为了体验 Scrapy 的强大功能,我们必须安装使用才知道。本章为大家讲述 Scrapy 的安装和入门使用。
Scrapy 的安装
和其他包的安装方法一样,我们使用 pip 来安装 Scrapy 框架:
pip install scrapy
安装完成之后,我们使用 scrapy 命令来测试是否安装成功:
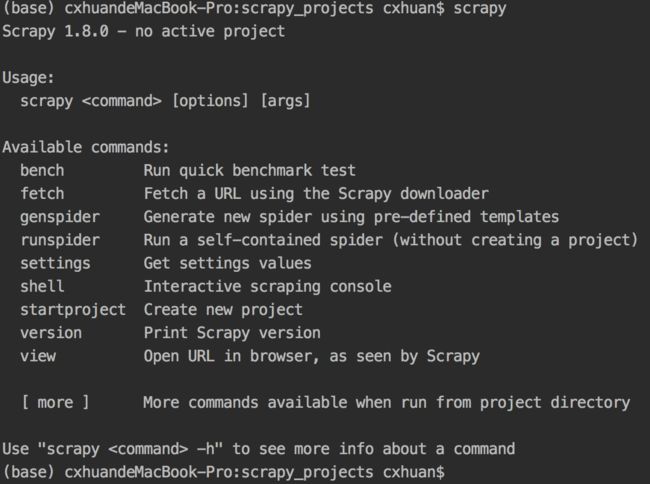
如果出现图中的内容,即表示安装成功了。
Scrapy 的使用
Scrapy 的使用分为以下四步:
- 新建 Scrapy 项目
- 生成一个爬虫
- 提取数据
- 保存数据
下面我们来分别看看这四步怎么做。
新建 Scrapy 项目
我们首先需要创建一个项目,创建项目的命令为:
scrapy startproject [项目名]
我们来实际操作一下:

我们可以看到创建项目命令输入后,下方会有提示:第一段是高速我们项目的目录地址,第二段是告诉我们生成 spider 文件的命令(先进入项目 mySpider 目录,然后通过命令 scrapy genspider example example.com 来创建)。
我们来看下新创建项目的目录结构:
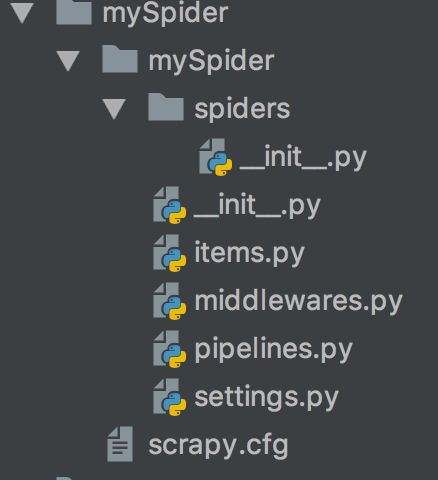
Scrapy 为我们自动生成了一下文件,这些文件的作用分别是:
- scrapy.cfg: 项目的配置文件。
- mySpider/: 项目的 Python 模块,将会从这里引用代码。
- mySpider/items.py: 项目的目标文件。
- mySpider/pipelines.py: 项目的管道文件。
- mySpider/settings.py: 项目的设置文件。
- mySpider/spiders/: 存储爬虫代码目录。
生成一个爬虫
我们根据创建项目后的命令行提示,来生成一个爬虫,命令为:
scrapy genspider [爬虫名] [domain]
命令包含两个变量,一个是爬虫名,另一个是限定域名。限定域名是为了限定我们爬虫爬取地址的范围。
我们来创建一个名为 author 的爬虫,命令如下:
scrapy genspider author "quotes.toscrape.com"
这里我准备爬取 http://quotes.toscrape.com/ 这个名人名言网站的作者名字,所以我们的域名限定为 quotes.toscrape.com。
命令执行完后,我们的 spiders 目录里面自动新增了一个 author.py 的文件。我们打开看看其内容:
# -*- coding: utf-8 -*-
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'author' # 爬虫名称
allowed_domains = ['quotes.toscrape.com'] # 允许爬的域名
start_urls = ['http://quotes.toscrape.com/'] # 起始 URL
# 解析方法
def parse(self, response):
pass
为了便于大家理解,我加上了简单的注释。其实也可以由我们自行创建 author.py 的爬虫文件并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦。
要建立一个 Spider,你必须用 scrapy.Spider 类创建一个子类,并规定了三个强制的属性和一个方法。
- name = "" :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
- allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的 URL 会被忽略。
- start_urls = ():爬取的 URL 列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些 urls 开始。其他子 URL 将会从这些起始 URL 中继承性生成。
- parse(self, response) :解析的方法,每个初始 URL 完成下载后将被调用,调用的时候传入从每一个 URL 传回的 Response 对象来作为唯一参数,主要作用是
负责解析返回的网页数据(response.body) 以及提取结构化数据(生成 item) 生成需要下一页的 URL 请求。
爬虫生成好后,我们将 start_urls 设置好了,起始爬虫就可以跑起来了,这时候,如果你运行命令:
scrapy crawl author
我们看到控制台会打印好多日志,这些日志是整个运行情况的跟踪记录和统计情况。
提取数据
爬虫可以运行了,但是我们还没有获取到我们需要的数据呢。我们可以看到 parse 方法的参数里面有 response,这其实是爬虫请求 URL 之后返回的响应内容。我们在 parse 方法里面对响应内容进行解析,就可以获取我们需要的数据。
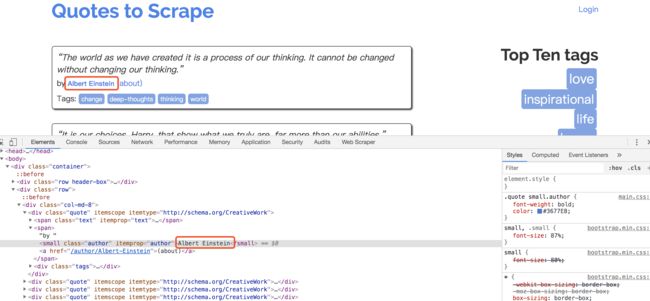
通过观察页面源码,我们可以获取到解析作者的路径,这里我用 XPath 来解析页面:
# -*- coding: utf-8 -*-
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'author' # 爬虫名称
allowed_domains = ['quotes.toscrape.com'] # 允许爬的域名
start_urls = ['http://quotes.toscrape.com/'] # 起始 URL
# 解析方法
def parse(self, response):
# 解析页面获取作者
authors = response.xpath('/html/body/div/div/div/div/span/small/text()').extract()
print(authors)
我们再次运行命令(这次我加了 --nolog):
scrapy crawl author --nolog
运行之后,我们可以看到上次的日志打印都消失了,这是因为我们使用了 --nolog 模式,该模式屏蔽了日志打印。同时我们可以看到控制台打印了如下信息:
['Albert Einstein', 'J.K. Rowling', 'Albert Einstein', 'Jane Austen', 'Marilyn Monroe', 'Albert Einstein', 'André Gide', 'Thomas A. Edison', 'Eleanor Roosevelt', 'Steve Martin']
这就是我们想要的作者名字列表,说明我们提取数据成功了。
注意,如果我们爬取的网站是有 robot 协议的,我们需要在 settings.py 文件中找到如下代码,并设置为 False,默认值为 True:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
保存数据
作为一个爬虫,我们当然是希望将爬取的数据保存在一个对象中,而不是只是简单的打印输出到控制台。Scrapy 为我们提供了这样的机制,下面隆重请出我们的 Item 选手。
Scrapy 使用 Item 来存储爬取的内容,我们可以在 items.py 文件中定义我们的存储类:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
这里的 MyspiderItem 就是我们的存储类,这个名字我们可以自定义,name 是存储类的属性,定义方法都是用 scrapy.Field() 赋值。
定义完 Item 类之后,我们再回到 author.py 类中,我们需要将我们解析到的数据存到 Item 类中:
# -*- coding: utf-8 -*-
import scrapy
from mySpider.items import MyspiderItem
class AuthorSpider(scrapy.Spider):
name = 'author' # 爬虫名称
allowed_domains = ['quotes.toscrape.com'] # 允许爬的域名
start_urls = ['http://quotes.toscrape.com/'] # 起始 URL
# 解析方法
def parse(self, response):
# 解析页面获取作者
authors = response.xpath('/html/body/div/div/div/div/span/small/text()').extract()
print(authors)
# 存储数据
for author in authors:
item = MyspiderItem()
item['name'] = author
yield item
这里我们可以使用 return 来返回数据,也可以使用 yield 来返回。二者的区别是 return 是一次性返回数据,yield 是每处理一条返回一条。
我们再来运行一下命令:
scrapy crawl author --nolog
结果和上面一样,控制台打印出作者名字列表。这是因为我们只是存在内存中的 Item 中了。
下面我们再运行一下如下命令:
crawl author --nolog -o authors.json -t json
我们可以发现 mySpider 目录下多了一个 authors.json 的文件,打开文件可以看到:
[
{"name": "Albert Einstein"},
{"name": "J.K. Rowling"},
{"name": "Albert Einstein"},
{"name": "Jane Austen"},
{"name": "Marilyn Monroe"},
{"name": "Albert Einstein"},
{"name": "Andr\u00e9 Gide"},
{"name": "Thomas A. Edison"},
{"name": "Eleanor Roosevelt"},
{"name": "Steve Martin"}
]
我们将解析到的对象存储在文件中了。
我们再来看看运行的这个命令,与前面相比,多了 -o 和 -t 两个参数,其中前者指输出到文件,后面接文件名,后者指输出文件类型,后面接文件类型。在本例中,我们输出了一个名为 authors.json 类型为 json 的文件。
Scrapy 支持四种简单的保存方法:
输出json格式:
scrapy crawl author -o authors.json
输出 json lines格式,默认为Unicode编码:
scrapy crawl author -o authors.jsonl
输出 csv 格式:
scrapy crawl author -o authors.csv
xml格式
输出 xml 格式:
scrapy crawl author -o author.xml
总结
本文我们以爬虫的基本步骤为出发点,讲述了 Scrapy 使用的基本流程,这个只是一个最基本的流程,并没有提现 Scrapy 的强大之处,如果只是这个简单的需求,我们完全可以使用其他的爬虫方法解决。后续我们会慢慢深入讲述 Scrapy 框架,未完待续...