requests的简单使用:
import requests
requests是对urllib的封装,可以实现urllib的所有功能
"""
:param method: 发起什么类型的请求
:param url: 请求的目标网址
:param params: get请求后面的参数
:param data: post的表单数据
:param json:post请求的表单数据
:param headers:字典类型 请求头
:param cookies: 设置cookie信息,模拟用户请求
:param files: 使用它上传文件
:param auth: 网站认证信息:账号和密码
:param timeout:设置请求超时
:type timeout:
:param allow_redirects: 是否允许重定向
:type allow_redirects:
:param proxies: 设置代理
:param verify: 忽略证书认证,默认为true,表示不忽略, Defaults to True.
"""
url = 'http://www.baidu.com/'
url = 'http://www.xina.com/'
req_header = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
req_param = {
'wd':'小明'
}
response = requests.get(url,headers=req_header)
html = response.text
如果使用response.text出现乱码,
response.content.decode('')
print(response.encoding('utf-8'))
二进制类型的数据
b_html = response.content
状态码
code = response.status_code
获取响应头
response.headers = response.headers
获取请求头
r_header = response.request.headers
获取当前请求的url的地址
current_url = response.url
response.json():可以将json字符串转为python数据类型
print(code)
post请求
以豆瓣为例子:
import requests
form_data = {
'source': 'None',
'redir': 'https://www.douban.com',
'form_email': '18518753265',
'form_password': 'ljh12345678',
'captcha-solution': 'sneeze',
'captcha-id': 'UBvcK6xu9yysO5Ef7cYJtOaL:en',
'login': '登录',
}
header = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
url = 'https://accounts.douban.com/login'
response = requests.post(url,headers=header,data=form_data)
with open('douban.html','w') as file:
file.write(response.text)
re模块:匹配正则
re模块的导入:import re
正则表达式:是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。Regular Expression的‘Regular’一般被译为‘正则’、‘正规’、‘常规’。此处的‘Regular’既是‘规则’、‘规律’的意思,Regular Expression即‘描述某种规则的表达式’之意。简称:re
从左到右依次匹配。
导入re模块
import re
使用match方法进行匹配
result = re.match('正则表达式','要匹配的字符串')
如果上一步匹配到数据的话,可以使用group方法来提取数据
result.group()
re.match是用来进行正则匹配检查的方法,若字符串匹配正则表达式,则match方法返回匹配对象(Match Object),否则返回None(注意不是空字符串"")。匹配对象Macth Object具有group方法,用来返回字符串的匹配部分。
re.match()能够匹配出以“正则表达式”开头的字符串。如果第一个字符不匹配,匹配不成功。
re.search()在‘要匹配的字符串’中筛选匹配‘正则表达式’的字符串。只要在字符串当中有匹配的就会成功,就可以返回值。只会返回从左到右的第一个,之后的不会再返回。
re.findall()与re.search()几乎相同,唯一不同的是会返回所有匹配的值。
re.sub()将匹配到的数据进行替换
re.split()根据匹配进行切割字符串,并返回一个列表
import re
ret = re.sub(r"\d+",'998',"python = 997")
print(ret)
表示字符:
单字符匹配:
. 匹配任意一个字符(除了\n)
[ ] 匹配中括号中列举的字符
\d 匹配数字,即0-9
\D 匹配非数字,既不是数字
\s 匹配空白,即空格,tab键
\S 匹配非空白
\w 匹配单词字符,即a-z,A-Z,0-9,_下划线
\W 匹配非单词字符
例如:
import re
匹配任意一个字符
ret = re.match('.','aaksbdfii')
print(ret.group())
python中的字符串前面加上r表示原生字符串,正则表达式里使用“\”作为转义字符,假如你需要匹配文本中的字符“\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠,前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
import re
m = 'c:\a\b\c' # \一个只是转义,输出为c:\a\b\c
print(m)
ret = re.match('c:\\',m),group() # 正则表达式将用四个反斜杠转化成python中的两个反斜杠。
print(ret)
多字符匹配:
- 匹配前一个字符出现0次或者无限次,即可有可无
- 匹配前一个字符出现1次或者无限次,即至少有1次
? 匹配前一个字符出现1次或者0次,即要么有1次,要么没有
{m} 匹配前一个字符出现m次
{m,} 匹配前一个字符至少出现m次
{m,n}匹配骗一个字符出现从m到n次
表示边界:
^ 匹配字符串开头
$ 匹配字符串结尾
\b 匹配一个单词边界
\B 匹配非单词边界
表示匹配分组:
| 匹配左右任意一个表达式
(ab) 将括号中字符作为一个分组
\num 引用分组num匹配到的字符串
(?P
(?P=name) 引用别名为name分组匹配到的字符串
python正则表达式贪婪和非贪婪模式:
python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量‘抓取’满足匹配最长字符串,
在“*”“?”“+”“{m,n}”后面加上?,使贪婪变成非贪婪。会要求正则匹配的越少越好。
xpath基本语法
什么是xpath?
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
什么是xml?
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 HTML
XML 的设计宗旨是传输数据,而非显示数据
XML 的标签需要我们自行定义。
XML 被设计为具有自我描述性。
XML 是 W3C 的推荐标准
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
写一个事例:
使用 lxml 的 etree 库
from lxml import etree
#这是一段html代码
html = """
"""
打印
result = html.xpath('//li')
print result # 打印标签的元素集合
print len(result)
print type(result)
print type(result[0])
输出结果:
[
5
获取
result = html.xpath('//li/@class')
print (result)
运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
打印
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1"]')
print(result)
运行结果:
[
. 获取
result = html.xpath('//li//span')
print(result)
运行结果:
[
获取
result = html.xpath('//li/a//@class')
print(result)
运行结果:
['blod']
BeautifulSoup4解析器
CSS 选择器:BeautifulSoup4
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
CSS 选择器:BeautifulSoup4
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
导入方式:
from bs4 import BeautifulSoup
CSS选择器
这就是另一种与 find_all 方法有异曲同工之妙的查找方法.
写 CSS 时,标签名不加任何修饰,类名前加.,id名前加#
在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
| 表达式 | 说明 |
|---|---|
| * | 选择所有节点 |
| #container | 选择id为container的节点 |
| .container | 选取所有class包含container的节点 |
| li a | 选取所有li下的所有a节点 |
| div#container > ul | 选取id为container的div的第一个ul子元素 |
| a[href="http://jobbole.com"] | 选取所有href属性为jobbole.com值的a元素 |
| a[href*=”jobole”] | 选取所有href属性包含jobbole的a元素 |
| a[href^=“http”] | 选取所有href属性值以http开头的a元素 |
| a[href$=“.jpg”] | 选取所有href属性值以.jpg结尾的a元素 |
| div:not(#container) | 选取所有id非container的div属性 |
| li:nth-child(3) | 选取第三个li元素 |
| tr:nth-child(2n) | 第偶数个tr |
pyQuery解析器
- 官方文档:https://pythonhosted.org/pyquery/index.html#
- 中文教程:http://www.geoinformatics.cn/lab/pyquery/
安装方法:pip3 install pyquery
由于 pyquery 依赖于 lxml ,要先安装 lxml ,否则会提示失败。
pip3 install lxml

实例:
p=pq("
获取相应的 HTML 块
print (p('head').html())
获取相应的文本内容
print (p('head').text())
输出:
'''
Hello World!
'''
d = pq(
"
test 1
test 2
)
获取 元素内的 HTML 块
print (d('div').html())
获取 id 为 item-0 的元素内的文本内容
print (d('#item-0').text())
获取 class 为 item-1 的元素的文本内容
print (d('.item-1').text())
'''输出:
test 1
test 2
test 1
test 2
'''
d = pq(
"
test 1
test 2
"
)
获取第二个 p 元素的文本内容
print (d('p').eq(1).text())
'''输出
test 2
'''
d = pq("
test 1
test 2
")
查找 内的 p 元素
print d('div').find('p')
查找 内的 p 元素,输出第一个 p 元素
print d('div').find('p').eq(0)
'''输出:
test 1
test 2
test 1
'''
d = pq("
test 1
test 2
")
查找 class 为 item-1 的 p 元素
print d('p').filter('.item-1')
查找 id 为 item-0 的 p 元素
print d('p').filter('#item-0')
'''输出:
test 2
test 1
'''
d = pq("
test 1
test 2")
获取
标签的属性 id
print(d('p').attr('id'))
修改 标签的 class 属性为 new
print(d('a').attr('class','new'))
'''输出:
item-0
test 2
'''
多线程多进程:
实现多任务的方式:多线程,多进程,协程,多进程+多线程
为什么能实现多任务?
并行:同时发起,同时执行(4核,4个任务)
并发:同时发起,单个执行
在python语言中,并不能够真正意义上实现多线程,因为cpython解释器
有一个全局的GIL解释器锁,来保证同一时刻只有一个线程在执行
线程:是CPU执行的基本单元,占用的资源非常少,并且线程和线程之间的资源是共享的,
线程是依赖进程存在的,多线程一般适用于IO密集/操作,线程的执行是无序的
进程:是操作系统进行资源分配的节本单元,进程的执行也是无序的,每一个进程都有自己的存储空间,
进程之间的资源不共享,多进程能够充分利用CPU,所有多进程一般适用于计算密集型操作
 1.png
1.png
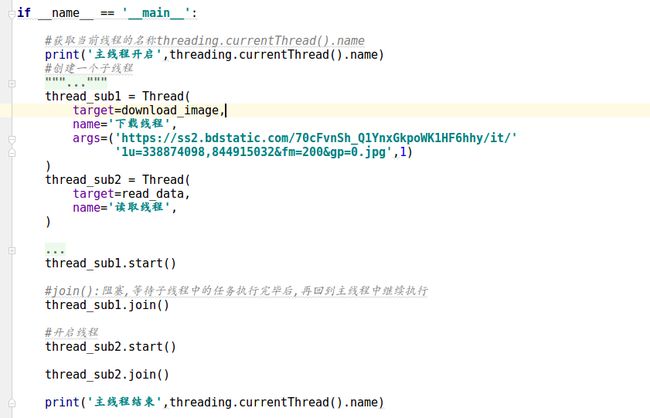 2.png
2.png
 1.png
1.png
 2.png
2.png
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。 Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
可以从 PyPI 网站下载 Selenium库https://pypi.python.org/simple/selenium , 也可以用第三方管理器 pip用命令安装:
pip3 install selenium
selenium 官方参考文档: http://selenium-python.readthedocs.io/index.html
selenium中文文档: http://selenium-python-zh.readthedocs.io
Selenium也分为有界面浏览器和无界面浏览器
谷歌驱动(chromedriver)下载地址: http://chromedriver.storage.googleapis.com/index.html
PhantomJS无头浏览器下载地址 无界面浏览器引擎,无界面可脚本编程的webkit浏览器引擎(目前chrom也可以支持无界面请求了) 下载地址: http://phantomjs.org/download.html API使用说明: http://phantomjs.org/api/command-line.html2.1.1
火狐驱动下载路径(GeckoDriver):https://github.com/mozilla/geckodriver/releases (2.3.8是最新的,下载的驱动版本一定要支持你当前的浏览器版本)
 s1.png
s1.png
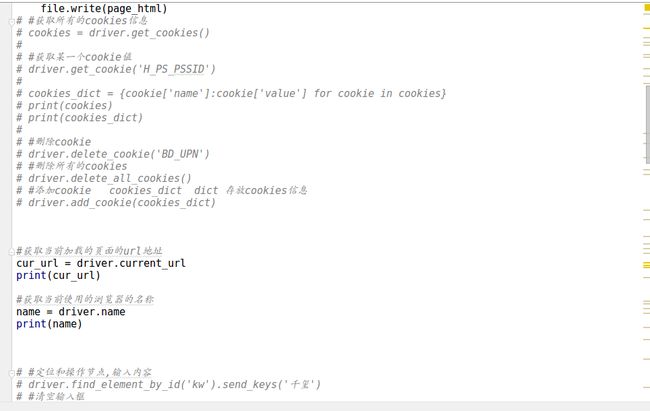 s2.png
s2.png
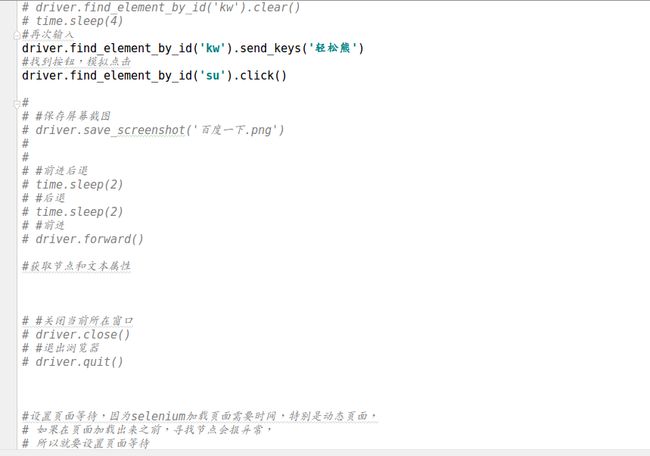 s3.png
s3.png
 s4.png
s4.png
 s5.png
s5.png
 s6.png
s6.png
print (d('div').html())
获取 id 为 item-0 的元素内的文本内容
print (d('#item-0').text())
获取 class 为 item-1 的元素的文本内容
print (d('.item-1').text())
'''输出:
test 1
test 2
test 1
test 2
'''
d = pq(
"
test 1
test 2
)
获取第二个 p 元素的文本内容
print (d('p').eq(1).text())
'''输出
test 2
'''
d = pq("
test 1
test 2
查找 内的 p 元素
print d('div').find('p')
查找 内的 p 元素,输出第一个 p 元素
print d('div').find('p').eq(0)
'''输出:
test 1
test 2
test 1
'''
d = pq("
test 1
test 2
")
查找 class 为 item-1 的 p 元素
print d('p').filter('.item-1')
查找 id 为 item-0 的 p 元素
print d('p').filter('#item-0')
'''输出:
test 2
test 1
'''
d = pq("
test 1
test 2")
获取
标签的属性 id
print(d('p').attr('id'))
修改 标签的 class 属性为 new
print(d('a').attr('class','new'))
'''输出:
item-0
test 2
'''
多线程多进程:
实现多任务的方式:多线程,多进程,协程,多进程+多线程
为什么能实现多任务?
并行:同时发起,同时执行(4核,4个任务)
并发:同时发起,单个执行
在python语言中,并不能够真正意义上实现多线程,因为cpython解释器
有一个全局的GIL解释器锁,来保证同一时刻只有一个线程在执行
线程:是CPU执行的基本单元,占用的资源非常少,并且线程和线程之间的资源是共享的,
线程是依赖进程存在的,多线程一般适用于IO密集/操作,线程的执行是无序的
进程:是操作系统进行资源分配的节本单元,进程的执行也是无序的,每一个进程都有自己的存储空间,
进程之间的资源不共享,多进程能够充分利用CPU,所有多进程一般适用于计算密集型操作
1.png
2.png
1.png
2.png
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。 Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
可以从 PyPI 网站下载 Selenium库https://pypi.python.org/simple/selenium , 也可以用第三方管理器 pip用命令安装:
pip3 install selenium
selenium 官方参考文档: http://selenium-python.readthedocs.io/index.html
selenium中文文档: http://selenium-python-zh.readthedocs.io
Selenium也分为有界面浏览器和无界面浏览器
谷歌驱动(chromedriver)下载地址: http://chromedriver.storage.googleapis.com/index.html
PhantomJS无头浏览器下载地址 无界面浏览器引擎,无界面可脚本编程的webkit浏览器引擎(目前chrom也可以支持无界面请求了) 下载地址: http://phantomjs.org/download.html API使用说明: http://phantomjs.org/api/command-line.html2.1.1
火狐驱动下载路径(GeckoDriver):https://github.com/mozilla/geckodriver/releases (2.3.8是最新的,下载的驱动版本一定要支持你当前的浏览器版本)
s1.png
s2.png
s3.png
s4.png
s5.png
s6.png
print d('div').find('p')
查找 内的 p 元素,输出第一个 p 元素
print d('div').find('p').eq(0)
'''输出:
test 1
test 2
test 1
'''
d = pq("
test 1
test 2
")
查找 class 为 item-1 的 p 元素
print d('p').filter('.item-1')
查找 id 为 item-0 的 p 元素
print d('p').filter('#item-0')
'''输出:
test 2
test 1
'''
d = pq("
test 1
test 2")
获取
标签的属性 id
print(d('p').attr('id'))
修改 标签的 class 属性为 new
print(d('a').attr('class','new'))
'''输出:
item-0
test 2
'''
多线程多进程:
实现多任务的方式:多线程,多进程,协程,多进程+多线程
为什么能实现多任务?
并行:同时发起,同时执行(4核,4个任务)
并发:同时发起,单个执行
在python语言中,并不能够真正意义上实现多线程,因为cpython解释器
有一个全局的GIL解释器锁,来保证同一时刻只有一个线程在执行
线程:是CPU执行的基本单元,占用的资源非常少,并且线程和线程之间的资源是共享的,
线程是依赖进程存在的,多线程一般适用于IO密集/操作,线程的执行是无序的
进程:是操作系统进行资源分配的节本单元,进程的执行也是无序的,每一个进程都有自己的存储空间,
进程之间的资源不共享,多进程能够充分利用CPU,所有多进程一般适用于计算密集型操作
1.png
2.png
1.png
2.png
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。 Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
可以从 PyPI 网站下载 Selenium库https://pypi.python.org/simple/selenium , 也可以用第三方管理器 pip用命令安装:
pip3 install selenium
selenium 官方参考文档: http://selenium-python.readthedocs.io/index.html
selenium中文文档: http://selenium-python-zh.readthedocs.io
Selenium也分为有界面浏览器和无界面浏览器
谷歌驱动(chromedriver)下载地址: http://chromedriver.storage.googleapis.com/index.html
PhantomJS无头浏览器下载地址 无界面浏览器引擎,无界面可脚本编程的webkit浏览器引擎(目前chrom也可以支持无界面请求了) 下载地址: http://phantomjs.org/download.html API使用说明: http://phantomjs.org/api/command-line.html2.1.1
火狐驱动下载路径(GeckoDriver):https://github.com/mozilla/geckodriver/releases (2.3.8是最新的,下载的驱动版本一定要支持你当前的浏览器版本)
s1.png
s2.png
s3.png
s4.png
s5.png
s6.png
print d('div').find('p').eq(0)
'''输出:
test 1
test 2
test 1
'''
d = pq("
test 1
test 2
查找 class 为 item-1 的 p 元素
print d('p').filter('.item-1')
查找 id 为 item-0 的 p 元素
print d('p').filter('#item-0')
'''输出:
test 2
test 1
'''
d = pq("
test 1
test 2获取
标签的属性 id
print(d('p').attr('id'))
修改 标签的 class 属性为 new
print(d('a').attr('class','new'))
'''输出:
item-0
test 2
'''
多线程多进程:
实现多任务的方式:多线程,多进程,协程,多进程+多线程
为什么能实现多任务?
并行:同时发起,同时执行(4核,4个任务)
并发:同时发起,单个执行
在python语言中,并不能够真正意义上实现多线程,因为cpython解释器
有一个全局的GIL解释器锁,来保证同一时刻只有一个线程在执行
线程:是CPU执行的基本单元,占用的资源非常少,并且线程和线程之间的资源是共享的,
线程是依赖进程存在的,多线程一般适用于IO密集/操作,线程的执行是无序的
进程:是操作系统进行资源分配的节本单元,进程的执行也是无序的,每一个进程都有自己的存储空间,
进程之间的资源不共享,多进程能够充分利用CPU,所有多进程一般适用于计算密集型操作
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。 Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
可以从 PyPI 网站下载 Selenium库https://pypi.python.org/simple/selenium , 也可以用第三方管理器 pip用命令安装:
pip3 install selenium
selenium 官方参考文档: http://selenium-python.readthedocs.io/index.html
selenium中文文档: http://selenium-python-zh.readthedocs.io
Selenium也分为有界面浏览器和无界面浏览器
谷歌驱动(chromedriver)下载地址: http://chromedriver.storage.googleapis.com/index.html
PhantomJS无头浏览器下载地址 无界面浏览器引擎,无界面可脚本编程的webkit浏览器引擎(目前chrom也可以支持无界面请求了) 下载地址: http://phantomjs.org/download.html API使用说明: http://phantomjs.org/api/command-line.html2.1.1
火狐驱动下载路径(GeckoDriver):https://github.com/mozilla/geckodriver/releases (2.3.8是最新的,下载的驱动版本一定要支持你当前的浏览器版本)