heap_ops system_heap_ops = {
.allocate = ion_system_heap_allocate,
.free = ion_system_heap_free,
.map_dma = ion_system_heap_map_dma,
.unmap_dma = ion_system_heap_unmap_dma,
.map_kernel = ion_heap_map_kernel,
.unmap_kernel = ion_heap_unmap_kernel,
.map_user = ion_heap_map_user,
.shrink = ion_system_heap_shrink,
};
struct ion_heap *ion_system_heap_create(struct ion_platform_heap *unused)
{
struct ion_system_heap *heap;
int i;
heap = kzalloc(sizeof(struct ion_system_heap) +
sizeof(struct ion_page_pool *) * num_orders,
GFP_KERNEL);
if (!heap)
return ERR_PTR(-ENOMEM);
heap->heap.ops = &system_heap_ops;
heap->heap.type = ION_HEAP_TYPE_SYSTEM;
heap->heap.flags = ION_HEAP_FLAG_DEFER_FREE;
for (i = 0; i < num_orders; i++) {
struct ion_page_pool *pool;
gfp_t gfp_flags = low_order_gfp_flags;
if (orders[i] > 4)
gfp_flags = high_order_gfp_flags;
pool = ion_page_pool_create(gfp_flags, orders[i]);
if (!pool)
goto destroy_pools;
heap->pools[i] = pool;
}
heap->heap.debug_show = ion_system_heap_debug_show;
return &heap->heap;
....
}
struct ion_system_heap {
struct ion_heap heap;
struct ion_page_pool *pools[0];
};
其实真正象征ion的内存堆是下面这个结构体
struct ion_heap {
struct plist_node node;
struct ion_device *dev;
enum ion_heap_type type;/*类型*/
struct ion_heap_ops *ops;/*堆操作*/
unsigned long flags;/*此时是ION_HEAP_FLAG_DEFER_FREE*/
unsigned int id;
const char *name;
struct shrinker shrinker;/*回收资源方法*/
struct list_head free_list;/*空闲资源*/
size_t free_list_size;
spinlock_t free_lock;
wait_queue_head_t waitqueue;
struct task_struct *task;
int (*debug_show)(struct ion_heap *heap, struct seq_file *, void *);
};
不管原来的那个heap,会新建3个ion_system_heap,分别order为8,4,0,大于4为大内存。意思就是这个heap中持有一个ion_page_pool 页资源池子,里面只有对应order的2的次幂,内存块。其实就和伙伴系统有点相似。
还会设置flag为ION_HEAP_FLAG_DEFER_FREE,这个标志位后面会用到。
ion_page_pool_create 创建页资源池
文件:/drivers/staging/android/ion/ion_page_pool.c
struct ion_page_pool *ion_page_pool_create(gfp_t gfp_mask, unsigned int order)
{
struct ion_page_pool *pool = kmalloc(sizeof(struct ion_page_pool),
GFP_KERNEL);
if (!pool)
return NULL;
pool->high_count = 0;
pool->low_count = 0;
INIT_LIST_HEAD(&pool->low_items);
INIT_LIST_HEAD(&pool->high_items);
pool->gfp_mask = gfp_mask | __GFP_COMP;
pool->order = order;
mutex_init(&pool->mutex);
plist_node_init(&pool->list, order);
return pool;
}
struct ion_page_pool {
int high_count;
int low_count;
struct list_head high_items;
struct list_head low_items;
struct mutex mutex;
gfp_t gfp_mask;
unsigned int order;
struct plist_node list;
};
在pool中分为2个链表一个是high_items,另一个是low_items。他们之间的区分在此时就是以2为底4的次幂为分界线。
ion_device_add_heap
文件:/drivers/staging/android/ion/ion.c
void ion_device_add_heap(struct ion_device *dev, struct ion_heap *heap)
{
struct dentry *debug_file;
....
if (heap->flags & ION_HEAP_FLAG_DEFER_FREE)
ion_heap_init_deferred_free(heap);
if ((heap->flags & ION_HEAP_FLAG_DEFER_FREE) || heap->ops->shrink)
ion_heap_init_shrinker(heap);
heap->dev = dev;
down_write(&dev->lock);
plist_node_init(&heap->node, -heap->id);
plist_add(&heap->node, &dev->heaps);
...
#ifdef DEBUG_HEAP_SHRINKER
...
#endif
up_write(&dev->lock);
}
因为打开了标志位ION_HEAP_FLAG_DEFER_FREE和heap存在shrink方法。因此会初始化两个回收函数。
- 1.ion_heap_init_deferred_free
- 2.ion_heap_init_shrinker
- 3.ion_heap 添加到ion_device的heap红黑树中。
ion_heap_init_deferred_free 启动销毁heap中free资源的线程
文件:/drivers/staging/android/ion/ion_heap.c
static int ion_heap_deferred_free(void *data)
{
struct ion_heap *heap = data;
while (true) {
struct ion_buffer *buffer;
wait_event_freezable(heap->waitqueue,
ion_heap_freelist_size(heap) > 0);
spin_lock(&heap->free_lock);
if (list_empty(&heap->free_list)) {
spin_unlock(&heap->free_lock);
continue;
}
buffer = list_first_entry(&heap->free_list, struct ion_buffer,
list);
list_del(&buffer->list);
heap->free_list_size -= buffer->size;
spin_unlock(&heap->free_lock);
ion_buffer_destroy(buffer);
}
return 0;
}
int ion_heap_init_deferred_free(struct ion_heap *heap)
{
struct sched_param param = { .sched_priority = 0 };
INIT_LIST_HEAD(&heap->free_list);
heap->free_list_size = 0;
spin_lock_init(&heap->free_lock);
init_waitqueue_head(&heap->waitqueue);
heap->task = kthread_run(ion_heap_deferred_free, heap,
"%s", heap->name);
if (IS_ERR(heap->task)) {
...
return PTR_ERR_OR_ZERO(heap->task);
}
sched_setscheduler(heap->task, SCHED_IDLE, ¶m);
return 0;
}
此时会创建一个内核线程,调用ion_heap_deferred_free内核不断的循环处理。不过由于这个线程设置的是SCHED_IDLE,这是最低等级的时间片轮转抢占。和Handler那个adle一样的处理规则,就是闲时处理。
在这个循环中,不断的循环销毁处理heap的free_list里面已经没有用的ion_buffer缓冲对象。
ion_heap_init_shrinker 释放ion_pool中的page
文件:/drivers/staging/android/ion/ion_system_heap.c
void ion_heap_init_shrinker(struct ion_heap *heap)
{
heap->shrinker.count_objects = ion_heap_shrink_count;
heap->shrinker.scan_objects = ion_heap_shrink_scan;
heap->shrinker.seeks = DEFAULT_SEEKS;
heap->shrinker.batch = 0;
register_shrinker(&heap->shrinker);
}
注册了heap的销毁内存的方法。当系统需要销毁页的时候,就会调用通过register_shrinker注册进来的函数。
static int ion_system_heap_shrink(struct ion_heap *heap, gfp_t gfp_mask,
int nr_to_scan)
{
struct ion_system_heap *sys_heap;
int nr_total = 0;
int i;
sys_heap = container_of(heap, struct ion_system_heap, heap);
for (i = 0; i < num_orders; i++) {
struct ion_page_pool *pool = sys_heap->pools[i];
nr_total += ion_page_pool_shrink(pool, gfp_mask, nr_to_scan);
}
return nr_total;
}
文件:/drivers/staging/android/ion/ion_page_pool.c
int ion_page_pool_shrink(struct ion_page_pool *pool, gfp_t gfp_mask,
int nr_to_scan)
{
int freed;
bool high;
if (current_is_kswapd())
high = true;
else
high = !!(gfp_mask & __GFP_HIGHMEM);
if (nr_to_scan == 0)
return ion_page_pool_total(pool, high);
for (freed = 0; freed < nr_to_scan; freed++) {
struct page *page;
mutex_lock(&pool->mutex);
if (pool->low_count) {
page = ion_page_pool_remove(pool, false);
} else if (high && pool->high_count) {
page = ion_page_pool_remove(pool, true);
} else {
mutex_unlock(&pool->mutex);
break;
}
mutex_unlock(&pool->mutex);
ion_page_pool_free_pages(pool, page);
}
return freed;
}
static struct page *ion_page_pool_remove(struct ion_page_pool *pool, bool high)
{
struct page *page;
if (high) {
page = list_first_entry(&pool->high_items, struct page, lru);
pool->high_count--;
} else {
page = list_first_entry(&pool->low_items, struct page, lru);
pool->low_count--;
}
list_del(&page->lru);
return page;
}
static void ion_page_pool_free_pages(struct ion_page_pool *pool,
struct page *page)
{
ion_page_pool_free_set_cache_policy(pool, page);
__free_pages(page, pool->order);
}
整个流程很简单,其实就是遍历循环需要销毁的页面数量,接着如果是8的次幂就是移除high_items中的page缓存。4和0则销毁low_items中的page缓存。至于为什么是2的次幂其实很简单,为了销毁和申请简单。__free_pages能够整页的销毁。
ion open
文件:/drivers/staging/android/ion/ion.c
static int ion_open(struct inode *inode, struct file *file)
{
struct miscdevice *miscdev = file->private_data;
struct ion_device *dev = container_of(miscdev, struct ion_device, dev);
struct ion_client *client;
char debug_name[64];
pr_debug("%s: %d\n", __func__, __LINE__);
snprintf(debug_name, 64, "%u", task_pid_nr(current->group_leader));
client = ion_client_create(dev, debug_name);
if (IS_ERR(client))
return PTR_ERR(client);
file->private_data = client;
return 0;
}
- 1.ion_client_create 为open对应file创建一个ion_client
- 2.file的私有数据更换为ion_client
ion_client_create 为open对应file创建一个ion_client
struct ion_client *ion_client_create(struct ion_device *dev,
const char *name)
{
struct ion_client *client;
struct task_struct *task;
struct rb_node **p;
struct rb_node *parent = NULL;
struct ion_client *entry;
pid_t pid;
...
get_task_struct(current->group_leader);
task_lock(current->group_leader);
pid = task_pid_nr(current->group_leader);
if (current->group_leader->flags & PF_KTHREAD) {
put_task_struct(current->group_leader);
task = NULL;
} else {
task = current->group_leader;
}
task_unlock(current->group_leader);
client = kzalloc(sizeof(struct ion_client), GFP_KERNEL);
if (!client)
goto err_put_task_struct;
client->dev = dev;
client->handles = RB_ROOT;
idr_init(&client->idr);
mutex_init(&client->lock);
client->task = task;
client->pid = pid;
client->name = kstrdup(name, GFP_KERNEL);
if (!client->name)
goto err_free_client;
down_write(&dev->lock);
client->display_serial = ion_get_client_serial(&dev->clients, name);
client->display_name = kasprintf(
GFP_KERNEL, "%s-%d", name, client->display_serial);
if (!client->display_name) {
up_write(&dev->lock);
goto err_free_client_name;
}
p = &dev->clients.rb_node;
while (*p) {
parent = *p;
entry = rb_entry(parent, struct ion_client, node);
if (client < entry)
p = &(*p)->rb_left;
else if (client > entry)
p = &(*p)->rb_right;
}
rb_link_node(&client->node, parent, p);
rb_insert_color(&client->node, &dev->clients);
...
up_write(&dev->lock);
return client;
...
}
主要就是初始化ion_client各个参数,最后把ion_client插入到ion_device的clients。来看看ion_client结构体:
struct ion_client {
struct rb_node node;/*链接对应ion_device红黑树的node*/
struct ion_device *dev;/*驱动对象*/
struct rb_root handles;/*一个client带着的句柄红黑树*/
struct idr idr;
struct mutex lock;
const char *name;
char *display_name;
int display_serial;
struct task_struct *task;/*线程组的leader,也就是当前的进程*/
pid_t pid;/*进程id*/
struct dentry *debug_root;
};
ioctl 发送ION_IOC_ALLOC命令
static long ion_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
struct ion_client *client = filp->private_data;
struct ion_device *dev = client->dev;
struct ion_handle *cleanup_handle = NULL;
int ret = 0;
unsigned int dir;
union {
struct ion_fd_data fd;
struct ion_allocation_data allocation;
struct ion_handle_data handle;
struct ion_custom_data custom;
} data;
dir = ion_ioctl_dir(cmd);
if (_IOC_SIZE(cmd) > sizeof(data))
return -EINVAL;
if (dir & _IOC_WRITE)
if (copy_from_user(&data, (void __user *)arg, _IOC_SIZE(cmd)))
return -EFAULT;
switch (cmd) {
case ION_IOC_ALLOC:
{
struct ion_handle *handle;
handle = ion_alloc(client, data.allocation.len,
data.allocation.align,
data.allocation.heap_id_mask,
data.allocation.flags);
if (IS_ERR(handle))
return PTR_ERR(handle);
data.allocation.handle = handle->id;
cleanup_handle = handle;
break;
}
case ION_IOC_FREE:
{
...
}
case ION_IOC_SHARE:
case ION_IOC_MAP:
{
...
}
...
default:
return -ENOTTY;
}
if (dir & _IOC_READ) {
if (copy_to_user((void __user *)arg, &data, _IOC_SIZE(cmd))) {
if (cleanup_handle)
ion_free(client, cleanup_handle);
return -EFAULT;
}
}
return ret;
}
核心还是调用ion_alloc申请一个ion缓冲区的句柄。最后把数据拷贝会用户空间。
ion_alloc 创建句柄和缓冲区
struct ion_handle *ion_alloc(struct ion_client *client, size_t len,
size_t align, unsigned int heap_id_mask,
unsigned int flags)
{
struct ion_handle *handle;
struct ion_device *dev = client->dev;
struct ion_buffer *buffer = NULL;
struct ion_heap *heap;
int ret;
len = PAGE_ALIGN(len);
if (!len)
return ERR_PTR(-EINVAL);
down_read(&dev->lock);
plist_for_each_entry(heap, &dev->heaps, node) {
/* if the caller didn't specify this heap id */
if (!((1 << heap->id) & heap_id_mask))
continue;
buffer = ion_buffer_create(heap, dev, len, align, flags);
if (!IS_ERR(buffer))
break;
}
up_read(&dev->lock);
...
handle = ion_handle_create(client, buffer);
ion_buffer_put(buffer);
if (IS_ERR(handle))
return handle;
mutex_lock(&client->lock);
ret = ion_handle_add(client, handle);
mutex_unlock(&client->lock);
if (ret) {
ion_handle_put(handle);
handle = ERR_PTR(ret);
}
return handle;
}
- 1.遍历ion_device的中heaps,ion_buffer_create创建ion_buffer
- 2.ion_handle_create 创建句柄ion_handle
- 3.ion_buffer_put 设置buffer销毁时候的函数
- 4.ion_handle_add 把ion_handle插入到ion_client的handles红黑树。
ion_buffer_create 创建ion_buffer
static struct ion_buffer *ion_buffer_create(struct ion_heap *heap,
struct ion_device *dev,
unsigned long len,
unsigned long align,
unsigned long flags)
{
struct ion_buffer *buffer;
struct sg_table *table;
struct scatterlist *sg;
int i, ret;
buffer = kzalloc(sizeof(struct ion_buffer), GFP_KERNEL);
if (!buffer)
return ERR_PTR(-ENOMEM);
buffer->heap = heap;
buffer->flags = flags;
kref_init(&buffer->ref);
ret = heap->ops->allocate(heap, buffer, len, align, flags);
...
buffer->dev = dev;
buffer->size = len;
table = heap->ops->map_dma(heap, buffer);
...
buffer->sg_table = table;
if (ion_buffer_fault_user_mappings(buffer)) {
int num_pages = PAGE_ALIGN(buffer->size) / PAGE_SIZE;
struct scatterlist *sg;
int i, j, k = 0;
buffer->pages = vmalloc(sizeof(struct page *) * num_pages);
if (!buffer->pages) {
ret = -ENOMEM;
goto err1;
}
for_each_sg(table->sgl, sg, table->nents, i) {
struct page *page = sg_page(sg);
for (j = 0; j < sg->length / PAGE_SIZE; j++)
buffer->pages[k++] = page++;
}
if (ret)
goto err;
}
buffer->dev = dev;
buffer->size = len;
INIT_LIST_HEAD(&buffer->vmas);
mutex_init(&buffer->lock);
/* this will set up dma addresses for the sglist -- it is not
technically correct as per the dma api -- a specific
device isn't really taking ownership here. However, in practice on
our systems the only dma_address space is physical addresses.
Additionally, we can't afford the overhead of invalidating every
allocation via dma_map_sg. The implicit contract here is that
memory coming from the heaps is ready for dma, ie if it has a
cached mapping that mapping has been invalidated */
for_each_sg(buffer->sg_table->sgl, sg, buffer->sg_table->nents, i)
sg_dma_address(sg) = sg_phys(sg);
mutex_lock(&dev->buffer_lock);
ion_buffer_add(dev, buffer);
mutex_unlock(&dev->buffer_lock);
return buffer;
...
}
- 1.调用ion_heap的allocate
- 2.调用ion_heap的map_dma
- 3.ion_buffer_fault_user_mappings判断当前的buffer是否设置了GRALLOC_USAGE_SW_READ_RARELY,对应顶层就是USAGE_SW_READ_RARELY。也就是读写很少的图元GraphicBuffer。只有打开这个才会为buffer设置vmalloc在动态映射区映射内存(这个高端内存区域的物理内存不连续,虚拟内存是连续),这种很少见,一般是不变的浮层。
- 4.for_each_sg 把table中所有的地址从物理地址直接转化为dma地址。因为高端内存的地址的确可以一一简单的计算算出物理地址。不过这样做很少见。
- 4.ion_buffer_add 把ion_buffer插入ion_device的buffers红黑树。
ion_heap的allocate ion_system_heap_allocate
static int ion_system_heap_allocate(struct ion_heap *heap,
struct ion_buffer *buffer,
unsigned long size, unsigned long align,
unsigned long flags)
{
struct ion_system_heap *sys_heap = container_of(heap,
struct ion_system_heap,
heap);
struct sg_table *table;
struct scatterlist *sg;
struct list_head pages;
struct page *page, *tmp_page;
int i = 0;
unsigned long size_remaining = PAGE_ALIGN(size);
unsigned int max_order = orders[0];
if (align > PAGE_SIZE)
return -EINVAL;
if (size / PAGE_SIZE > totalram_pages / 2)
return -ENOMEM;
INIT_LIST_HEAD(&pages);
while (size_remaining > 0) {
page = alloc_largest_available(sys_heap, buffer, size_remaining,
max_order);
if (!page)
goto free_pages;
list_add_tail(&page->lru, &pages);
size_remaining -= PAGE_SIZE << compound_order(page);
max_order = compound_order(page);
i++;
}
table = kmalloc(sizeof(struct sg_table), GFP_KERNEL);
if (sg_alloc_table(table, i, GFP_KERNEL))
goto free_table;
sg = table->sgl;
list_for_each_entry_safe(page, tmp_page, &pages, lru) {
sg_set_page(sg, page, PAGE_SIZE << compound_order(page), 0);
sg = sg_next(sg);
list_del(&page->lru);
}
buffer->priv_virt = table;
return 0;
...
}
- 把页数进行4kb对齐
- 接着调用alloc_largest_available找到最合适的大小资源池里申请去。
- 初始化ion_buffer中sg_table,设置物理页到sg_table中每一页对象。
- ion_buffer的priv_virt设置为sg_table
alloc_largest_available
static inline unsigned int order_to_size(int order)
{
return PAGE_SIZE << order;
}
static struct page *alloc_largest_available(struct ion_system_heap *heap,
struct ion_buffer *buffer,
unsigned long size,
unsigned int max_order)
{
struct page *page;
int i;
for (i = 0; i < num_orders; i++) {
if (size < order_to_size(orders[i]))
continue;
if (max_order < orders[i])
continue;
page = alloc_buffer_page(heap, buffer, orders[i]);
if (!page)
continue;
return page;
}
return NULL;
}
这个实际上就是找到最小能承载的大小,去申请内存。如果8kb申请内存,就会拆分积分在0-4kb,4kb-16kb,16kb-128kb区间找。刚好dma也是在128kb之内才能申请。超过这个数字就禁止申请。8kb就会拆成2个4kb保存在第一个pool中。
最后所有的申请的page都添加到pages集合中。
alloc_buffer_page
bool ion_buffer_cached(struct ion_buffer *buffer)
{
return !!(buffer->flags & ION_FLAG_CACHED);
}
static gfp_t high_order_gfp_flags = (GFP_HIGHUSER | __GFP_ZERO | __GFP_NOWARN |
__GFP_NORETRY) & ~__GFP_WAIT;
static gfp_t low_order_gfp_flags = (GFP_HIGHUSER | __GFP_ZERO | __GFP_NOWARN);
static struct page *alloc_buffer_page(struct ion_system_heap *heap,
struct ion_buffer *buffer,
unsigned long order)
{
bool cached = ion_buffer_cached(buffer);
struct ion_page_pool *pool = heap->pools[order_to_index(order)];
struct page *page;
if (!cached) {
page = ion_page_pool_alloc(pool);
} else {
gfp_t gfp_flags = low_order_gfp_flags;
if (order > 4)
gfp_flags = high_order_gfp_flags;
page = alloc_pages(gfp_flags | __GFP_COMP, order);
if (!page)
return NULL;
ion_pages_sync_for_device(NULL, page, PAGE_SIZE << order,
DMA_BIDIRECTIONAL);
}
return page;
}
- 1.不许需要缓存则使用ion_page_pool_alloc申请
- 2.需要dma缓存,先调用alloc_pages获取page,接着ion_pages_sync_for_device通过dma缓冲。
ion_page_pool_alloc
文件:/drivers/staging/android/ion/ion_page_pool.c
struct page *ion_page_pool_alloc(struct ion_page_pool *pool)
{
struct page *page = NULL;
BUG_ON(!pool);
mutex_lock(&pool->mutex);
if (pool->high_count)
page = ion_page_pool_remove(pool, true);
else if (pool->low_count)
page = ion_page_pool_remove(pool, false);
mutex_unlock(&pool->mutex);
if (!page)
page = ion_page_pool_alloc_pages(pool);
return page;
}
能看到此时会从 ion_page_pool冲取出对应大小区域的空闲页返回上层,如果最早的时候没有则会调用ion_page_pool_alloc_pages申请一个新的page。由于引用最终来自ion_page_pool中,因此之后申请之后还是在ion_page_pool中。
static void *ion_page_pool_alloc_pages(struct ion_page_pool *pool)
{
struct page *page = alloc_pages(pool->gfp_mask, pool->order);
if (!page)
return NULL;
ion_page_pool_alloc_set_cache_policy(pool, page);
ion_pages_sync_for_device(NULL, page, PAGE_SIZE << pool->order,
DMA_BIDIRECTIONAL);
return page;
}
- ion_page_pool_alloc_set_cache_policy 检测内存是否泄露
- ion_pages_sync_for_device 每一次申请都需要同步dma的数据。
这里的处理就是为了避免DMA直接内存造成的缓存差异(一般的申请,默认会带一个DMA标志位)。换句话说,是否打开cache其实就是,关闭了则使用pool的cache,打开了则不使用pool缓存,只依赖DMA的缓存。
我们可以看另一个dma的heap,它是怎么做到dma内存的一致性.
文件:drivers/staging/android/ion/ion_cma_heap.c
static int ion_cma_allocate(struct ion_heap *heap, struct ion_buffer *buffer,
unsigned long len, unsigned long align,
unsigned long flags)
{
struct ion_cma_heap *cma_heap = to_cma_heap(heap);
struct device *dev = cma_heap->dev;
struct ion_cma_buffer_info *info;
dev_dbg(dev, "Request buffer allocation len %ld\n", len);
if (buffer->flags & ION_FLAG_CACHED)
return -EINVAL;
if (align > PAGE_SIZE)
return -EINVAL;
info = kzalloc(sizeof(struct ion_cma_buffer_info), GFP_KERNEL);
if (!info)
return ION_CMA_ALLOCATE_FAILED;
info->cpu_addr = dma_alloc_coherent(dev, len, &(info->handle),
GFP_HIGHUSER | __GFP_ZERO);
if (!info->cpu_addr) {
dev_err(dev, "Fail to allocate buffer\n");
goto err;
}
info->table = kmalloc(sizeof(struct sg_table), GFP_KERNEL);
if (!info->table)
goto free_mem;
if (ion_cma_get_sgtable
(dev, info->table, info->cpu_addr, info->handle, len))
goto free_table;
/* keep this for memory release */
buffer->priv_virt = info;
dev_dbg(dev, "Allocate buffer %p\n", buffer);
return 0;
...
}
能看到它为了能办到dma缓存的一致性,使用了dma_alloc_coherent创建了一个所有强制同步的地址,也就是没有DMA缓存的地址。
sg_table 和 scatterlist初始化
这里出现了几个新的结构体,sg_table和scatterlist
struct sg_table {
struct scatterlist *sgl; /* the list */
unsigned int nents; /* number of mapped entries */
unsigned int orig_nents; /* original size of list */
};
struct scatterlist {
unsigned long page_link;
unsigned int offset;
unsigned int length;
dma_addr_t dma_address;
#ifdef CONFIG_NEED_SG_DMA_LENGTH
unsigned int dma_length;
#endif
};
table = kmalloc(sizeof(struct sg_table), GFP_KERNEL);
if (!table)
goto free_pages;
if (sg_alloc_table(table, i, GFP_KERNEL))
goto free_table;
sg = table->sgl;
list_for_each_entry_safe(page, tmp_page, &pages, lru) {
sg_set_page(sg, page, PAGE_SIZE << compound_order(page), 0);
sg = sg_next(sg);
list_del(&page->lru);
}
- 1.sg_alloc_table初始化sg_table
- 2.遍历pages,添加到scatterlist。
文件:/lib/scatterlist.c
#define SG_MAX_SINGLE_ALLOC (PAGE_SIZE / sizeof(struct scatterlist))
int __sg_alloc_table(struct sg_table *table, unsigned int nents,
unsigned int max_ents, struct scatterlist *first_chunk,
gfp_t gfp_mask, sg_alloc_fn *alloc_fn)
{
struct scatterlist *sg, *prv;
unsigned int left;
memset(table, 0, sizeof(*table));
if (nents == 0)
return -EINVAL;
#ifndef CONFIG_ARCH_HAS_SG_CHAIN
if (WARN_ON_ONCE(nents > max_ents))
return -EINVAL;
#endif
left = nents;
prv = NULL;
do {
unsigned int sg_size, alloc_size = left;
if (alloc_size > max_ents) {
alloc_size = max_ents;
sg_size = alloc_size - 1;
} else
sg_size = alloc_size;
left -= sg_size;
if (first_chunk) {
sg = first_chunk;
first_chunk = NULL;
} else {
sg = alloc_fn(alloc_size, gfp_mask);
}
if (unlikely(!sg)) {
/*
* Adjust entry count to reflect that the last
* entry of the previous table won't be used for
* linkage. Without this, sg_kfree() may get
* confused.
*/
if (prv)
table->nents = ++table->orig_nents;
return -ENOMEM;
}
sg_init_table(sg, alloc_size);
table->nents = table->orig_nents += sg_size;
/*
* If this is the first mapping, assign the sg table header.
* If this is not the first mapping, chain previous part.
*/
if (prv)
sg_chain(prv, max_ents, sg);
else
table->sgl = sg;
/*
* If no more entries after this one, mark the end
*/
if (!left)
sg_mark_end(&sg[sg_size - 1]);
prv = sg;
} while (left);
return 0;
}
static struct scatterlist *sg_kmalloc(unsigned int nents, gfp_t gfp_mask)
{
if (nents == SG_MAX_SINGLE_ALLOC) {
void *ptr = (void *) __get_free_page(gfp_mask);
kmemleak_alloc(ptr, PAGE_SIZE, 1, gfp_mask);
return ptr;
} else
return kmalloc(nents * sizeof(struct scatterlist), gfp_mask);
}
int sg_alloc_table(struct sg_table *table, unsigned int nents, gfp_t gfp_mask)
{
int ret;
ret = __sg_alloc_table(table, nents, SG_MAX_SINGLE_ALLOC,
NULL, gfp_mask, sg_kmalloc);
if (unlikely(ret))
__sg_free_table(table, SG_MAX_SINGLE_ALLOC, false, sg_kfree);
return ret;
}
这里面实际上做的事情就是一件:初始化sg_table. 用公式来说: pages.size() < PAGE_SIZE/sizeof(scatterlist) = pages.size() * sizeof(scatterlist) < PAGE_SIZE 换句话说,每一次生成scatterlist的链表就会直接尽可能占满一页,让内存更好管理。 返回了sg_table。 初始化ion_handle,并且记录对应的ion_client是当前打开文件的进程,并且设置ion_buffer到handle中。使得句柄能够和buffer关联起来。 每当ion_buffer需要销毁,如果heap打开了ION_HEAP_FLAG_DEFER_FREE标志,将会把对象放到ion_heap中free_list链表。没打开则直接调用heap的销毁函数。 free_buffer_page将会把sg_table中所有scatterlist持有的list全部移动到pool的highItem和lowItem中,如果添加失败则会直接调用__free_pages释放page。最后释放sg_table内存。 首先释放ion_client中保存的handle,接着调用ion_buffer_remove_from_handle,减少buffer持有当前handle数量,最后释放。 整个ion的初始化到这一步就完成,从device驱动结构体到缓存的核心ion_handle初始化。 1.ion_device将会持有一个clients的红黑树,对所有的通过open进来的client,为file设置私有数据我为client。一个buffers红黑树,用于全局控制ion_buffer。一个ion_heap红黑树,用于管理所有类型ion_heap。 2.ion_heap 持有一个ion_page_pool,在这个资源池子里面控制不同规格的内存块。当heap需要申请的内存时候,将会从ion_page_pool找到对应index下的内存页page划分给heap进行ion_buffer的申请。 3.ion会启动一个最低抢占权限的idle的内核线程,不断的循环ion_heap的free_list中的buffer进行销毁。同时注册shrink函数,进行压缩ion_page_pool中的page。 4.ion_handle会持有一个ion_buffer返回到上层。同时ion_buffer也会记录持有多少ion_handle。 5.当引用计数为0的时候,ion_buffer将会把数据销毁或者挡在ion_heap的free_list中。当等到ion_buffer执行销毁行为的时候,将会把当前ion _buffer放入到ion_heap中的ion_pages_pool的high_item和low_item的page链表。并且把数据清空。等到下次需要的时候就优先从pool总获取page。 文件:/drivers/staging/android/ion/ion.c 我们直接看ioctl的截选: 唯一需要注意的是ion_share_dma_buf_fd。 执行分两部分: 在这个过程中核心只有一个方法dma_buf_export,这个方法就是ion身为importer就是向身为exporter的dma_buf申请一段dma共享内存。同时为这一段内存设置一个特殊的操作结构体: dma_buf_ops中所有的操作都是关于mmap的映射操作。因此我们能推测出,实际上我们之后进行mmap内存应该就是操作这一段内存。 dma_buf_export实际上是一个dma_buf_export_named的宏。 文件:/drivers/dma-buf/dma-buf.c 设计上其实和ashmem进行内存和file关联的做法几乎一样。 这里出现了dma_buf全新的结构体,我们稍微看看: 很简单,其实就是为dmabuf->file从当前进程中分配一个可用的fd句柄。最后上传到handle的fd中 我们熟悉了ion驱动整个申请内存的原理,我们回过头来整个申请图元的步骤: 之前提到的ION_SECURE标志位,就在createBufferLayer方法中。 这个flag是SurfaceComposerClient传入的。此时是0,也就是说没有打开ION_SECURE。将会走mmap的if里面,其中fd_data.fd其实就是dma_buf关联file对应的fd信息。 从上面的信息可以指知道,此时调用file文件的mmap其实就调用dma_buf_mmap_internal。 此时调用了dmabuf 缓冲区的mmap,此时dmabuf的mmap操作符就是指ion_mmap 文件:drivers/staging/android/ion/ion.c 我们先不考察直接依赖DMA,我们看看heap中的map_user ion_heap_map_user。 文件:/drivers/staging/android/ion/ion_heap.c 这里的核心就是把scatterlist存储的地址还原为page,获取这段虚拟地址vma的偏移量,计算出需要获取多少page。然后从sg_table中分配scatterlist中的page给这段虚拟内存。 这样就让上层内存和底层管理的page关联到一起 文件:/drivers/staging/android/ion/ion.c 通过client找到handle之后调用ion_free,使用ion_handle_put减少ion_handle的引用计数。 等到计数归0将会调用上面说过的handle回收机制。 先用一幅图来总结整个结构和流程: 先来看初始化: 1.ion_device将会持有一个clients的红黑树,对所有的通过open进来的client,为file设置私有数据我为client。一个buffers红黑树,用于全局控制ion_buffer。一个ion_heap红黑树,用于管理所有类型ion_heap。 2.ion_heap 持有一个ion_page_pool,在这个资源池子里面控制不同规格的内存块。当heap需要申请的内存时候,将会从ion_page_pool找到对应index下的内存页page划分给heap进行ion_buffer的申请。 3.ion会启动一个最低抢占权限的idle的内核线程,不断的循环ion_heap的free_list中的buffer进行销毁。同时注册shrink函数,进行压缩ion_page_pool中的page。 4.ion_handle会持有一个ion_buffer返回到上层。同时ion_buffer也会记录持有多少ion_handle。 5.当引用计数为0的时候,ion_buffer将会把数据销毁或者挡在ion_heap的free_list中。当等到ion_buffer执行销毁行为的时候,将会把当前ion _buffer放入到ion_heap中的ion_pages_pool的high_item和low_item的page链表。并且把数据清空。等到下次需要的时候就优先从pool总获取page。 接着再来看ioctl几个命令: 最后是mmap: 在使用上,我们需要抓住一个要点,fd的转化就能彻底明白了: 之后通过跨进程通信,无论是SF还是App应用进程,只要持有native_handle_t的句柄就能找到importBuffer保存在GrallocImportedInstancePool的句柄,其中的fd就能找到GraphicBuffer中的共享内存。 注意这里不需要Binder的fd的转化,是因为整个GraphicBufferAllocator的hal层和GraphicBufferMapper的hal层都在自己的进程。实际上每次沟通Hal层也是一个类似Binder一样的跨进程操作。所以fd得到申请是收到SF和Hal进程的fd_table的限制的。因此才把真正实例化GraphicBuffer放在SF中同时限制了一个Layer最大只能有64个GraphicBuffer,不允许别人乱实例化。 最后我们在根据ion的功能重新看看GraphicBuffer的几个操作: 只有经过这几个步骤,我们才能正常使用的GraphicBuffer。 那么ion和ashmem比较有什么区别。ashmem在设计层面上和ion十分相似。也是先通过ashmem访问获取对应匿名内存文件的fd。最后所有的访问都是在这段内存文件上处理。 但是有一点是ashmem怎么也无法比的,那就是ion很好的处理了不同内核模块,进程之间共享内存的问题。 在ion中有一个很低优先级的内核线程在不断的回收free_list中的ion_buffer。可以比做gc线程一样。不过没有gc设计这么复杂。同时每一次申请都会经过heap的pool尝试请求已经回收的page。这样享元设计很值得学习。在底层同时会不断计算ion_buffer的引用计数。当归0将会把ion_buffer移动到free_list中。 这也是为什么,我们在使用后记住要清除内存中的数据。因为不一定及时清除。 要知道一个屏幕的像素可是十分大的,有了这些内存回收的设计,为系统系统腾出更多的内存。这就是为什么要选择ion。
sg_table中有一个核心的对象scatterlist链表。如果pages申请的对象数量
ion_heap map_dma
static struct sg_table *ion_system_heap_map_dma(struct ion_heap *heap,
struct ion_buffer *buffer)
{
return buffer->priv_virt;
}
ion_handle_create 创建ion_handle句柄
static struct ion_handle *ion_handle_create(struct ion_client *client,
struct ion_buffer *buffer)
{
struct ion_handle *handle;
handle = kzalloc(sizeof(struct ion_handle), GFP_KERNEL);
if (!handle)
return ERR_PTR(-ENOMEM);
kref_init(&handle->ref);
RB_CLEAR_NODE(&handle->node);
handle->client = client;
ion_buffer_get(buffer);/*增加ion_buffer引用计数*/
ion_buffer_add_to_handle(buffer);
handle->buffer = buffer;
return handle;
}
static void ion_buffer_add_to_handle(struct ion_buffer *buffer)
{
mutex_lock(&buffer->lock);
buffer->handle_count++;
mutex_unlock(&buffer->lock);
}
struct ion_handle {
struct kref ref;/*销毁引用*/
struct ion_client *client;/*对应的客户端*/
struct ion_buffer *buffer;/*ion缓冲区*/
struct rb_node node;/*client 中handles红黑树的节点*/
unsigned int kmap_cnt;
int id;
};
ion_buffer_put 设置ion_buffer销毁函数
static int ion_buffer_put(struct ion_buffer *buffer)
{
return kref_put(&buffer->ref, _ion_buffer_destroy);
}
static void _ion_buffer_destroy(struct kref *kref)
{
struct ion_buffer *buffer = container_of(kref, struct ion_buffer, ref);
struct ion_heap *heap = buffer->heap;
struct ion_device *dev = buffer->dev;
mutex_lock(&dev->buffer_lock);
rb_erase(&buffer->node, &dev->buffers);
mutex_unlock(&dev->buffer_lock);
if (heap->flags & ION_HEAP_FLAG_DEFER_FREE)
ion_heap_freelist_add(heap, buffer);
else
ion_buffer_destroy(buffer);
}
void ion_buffer_destroy(struct ion_buffer *buffer)
{
if (WARN_ON(buffer->kmap_cnt > 0))
buffer->heap->ops->unmap_kernel(buffer->heap, buffer);
buffer->heap->ops->unmap_dma(buffer->heap, buffer);
buffer->heap->ops->free(buffer);
if (buffer->pages)
vfree(buffer->pages);
kfree(buffer);
}
static void ion_system_heap_free(struct ion_buffer *buffer)
{
struct ion_system_heap *sys_heap = container_of(buffer->heap,
struct ion_system_heap,
heap);
struct sg_table *table = buffer->sg_table;
bool cached = ion_buffer_cached(buffer);
struct scatterlist *sg;
int i;
if (!cached && !(buffer->private_flags & ION_PRIV_FLAG_SHRINKER_FREE))
ion_heap_buffer_zero(buffer);
for_each_sg(table->sgl, sg, table->nents, i)
free_buffer_page(sys_heap, buffer, sg_page(sg));
sg_free_table(table);
kfree(table);
}
static void free_buffer_page(struct ion_system_heap *heap,
struct ion_buffer *buffer, struct page *page)
{
unsigned int order = compound_order(page);
bool cached = ion_buffer_cached(buffer);
if (!cached && !(buffer->private_flags & ION_PRIV_FLAG_SHRINKER_FREE)) {
struct ion_page_pool *pool = heap->pools[order_to_index(order)];
if (buffer->private_flags & ION_PRIV_FLAG_SHRINKER_FREE)
ion_page_pool_free_immediate(pool, page);
else
ion_page_pool_free(pool, page);
} else {
__free_pages(page, order);
}
}
ion_handle_put 设置句柄销毁函数
static int ion_handle_put(struct ion_handle *handle)
{
struct ion_client *client = handle->client;
int ret;
mutex_lock(&client->lock);
ret = kref_put(&handle->ref, ion_handle_destroy);
mutex_unlock(&client->lock);
return ret;
}
static void ion_handle_destroy(struct kref *kref)
{
struct ion_handle *handle = container_of(kref, struct ion_handle, ref);
struct ion_client *client = handle->client;
struct ion_buffer *buffer = handle->buffer;
mutex_lock(&buffer->lock);
while (handle->kmap_cnt)
ion_handle_kmap_put(handle);
mutex_unlock(&buffer->lock);
idr_remove(&client->idr, handle->id);
if (!RB_EMPTY_NODE(&handle->node))
rb_erase(&handle->node, &client->handles);
ion_buffer_remove_from_handle(buffer);
ion_buffer_put(buffer);
kfree(handle);
}
小结
ioctl发送ION_IOC_MAP命令
case ION_IOC_SHARE:
case ION_IOC_MAP:
{
struct ion_handle *handle;
handle = ion_handle_get_by_id(client, data.handle.handle);
if (IS_ERR(handle))
return PTR_ERR(handle);
data.fd.fd = ion_share_dma_buf_fd(client, handle);
ion_handle_put(handle);
if (data.fd.fd < 0)
ret = data.fd.fd;
break;
}
ion_share_dma_buf_fd 生成dma共享缓存
int ion_share_dma_buf_fd(struct ion_client *client, struct ion_handle *handle)
{
struct dma_buf *dmabuf;
int fd;
dmabuf = ion_share_dma_buf(client, handle);
if (IS_ERR(dmabuf))
return PTR_ERR(dmabuf);
fd = dma_buf_fd(dmabuf, O_CLOEXEC);
if (fd < 0)
dma_buf_put(dmabuf);
return fd;
}
ion_share_dma_buf 生成dma_buf
struct dma_buf *ion_share_dma_buf(struct ion_client *client,
struct ion_handle *handle)
{
struct ion_buffer *buffer;
struct dma_buf *dmabuf;
bool valid_handle;
mutex_lock(&client->lock);
valid_handle = ion_handle_validate(client, handle);
...
buffer = handle->buffer;
ion_buffer_get(buffer);
mutex_unlock(&client->lock);
dmabuf = dma_buf_export(buffer, &dma_buf_ops, buffer->size, O_RDWR,
NULL);
if (IS_ERR(dmabuf)) {
ion_buffer_put(buffer);
return dmabuf;
}
return dmabuf;
}
static struct dma_buf_ops dma_buf_ops = {
.map_dma_buf = ion_map_dma_buf,
.unmap_dma_buf = ion_unmap_dma_buf,
.mmap = ion_mmap,
.release = ion_dma_buf_release,
.begin_cpu_access = ion_dma_buf_begin_cpu_access,
.end_cpu_access = ion_dma_buf_end_cpu_access,
.kmap_atomic = ion_dma_buf_kmap,
.kunmap_atomic = ion_dma_buf_kunmap,
.kmap = ion_dma_buf_kmap,
.kunmap = ion_dma_buf_kunmap,
};
dma_buf_export exporter生产dma_buf
struct dma_buf *dma_buf_export_named(void *priv, const struct dma_buf_ops *ops,
size_t size, int flags, const char *exp_name,
struct reservation_object *resv)
{
struct dma_buf *dmabuf;
struct file *file;
size_t alloc_size = sizeof(struct dma_buf);
if (!resv)
alloc_size += sizeof(struct reservation_object);
else
/* prevent &dma_buf[1] == dma_buf->resv */
alloc_size += 1;
...
dmabuf = kzalloc(alloc_size, GFP_KERNEL);
...
dmabuf->priv = priv;
dmabuf->ops = ops;
dmabuf->size = size;
dmabuf->exp_name = exp_name;
init_waitqueue_head(&dmabuf->poll);
dmabuf->cb_excl.poll = dmabuf->cb_shared.poll = &dmabuf->poll;
dmabuf->cb_excl.active = dmabuf->cb_shared.active = 0;
if (!resv) {
resv = (struct reservation_object *)&dmabuf[1];
reservation_object_init(resv);
}
dmabuf->resv = resv;
file = anon_inode_getfile("dmabuf", &dma_buf_fops, dmabuf, flags);
if (IS_ERR(file)) {
kfree(dmabuf);
return ERR_CAST(file);
}
file->f_mode |= FMODE_LSEEK;
dmabuf->file = file;
mutex_init(&dmabuf->lock);
INIT_LIST_HEAD(&dmabuf->attachments);
mutex_lock(&db_list.lock);
list_add(&dmabuf->list_node, &db_list.head);
mutex_unlock(&db_list.lock);
return dmabuf;
}
核心的事情只有两件:
static const struct file_operations dma_buf_fops = {
.release = dma_buf_release,
.mmap = dma_buf_mmap_internal,
.llseek = dma_buf_llseek,
.poll = dma_buf_poll,
};
struct dma_buf {
size_t size;
struct file *file;/*关联的file结构体*/
struct list_head attachments;
const struct dma_buf_ops *ops;/*dma_buf的mmap县官操作*/
/* mutex to serialize list manipulation, attach/detach and vmap/unmap */
struct mutex lock;
unsigned vmapping_counter;
void *vmap_ptr;
const char *exp_name;
struct list_head list_node;
void *priv;
struct reservation_object *resv;
/* poll support */
wait_queue_head_t poll;/*poll时候的等待队列*/
struct dma_buf_poll_cb_t {
struct fence_cb cb;/*fence同步栅的回调*/
wait_queue_head_t *poll;/*同步poll操作*/
unsigned long active;
} cb_excl, cb_shared;
};
dma_buf_fd dma_buf和fd绑定
int dma_buf_fd(struct dma_buf *dmabuf, int flags)
{
int fd;
if (!dmabuf || !dmabuf->file)
return -EINVAL;
fd = get_unused_fd_flags(flags);
if (fd < 0)
return fd;
fd_install(fd, dmabuf->file);
return fd;
}
回顾gralloc lock步骤中的mmap
err = open_device();
if(ioctl(mIonFd, ION_IOC_ALLOC, &ionAllocData)) {
...
}
fd_data.handle = ionAllocData.handle;
handle_data.handle = ionAllocData.handle;
if(ioctl(mIonFd, ION_IOC_MAP, &fd_data)) {
...
}
if(!(data.flags & ION_SECURE)) {
base = mmap(0, ionAllocData.len, PROT_READ|PROT_WRITE,
MAP_SHARED, fd_data.fd, 0);
...
memset(base, 0, ionAllocData.len);
// Clean cache after memset
clean_buffer(base, data.size, data.offset, fd_data.fd,
CACHE_CLEAN_AND_INVALIDATE);
}
data.base = base;
data.fd = fd_data.fd;
ioctl(mIonFd, ION_IOC_FREE, &handle_data);
status_t SurfaceFlinger::createBufferLayer(const spdma_buf file的mmap
static int dma_buf_mmap_internal(struct file *file, struct vm_area_struct *vma)
{
struct dma_buf *dmabuf;
if (!is_dma_buf_file(file))
return -EINVAL;
dmabuf = file->private_data;
/* check for overflowing the buffer's size */
if (vma->vm_pgoff + ((vma->vm_end - vma->vm_start) >> PAGE_SHIFT) >
dmabuf->size >> PAGE_SHIFT)
return -EINVAL;
return dmabuf->ops->mmap(dmabuf, vma);
}
ion_mmap
static int ion_mmap(struct dma_buf *dmabuf, struct vm_area_struct *vma)
{
struct ion_buffer *buffer = dmabuf->priv;
int ret = 0;
if (!buffer->heap->ops->map_user) {
pr_err("%s: this heap does not define a method for mapping to userspace\n",
__func__);
return -EINVAL;
}
if (ion_buffer_fault_user_mappings(buffer)) {
vma->vm_flags |= VM_IO | VM_PFNMAP | VM_DONTEXPAND |
VM_DONTDUMP;
vma->vm_private_data = buffer;
vma->vm_ops = &ion_vma_ops;
ion_vm_open(vma);
return 0;
}
if (!(buffer->flags & ION_FLAG_CACHED))
vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
mutex_lock(&buffer->lock);
ret = buffer->heap->ops->map_user(buffer->heap, buffer, vma);
mutex_unlock(&buffer->lock);
if (ret)
pr_err("%s: failure mapping buffer to userspace\n",
__func__);
return ret;
}
bool ion_buffer_fault_user_mappings(struct ion_buffer *buffer)
{
return (buffer->flags & ION_FLAG_CACHED) &&
!(buffer->flags & ION_FLAG_CACHED_NEEDS_SYNC);
}
ion_system_heap ion_heap_map_user
int ion_heap_map_user(struct ion_heap *heap, struct ion_buffer *buffer,
struct vm_area_struct *vma)
{
struct sg_table *table = buffer->sg_table;
unsigned long addr = vma->vm_start;
unsigned long offset = vma->vm_pgoff * PAGE_SIZE;
struct scatterlist *sg;
int i;
int ret;
for_each_sg(table->sgl, sg, table->nents, i) {
struct page *page = sg_page(sg);
unsigned long remainder = vma->vm_end - addr;
unsigned long len = sg->length;
if (offset >= sg->length) {
offset -= sg->length;
continue;
} else if (offset) {
page += offset / PAGE_SIZE;
len = sg->length - offset;
offset = 0;
}
len = min(len, remainder);
ret = remap_pfn_range(vma, addr, page_to_pfn(page), len,
vma->vm_page_prot);
if (ret)
return ret;
addr += len;
if (addr >= vma->vm_end)
return 0;
}
return 0;
}
ioctl ION_IOC_FREE 释放底层的句柄
case ION_IOC_FREE:
{
struct ion_handle *handle;
handle = ion_handle_get_by_id(client, data.handle.handle);
if (IS_ERR(handle))
return PTR_ERR(handle);
ion_free(client, handle);
ion_handle_put(handle);
break;
}
void ion_free(struct ion_client *client, struct ion_handle *handle)
{
bool valid_handle;
BUG_ON(client != handle->client);
mutex_lock(&client->lock);
valid_handle = ion_handle_validate(client, handle);
if (!valid_handle) {
WARN(1, "%s: invalid handle passed to free.\n", __func__);
mutex_unlock(&client->lock);
return;
}
mutex_unlock(&client->lock);
ion_handle_put(handle);
}
总结
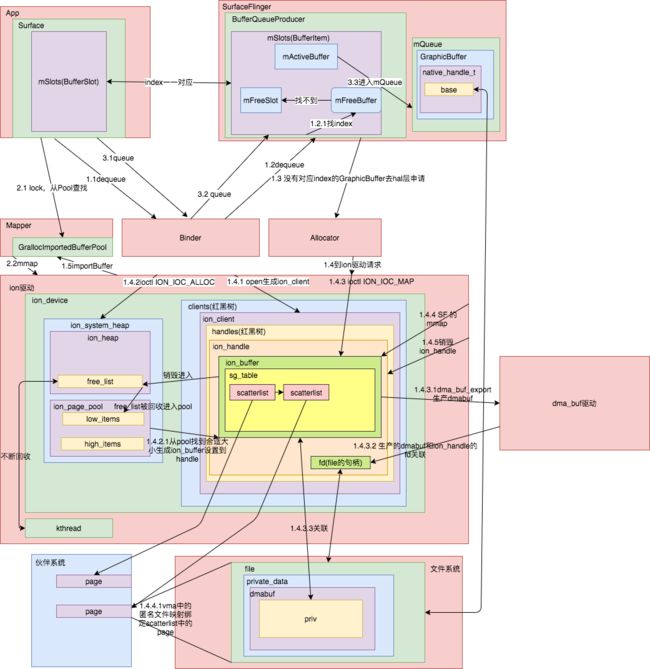
整个ion的初始化到这一步就完成,从device驱动结构体到缓存的核心ion_handle初始化。
对于mmap来说,其实就是把dmabuf中的file和ion_buffer的sg_table的scatterlist中page进行绑定处理,实现内存共享。
先使用ion驱动的fd,接着通过ioctl发送ION_IOC_MAP,之后所有就会使用关联dma_buf的file对应的fd。
思考