作者:justmine
头条号:大数据与云原生
微信公众号:大数据与云原生
创作不易,在满足创作共用版权协议的基础上可以转载,但请以超链接形式注明出处。
为了方便阅读,微信公众号已按分类排版,后续的文章将在移动端首发,想学习云原生相关知识,请关注我。
一、回顾
云原生 - 体验Istio的完美入门之旅(一)
云原生 - Why is istio(二)
云原生 - Istio可观察性之分布式跟踪(三)
[请持续关注...]
如前所述,业务微服务化后,每个单独的微服务可能会有很多副本,多个版本,这么多微服务之间的相互调用、管理和治理非常复杂,Istio统一封装了这块内容在代理层,最终形成一个分布式的微服务代理集群(服务网格)。管理员通过统一的控制平面来配置整个集群的应用流量、安全规则等,代理会自动从控制中心获取动态配置,根据用户的期望来改变行为。
话外音:借着微服务和容器化的东风,传统的代理摇身一变,成了如今炙手可热的服务网格。
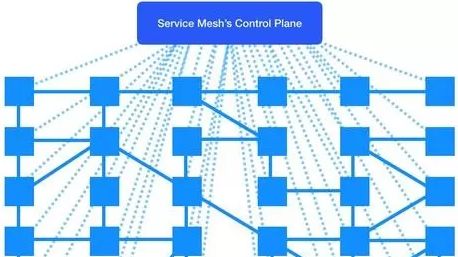
Istio就是上面service mesh架构的一种实现,通过代理(默认是envoy)全面接管服务间通信,完全支持主流的通信协议HTTP/1.1,HTTP/2,gRPC ,TCP等;同时进一步细分控制中心,包括Pilot、Mixer、Citadel等。
话外音:后面系列会详细介绍控制中心的各个组件,请持续关注。
整体功能描述如下:
连接(Connect)
控制中心从集群中获取所有微服务的信息,并分发给代理,这样代理就能根据用户的期望来完成服务之间的通信(自动地服务发现、负载均衡、流量控制等)。
保护(Secure)
所有的流量都是通过代理,当代理接收到未加密流量时,可以自动做一次封装,把它升级成安全的加密流量。
控制(Control)
用户可以配置各种规则(比如 RBAC 授权、白名单、rate limit 、quota等),当代理发现服务之间的访问不符合这些规则,就直接拒绝掉。
观察(Observe)
所有的流量都经过代理,因此代理对整个集群的访问情况知道得一清二楚,它把这些数据上报到控制中心,那么管理员就能观察到整个集群的流量情况。
二、前言
作为服务网格的一个完整解决方案,为了追求完美,Istio高度抽象并设计了一个优雅的架构,涉及到众多的组件,它们分工协作,共同组成了完整的控制平面。为了更好地学习如何运用Istio的连接、安全、控制、可观察性全面地治理分布式微服务应用,先从战略上鸟瞰Istio,进一步从战术上学习Istio将更加容易,故作者决定从可观察性开始Istio的布道,先体验,再实践,最后落地,一步步爱上Istio,爱上云原生,充分利用云资源的优势,解放应用开发工程师的双手,使他们仅仅关注业务实现,让专业的人做专业的事,为企业创造更大的价值。
三、Istio的可观察性
1. 日志
当流量流入服务网格中的微服务时,Istio可以为每个请求生成完整的记录,包括源和目标的元数据等。使运维人员能够将服务行为的审查控制到单个微服务的级别。
2. 监控
Istio基于监控的4 个黄金信号(延迟、流量、错误、饱和度)来生成一系列的服务指标,同时还提供了一组默认的服务网格监控大盘。
话外音:Istio还为服务网格控制平面提供了更为详细的监控指标。
3. 分布式跟踪
Istio根据采样率为每个请求生成完整的分布式追踪轨迹,以便运维人员可以理解服务网格内微服务的依赖关系和调用流程。
可以看出,Istio的可观察性,致力于解决两方面的问题:
1、症状:什么病?
- 是Istio的问题?
- 哪个Istio组件的问题?
- [...]
2、原因:为什么得这种病?
- 怎样跟踪、分析、定位?
- 是异常,还是偶然事件?
- [...]
知晓了症状(什么)和原因(为什么),治病应该就信手拈来了吧,如果还不知如何治病,那就去格物致知吧。
话外音:不仅如此,Istio还支持按需降级或关闭某些功能的能力,请持续关注。
四、Why - 为什么需要监控?
在软件形态上,Service Mesh将业务系统中的非业务功能剥离到独立的中间件系统中。同时,为了解耦运维,以Sidecar的方式将中间系统注入到业务容器内,在落地过程中难免会面临稳定性、运维模式变化等诸多的问题与挑战,如何确保网格的生产稳定和可靠呢?
从设计之初,Istio都致力于建设一个高可用的基础架构,以防止服务质量降低而影响业务本身。为了跟踪分布式系统中的每个信号,Istio基于Google网站可靠性工程师小组(SRE)定义的四个监控关键指标,全面而详细地监控业务系统和自身。
黄金四信号:
延迟(Latency)
处理请求的时间,即发送请求和接收响应所需的时间,比如:请求成功与请求失败的延迟。
在微服务中提倡“快速失败”,特别要注意那些延迟较大的错误请求。这些缓慢的错误请求会明显影响系统的性能,因此追踪这些错误请求的延迟是非常重要的。
流量(Traffic)
也称吞吐量,用于衡量系统的容量需求,即收到多少请求,比如:请求率(HTTP请求数/秒)。
对于分布式系统,它可以帮助您提前规划容量以满足即将到来的需求等。
错误(Errors)
衡量系统发生的错误情况,比如:请求错误率。
饱和度(Saturation)
衡量网络和服务器等资源的负载,主要强调最能影响服务状态的受限制资源。
每个资源都有一个限制,之后性能将降低或变得不可用。了解分布式系统的哪些部分可能首先变得饱和,以便在性能下降之前调整容量。
黄金四信号几乎深度覆盖了所有想知道到底怎么回事的相关信息,既是监控系统发现问题的关键,也是保障高可用基础性框架的关键。
话外音:分布式系统不同于单体应用,监控信号是异常检测的关键,是预警的重要积木。
五、What - Istio的监控?
为了监控应用服务行为,Istio为服务网格中所有出入的服务流量都生成了指标,例如总请求数、错误率和请求响应时间等。
为了监控服务网格本身,Istio组件可以导出自身内部行为的详细统计指标,以提供对服务网格控制平面功能和健康情况的洞察能力。
话外音:Istio指标收集可以由运维人员配置来驱动,即运维人员决定如何以及何时收集指标,以及收集的详细程度,灵活地调整指标收集策略来满足个性化的监控需求。
代理级别指标
Istio指标收集从sidecar代理(Envoy)开始,它为通过代理的所有流量(入站和出站)生成一组丰富的指标,同时允许运维人员为每个工作负载实例(微服务)配置如何生成和收集哪些指标。
Envoy统计信息收集详细说明:https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/observability/statistics.html?highlight=statistics
服务级别指标
除了代理级别指标之外,Istio还提供了一组用于监控服务通信的指标。这些指标涵盖了四个基本的服务监控需求:延迟、流量、错误、饱和度,同时Istio也提供了一组默认的仪表盘,用于监控基于这些指标的服务行为。
默认的Istio指标由Istio提供的配置集定义并默认导出到Prometheus。运维人员可以自由地修改这些指标的形态和内容,更改它们的收集机制,以满足各自的监控需求。
备注:运维人员也可以选择关闭服务级别指标的生成和收集。
控制面板指标
每一个Istio的组件(Pilot、Galley、Mixer等)都提供了对自身监控指标的集合。这些指标容许监控Istio自己的行为。
六、How - Istio如何配置监控?
1、部署监控大盘
root@just:~# istioctl manifest apply --set values.grafana.enabled=true
[...]
✔ Finished applying manifest for component Grafana.
[...]
root@just:~# kubectl -n istio-system get svc grafana -o yaml
apiVersion: v1
kind: Service
[...]
name: grafana
namespace: istio-system
spec:
[...]
type: NodePort
ports:
[...]
nodePort: 3000
[...]话外音:测试环境使用NodePort联网,仅供参考。
浏览器访问:http://[主机IP]:3000/dashboard/db/istio-mesh-dashboard。
微服务应用BookInfo监控大盘
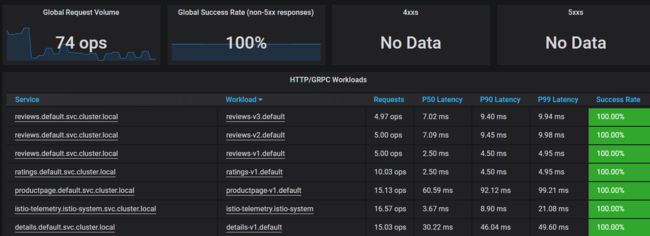
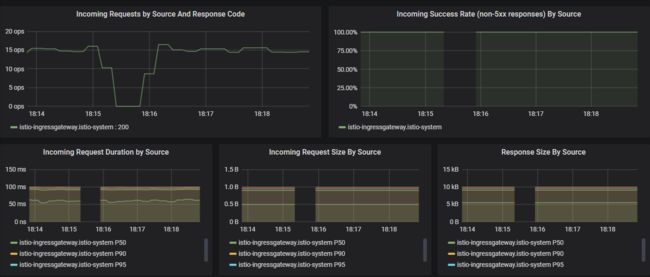
为了更好的阅读体验,上面仅截取了部分监控,可以看出监控的四个黄金信号吧,同时,为了使指标统计更精确,有的指标还通过P50、P90、P99维度分别展示,避免长尾误导。除了业务监控,Istio也提供了自身平台的监控大盘,如下:
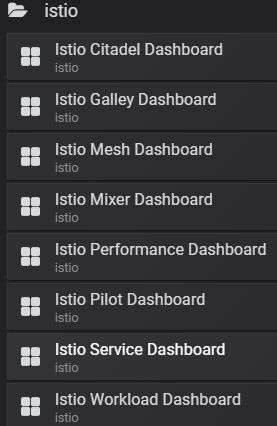
可以看出Istio的默认监控大盘非常全面,该监控的都监控起来了,到目前为止,大家已经从整体上了解和体验Istio的监控体系。
2、扩展新指标
为了支持个性化监控需求,Istio支持自定义指标来扩展监控体系,下面将添加一个新指标(将每个请求计数两次),并发送到Prometheus。
备注:Istio也支持自定义Mixer Adapter来支持其他监控后端。
2.1 定义指标
创建名为doublerequestcount的新指标,告诉Mixer如何根据Envoy报告的属性为请求创建指标维度和生成值,即对于doublerequestcount的每个instance,指示Mixer为它提供值2。
备注:Istio将为每个请求生成一个Instance。
# Configuration for metric instances
apiVersion: config.istio.io/v1alpha2
kind: instance
metadata:
name: doublerequestcount # metric name
namespace: istio-system
spec:
compiledTemplate: metric
params:
value: "2" # count each request twice
# 表示指标的维度,为prometheus指标的{}部分。
# 参考: {destination="",instance="",job="",message="",reporter="",source=""}`
dimensions:
reporter: conditional((context.reporter.kind | "inbound") == "outbound", "client", "server")
source: source.workload.name | "unknown"
destination: destination.workload.name | "unknown"
message: '"twice the fun!"'
monitored_resource_type: '"UNSPECIFIED"'2.2 定义指标处理器
创建能够处理生成的instances的handlers,即告诉Prometheus适配器如何将收到的指标转换为Prometheus格式的指标。
# Configuration for a Prometheus handler
apiVersion: config.istio.io/v1alpha2
kind: handler
metadata:
name: doublehandler
namespace: istio-system
spec:
compiledAdapter: prometheus
params:
metrics:
# Prometheus metric name
- name: double_request_count
# Mixer instance name (完全限定名称)
instance_name: doublerequestcount.instance.istio-system
kind: COUNTER
# 此处标签为doublerequestcount instance配置的dimensions。
label_names:
- reporter
- source
- destination
- message在指标名称之前,Prometheus适配器会添加了istio_前缀,因此该指标在Prometheus中最终名称为 istio_double_request_count。
2.3 关联指标到处理器
根据一组rules向handlers分配instances,如下将网格中的所有请求生成的指标都发送到doublehandler处理器,也可以使用match条件,筛选指标。
# Rule to send metric instances to a Prometheus handler
apiVersion: config.istio.io/v1alpha2
kind: rule
metadata:
name: doubleprom
namespace: istio-system
spec:
actions:
- handler: doublehandler
instances: [ doublerequestcount ]2.4 通过Prometheus UI查看新指标

到目前为止,就可以在监控大盘(grafana)中使用该指标了。
七、总结
本篇先回顾了Istio历史系列文章,然后大致概述了Istio的整体功能,以及可观察性,最后从why、what、how的角度详细介绍了Istio的监控体系,并通过自定义指标演示了如何支持个性化监控需求。除了分布式跟踪、监控,Istio的可观察性还包括日志,敬请期待,请持续关注。
八、最后
如果有什么疑问和见解,欢迎评论区交流。
如果觉得本篇有帮助的话,欢迎推荐和转发。
如果觉得本篇非常不错的话,可以请作者吃个鸡腿,创作的源泉将如滔滔江水连绵不断,嘿嘿。
九、参考
https://istio.io/docs/concepts/observability
https://istio.io/docs/reference/config/policy-and-telemetry/metrics
https://istio.io/docs/ops/common-problems/observability-issues
https://raw.githubusercontent.com/istio/istio/master/install/kubernetes/helm/istio/charts/mixer/templates/config.yaml
https://istio.io/docs/tasks/observability/metrics/using-istio-dashboard
https://istio.io/docs/tasks/observability/metrics/collecting-metrics
https://istio.io/docs/tasks/observability/metrics/tcp-metrics
https://istio.io/docs/tasks/observability/metrics/querying-metrics
https://istio.io/docs/reference/config/policy-and-telemetry/adapters/prometheus
https://mp.weixin.qq.com/s/KMnIzA5i99ZSkAtIujVqJA
https://istio.io/docs/tasks/observability/metrics/collecting-metrics