本文转至我在知乎上写的文章
---------------------------------------------------------------
在这样一个人工智能呼声越来越高,大数据遍地的时代,作为一个科技工作者,感觉不会点Python实在是说不过去啊。最近在看阿里招聘,正好借这个机会爬取并分析一下阿里的招聘信息,看看能不能有啥收获。
这里以阿里的数据岗,工作地点:杭州,职位类别:技术类,为搜索关键词。本想继续在Python中写一个loop来执行翻页命令的,发现直接翻页的话,地点信息和职位类别都会扩大,不仅局限于杭州和技术类。好在自己分析,不那么着急时间,那就用selenium驱动浏览器直接爬取吧。
要把数据爬下来总共分几步呢,先自己记好,后面直接按照这个frame丰富函数即可:
打开浏览器(完成转至网页,输入关键词等操作)——读取网页信息,提取数据——翻页——读取网页信息,读取数据……
第一步:打开浏览器
导入selenium库,以便打开网页:
from selenium import webdriver
导入Keys,以便能输入关键词数据和选中工作地点和职位类别:
from selenium.webdriver.common.keys import Keys
定义打开浏览器的函数,找到关键词位置并选中:
def open_browser(url): #打开浏览器,并选择杭州,技术岗,输入关键词‘数据’进行查找
browser.get(url)
elem = browser.find_element_by_xpath('/html/body/div[4]/div[2]/div/div[1]/div/div[1]/span/span/a[1]').click()
time.sleep(2)
elem_1 = browser.find_element_by_xpath('/html/body/div[4]/div[2]/div/div[1]/div/div[2]/span/a[3]').click()
time.sleep(2)
elem_2 = browser.find_element_by_id('keyword')
elem_2.clear()
elem_2.send_keys('数据'+Keys.RETURN)
time.sleep(10)
(在分析网页的时候,发现里面很多数据的标签的父节点一样,因此选用xpath爬取数据更加便捷)
第二步:读取网页信息,提取数据
先读取当前网页信息
#------------------------读取招聘页面信息---------------------------------
def read_page():
Content = browser.page_source
return Content
之后基于获得的网页信息,提取数据
def get_data(Content):
selector=etree.HTML(Content)
Job_information1=[]
Job_information2=[]
for i in range(1,20,2): #网页里面的很多信息的父节点相同,因此用Xpath爬取,并替换相应位置的数字会更快捷一些
job_name=selector.xpath(r'/html/body/div[4]/div[2]/div/div[2]/table/tbody/tr[%s]/td[1]/span/a/text()'%(i))[0].strip()
job_characteristic=selector.xpath(r'/html/body/div[4]/div[2]/div/div[2]/table/tbody/tr[%s]/td[2]/span/text()'%(i))[0].strip()
job_location=selector.xpath(r'/html/body/div[4]/div[2]/div/div[2]/table/tbody/tr[%s]/td[3]/span/text()'%(i))[0].strip()
recruit_number=selector.xpath(r'/html/body/div[4]/div[2]/div/div[2]/table/tbody/tr[%s]/td[4]/span/text()'%(i))[0].strip()
job_updatetime=selector.xpath(r'/html/body/div[4]/div[2]/div/div[2]/table/tbody/tr[%s]/td[5]/span/text()'%(i))[0].strip()
job_information1=job_name+'@'+job_characteristic+'@'+job_location+'@'+recruit_number+'@'+job_updatetime+'@' #用@替换便于后期在excel中分列
Job_information1.append(job_information1)
for j in range(2,21,2):
job_description=selector.xpath(r'/html/body/div[4]/div[2]/div/div[2]/table/tbody/tr[%s]/td/div/p[1]/text()'%(j)) #岗位描述和岗位要求两个结果是列表
job_request=selector.xpath(r'/html/body/div[4]/div[2]/div/div[2]/table/tbody/tr[%s]/td/div/p[2]/text()'%(j))
job_Description=''
job_Request=''
for k in range(len(job_description)):
job_Description+=job_description[k].strip()
for h in range(len(job_request)):
job_Request+=job_request[h].strip()
job_information2=job_Description+'@'+job_Request
Job_information2.append(job_information2)
return Job_information1,Job_information2
第三步:翻页
显而易见,这个点击右箭头就好了,不过我在这里试了好几种发现’>’的方式,发现by_link_text这种方式效果最好
def change_page():
elem_3 = browser.find_element_by_link_text('>').click()
随后只要把所有函数粘结起来就好了!
下面对获得的数据进行下可视化处理,看看能不能发现什么规律呢?
首先,从时间维度看阿里在12月之前招聘需求相对较少,仅在11月20日出现过一次105人的小高峰。随后进入12月,招聘需求显著增加,圣诞节达到峰值招聘423人。
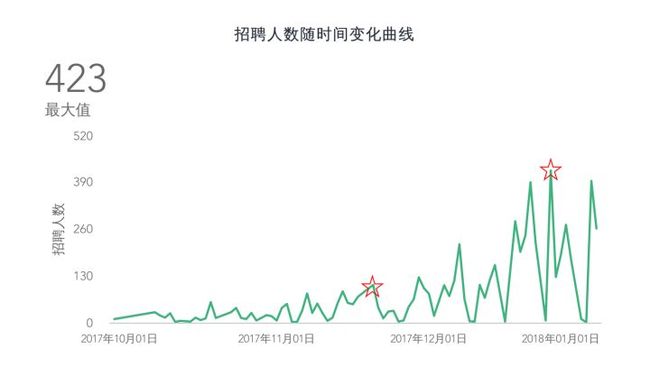
这是为什么呢?作为一个没有离职过的人不懂啊,和职场的几个朋友(跳槽老油条)交流后,确认了是因为企业为了避免年后大量人员跳槽造成的用人荒,而提前做的人才储备。看来以后离职虽说年终奖要拿,但是11月份之前一定要先把简历优化好啊。
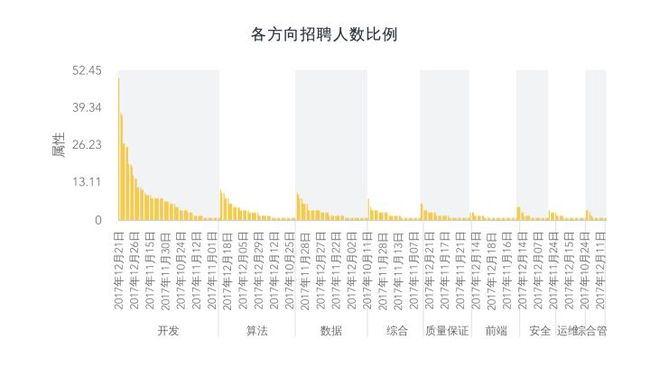
进一步,按照招聘方向统计结果也确认了,随着时间进入12月各个方向的人员招聘确实陆续增多,排在前三位的分别是:开发岗,算法岗,数据岗。
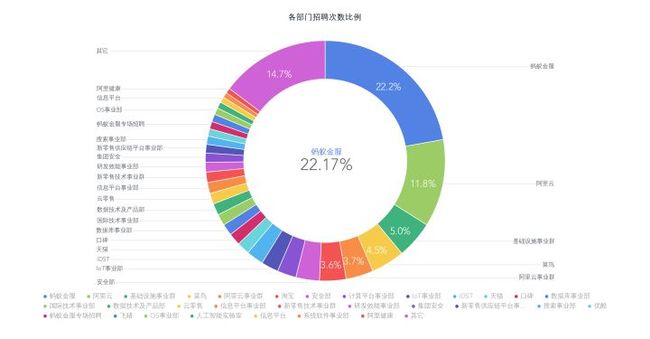
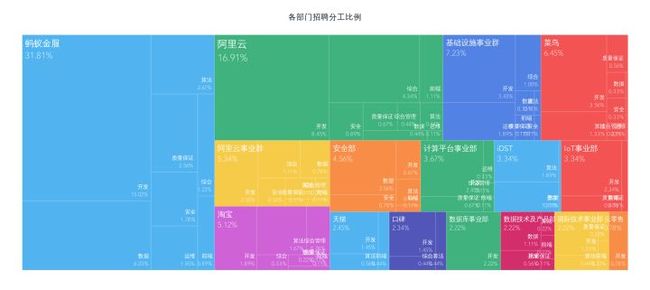
接着看下,各个部门在招聘过程中的需求情况。蚂蚁金服以22.2%的比例遥遥领先,阿里云11.8%跟随其后。足见,现在还是金融,云计算这些领域的市场缺口比较大啊,基础设施事业群第三,百度了一下,感觉是为其他业务部门提供技术支持的部门,可见阿里对平台框架构建的重视。
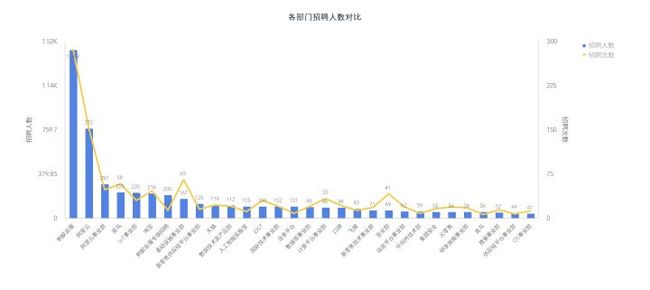
进一步量化分析下各个部门17年最后一个季度的招聘情况。蚂蚁金服最后一个季度招聘1449人,发布招聘信息286次。蚂蚁金服真的这么缺人么?
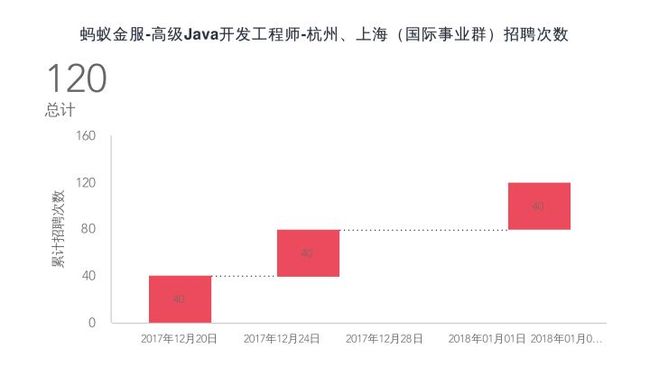
我基于时间线,对其中重复的职位名称进行了对比(这其中还不包括岗位描述一模一样但是名称不一样的职位),有93个职位发布信息次数超过2次,而且这其中一个职位最少要2个人,最多的例如下面这个位置居然一次需要40名java工程师。这个职位自12月20号发布以来,居然在25号和1月3号,又重新发布了2次(而且数量一次也没有减少哦)。又不是民工,这种高技术工种,5天时间招40个人的可能性不大吧。可见这个位置的需求比较迫切,另外是不是也能说明这个部门的领导比较push呢?所以我个人以为,金服未必有这么大的人才缺口,有些岗位比较紧迫,短时间内发布了多次招聘信息而已。
另外,有些部门招聘人数不多,但是却招聘了很多次,如基础建设事业群和安全部,是不是也是因为发布招聘信息次数过多呢?
另外,我依据部门和工作方向信息进一步分析了下各个部门内部的招聘情况。可见,开发方向在几个大的部门都是招聘的主要需求方向。只有安全部和iDST两个部门,对算法和数据方面的招聘更多一些。
好了,知道了阿里内部大体的招聘情况。下面,我们通过几个云图看下几个相关部门的招聘要求吧。由于,我爬取的是社招页面,所以每个部门要求最多的都是“经验”,不过由于分词用的还不太好,有些连词还过滤的不太好。这里不做过多解读。

阿里云招聘关键词

蚂蚁金服招聘关键词

阿里达摩院招聘关键词

人工智能招聘关键词
针对以上分析做一个总结:
1. 考虑到年后跳槽人数会显著增加,为避免企业“用人荒”,很多部门从12月份已经开始进行大规模的人才储备;
2. 阿里目前大数据方面的主要业务依然是面向金融(蚂蚁金服),IT(阿里云计算等)。招聘人员的需求前三位的依次为:开发岗,算法岗,数据岗;
3. 求职的时候,多留意一下那些短期内发布多次的职位信息,这些岗位用人需求应该更加急迫,HR也应该会更积极的给予反馈。
其实还有很多有价值的信息,感觉不太合适说的太透。
觉得对你有帮助的话请给个赞吧,谢谢!