- 欢迎关注我的公众号
 公众号
公众号
1、SQL简介
SQL:Structured Query Language的缩写(结构化查询语言)是一种定义、操作、管理关系数据库的句法
-
结构化查询语言的工业标准由
ANSI(美国国家标准学会,ISO的成员之一)维护。- DQL:数据查询语言
- DML:数据操作语言
- DDL:数据定义语言
- DCL:数据控制语言
- TPL:事务处理语言
- CCL:指针控制语言
优点:最大的优点共享数据、安全性有很大的保障,但是也不是绝对的安全(黑客)、操作数据很容易
2、常用数据库
Oracle
DB2
Informix
Sybase
SQL Server
ProstgreSQL面向对象数据库
MySQL
Access
SQLite等
3、数据库服务器、数据库和表的关系
-
数据库服务器、数据库和表的关系如图
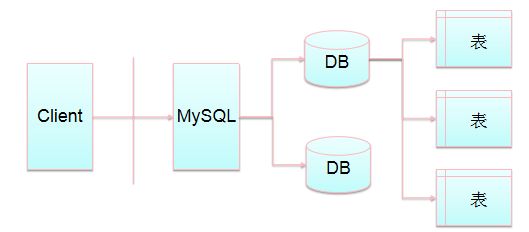 image.png
image.png
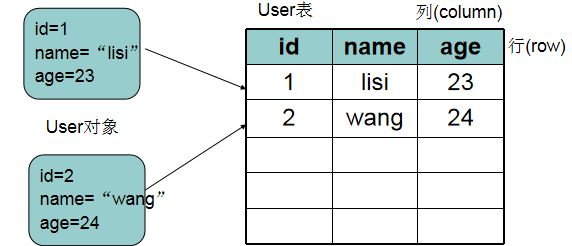
* 表的一行称之为一条记录,表中一条记录对应一个java对象的数据
4、DDL数据定义语言
数据库的操作
- 创建数据库 create database mydb ;
- 查看创建数据库的语句 show create database mydb ;
- 改变当前的数据库 use mydb ;
- 删除数据库 drop database mydb ;
- 查看所有的数据库 show databases ;
- 修改数据库mydb1的字符集为utf8
alter database mydb1 character set utf8; - 创建数据库mydb1,字符集用gbk
create database mydb1 character set gbk; - 查看数据库中所有的校对规则 show collation ;
- 查看中文的校验规则
show collation like '%gb%'; - 创建数据库mydb2,字符集用gbk,校验规则用
gbk_bincreate database mydb2 character set gbk collate gbk_bin;
针对表的操作
- 创建表t
create table t( id int , name varchar(30) ) ; - 查看创建表的源码
show create table t ; - 创建表t1,使用字符集gbk create table t1( id int , name varchar(30) )character set gbk ;
- 创建表t4
create table t4 ( id int , name varchar(30), optime timestamp ) ;
插入数据
- 设置客户端的字符集为gbk
set character_set_client=gbk; - 设置结果集的字符集为gbk
set character_set_results=gbk ; insert into t4(id,name) values(1,'张无忌') ; insert t4(id,name) values(2,'乔峰') ;into 可以省略 - 省略字段,意味着所有的字段都必须给值(自增例外)
insert t4 values(3,'杨过','2014-4-3') ;
更新
- 将表t4的第三条记录姓名字段改为杨康
update t4 set name='杨康' where id = 3 ; - 将所有记录的名字都改为东方不败
update t4 set name = '东方不败' ; - 修改多个字段
update t4 set id=6,name='萧峰' where id = 2 ;
删除
delete from t4 where id = 4 ;- 删除所有的记录
delete from t4 ; - 删除所有的记录
truncate table t4 ; - 给表t4增加一个字段address
alter table t4 add address varchar(100) ; - 删除字段address
alter table t4 drop column address ; - 查看表的结构
desc t4 ;
创建一个学生表
create table stu ( id int primary key, // 主键约束 name varchar(30) unique, // 唯一约束 sex char(2) not null, //非空约束 age int check (age > 0 and age < 100),// 检查约束 address varchar(50) default '北京' //默认约束 ) ;insert into stu values(1,'张无忌','男',20,'北京') ; insert into stu values(2,'小龙女','女',18,'古墓') ; insert into stu values(3,'黄蓉','女',15,'桃花岛') ; insert into stu values(4,'韦小宝','男',24,'扬州') ; insert into stu values(5,'乔峰','男',34,'雁门关') ; insert into stu values(6,'张果老','男',30,'雁门关') ; insert into stu values(7,'老张','男',38,'黒木崖') ; insert into stu values(8,'张','男',34,'桃花岛') ; insert into stu values(9,'韦小宝','女',24,'新东方') ; insert into stu(id,name,sex,age) values(10,'令狐冲','男',27) ;查看所有数据
select * from stu ;查看小龙女的信息 select * from stu where id = 2 ; select * from stu where name='小龙女' ;
查看年龄在20~30之间的人 select * from stu where age >=20 and age <=30 ; select * from stu where age between 20 and 30 ; # 包括20和30 #查看所有的的姓名 select name from stu ;
查看所有的的姓名,年龄,性别 select name,age,sex from stu ;
模糊查询
- select * from 表名 where 字段名 like 字段表达式 % 表示任意字符数 _ 表示任意的一个字符 [] 表示在某个区间
- 查询所有以张开头的人 select * from stu where name like '张%' ;
- 查询姓名中含有张这个字的人 select * from stu where name like '%张%' ;
- 查询姓名中含有张这个字的人并且姓名的长度是3个字的人
select * from stu where name like '张__' or name like '_张_' or name like '__张' ; - 查询表中有几种性别
select distinct sex from stu ; - 查找姓名和性别整体都不同的记录
select distinct name,sex from stu ;
创建新表分数表
create table score ( id int primary key, sid int , china int, english int , history int, constraint sid_FK foreign key(sid) references stu(id) ) ;
insert into score values(1,1,68,54,81) ;
insert into score values(2,3,89,98,90) ;
insert into score values(3,4,25,60,38) ;
insert into score values(4,6,70,75,59) ;
insert into score values(5,8,60,65,80) ;
- 字段可以有表达式
select id,china+10,english,history from score ; - 给字段起别名
select id as 编号,china as 语文,english as 英语,history as 历史 from score ; select id 编号,china 语文,english 英语,history 历史 from score ; - 查看所有人考试的总分是多少
select id,china + english + history 总分 from score ; - 查看总分大于200的人 select * from score where china + english + history > 200 ;
- 查询家在桃花岛或者黒木崖的人
select * from stu where address = '桃花岛' or address = '黒木崖' ;
select * from stu where address in('桃花岛','黒木崖') ; - 查询没有参加考试的人 select id ,name from stu where id not in(select sid from score) ;
- 查询没有地址的人 select * from stu where address = null ; #错误的
select * from stu where address is null ; - 查询有地址的人
select * from stu where address is not null ;
排序(order by )
对考试的人的语文升序
asc排列select * from score order by china asc;对考试的人的历史降序
desc排列select * from score order by history desc;根据多个字段进行排序(语文升序,对语文成绩一样的人再进行历史降序类排)
select * from score order by china asc,history desc;根据考试总分降序进行排序
select *,china + english + history 总分 from score order by china + english + history desc ;主键:唯一的去区分每一条记录的一列或者多列的值. 特点:唯一,非空
Order by指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的列名。
Asc升序、Desc降序
ORDER BY子句应位于SELECT语句的结尾。
创建引用约束
alter table score add constraint stu_score_FK foreign key(sid) references stu(id) ;
- 删除约束
alter table score drop foreign key stu_score_FK ; - 引用约束 注意:
-
- 添加记录时必须先添加主表中的记录,再添加字表中的记录
-
- 不能更改主表中具有外键约束的记录的主键
-
- 删除记录的时候不允许删除具有外键关系的主表中的记录(删除的顺序应当是先删除字表中的记录,然后删除主表中的记录)
-
自动增长 create table t5 ( id int primary key auto_increment, name varchar(20) ) ;
多表查询
交叉查询
-
查询每个人的考试成绩
select * from stu s cross join score c on s.id = c.sid;
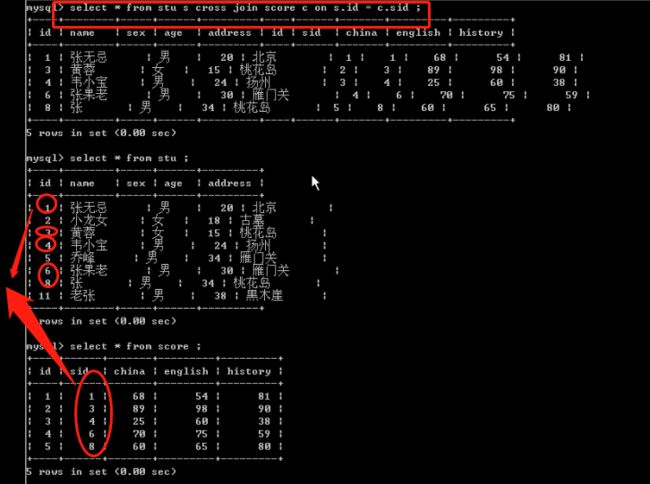 image.png
image.png 查询参加考试的人的成绩
select name,china,english,history,china+english+history 总分 from stu s inner join score c on s.id = c.sid ;查询所有人的成绩
select name,china,english,history,china+english+history 总分 from stu s left out join score c on s.id = c.sid ;查询没有参加考试的人
select * from stu where id not in(select sid from score) ;查询参加考试的人的成绩
select name,china,english,history,china+english+history 总分 from stu s,score c where s.id = c.sid ;-
聚合函数
sum max,min avg ,count
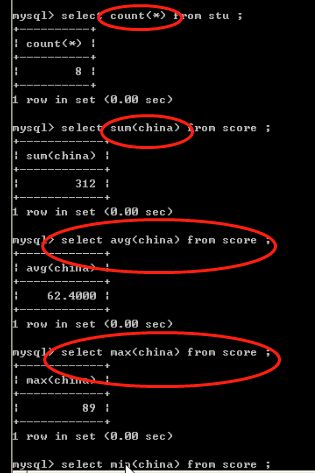 image.png
image.png 分组函数
select count(*) 数量,sex,name from stu group by sex,name ;根据多个字段进行分组
分组条件
select count(*),sex from stu where age >=16 group by sex having count(*) >1 ;
5、在where子句中经常使用的运算符
运算符
Like语句中,% 代表零个或多个任意字符,_ 代表一个字符,例first_name like ‘_a%’

6、数据完整性
- 数据完整性是为了保证插入到数据中的数据是正确的,它防止了用户可能的输入错误。
- 数据完整性主要分为以下三类:
- 实体完整性:
规定表的一行(即每一条记录)在表中是唯一的实体。实体完整性通过表的主键来实现。主键:唯一的去区分每一条记录的一列或者多列的值. 特点:唯一,非空 - 域完整性:
指数据库表的列(即字段)必须符合某种特定的数据类型或约束。比如NOT NULL。主键primary key唯一约束unique检查约束 MySQL不支持哦int check (age > 0 and age < 100)非空约束not nullcreate table stu ( id int primary key, // 主键约束 name varchar(30) unique, // 唯一约束 sex char(2) not null, //非空约束 age int check (age > 0 and age < 100),// 检查约束 address varchar(50) default '北京' //默认约束 ) ;
- 参照完整性:
保证一个表的外键和另一个表的主键对应。
- 实体完整性:
7、查询
-
连接查询
- 交叉连接(cross join):不带on子句,返回连接表中所有数据行的笛卡儿积。
- 内连接(inner join):返回连接表中符合连接条件及查询条件的数据行。
- 外连接:分为左外连接(left out join)、右外连接(right outer join)。与内连接不同的是,外连接不仅返回连接表中符合连接条件及查询条件的数据行,也返回左表(左外连接时)或右表(右外连接时)中仅符合查询条件但不符合连接条件的数据行。
-
子查询
- 子查询也叫嵌套查询,是指在select子句或者where子句中又嵌入select查询语句 查询“陈冠希”的所有订单信息
SELECT * FROM orders WHERE customer_id=(SELECT id FROM customer WHERE name LIKE '%陈冠希%');
- 子查询也叫嵌套查询,是指在select子句或者where子句中又嵌入select查询语句 查询“陈冠希”的所有订单信息
-
联合查询
- 联合查询能够合并两条查询语句的查询结果,去掉其中的重复数据行,然后返回没有重复数据行的查询结果。联合查询使用union关键字
SELECT * FROM orders WHERE price>200 UNION SELECT * FROM orders WHERE customer_id=1;
- 联合查询能够合并两条查询语句的查询结果,去掉其中的重复数据行,然后返回没有重复数据行的查询结果。联合查询使用union关键字
-
报表查询
- 报表查询对数据行进行分组统计,其语法格式为:
[select …] from … [where…] [ group by … [having… ]] [ order by … ]
其中group by 子句指定按照哪些字段分组,having子句设定分组查询条件。在报表查询中可以使用SQL函数。
- 报表查询对数据行进行分组统计,其语法格式为:
8、 MySQL常用数据类型
-
数值类型
BIT(M) 位类型。M指定位数,默认值1,范围1-64
TINYINT [UNSIGNED] [ZEROFILL] 带符号的范围是-128到127。无符号0到255。
BOOL,BOOLEAN 使用0或1表示真或假
SMALLINT [UNSIGNED] [ZEROFILL] 2的16次方
INT [UNSIGNED] [ZEROFILL] 2的32次方
BIGINT [UNSIGNED] [ZEROFILL] 2的64次方
FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] M指定显示长度,d指定小数位数
DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 表示比float精度更大的小数
-
文本、二进制类型
- CHAR(size) char(20) 固定长度字符串
- VARCHAR(size) varchar(20)可变长度字符串(但是不可以超过255, 但是在Oracle中是4000)
- BLOB LONGBLOB 二进制数据( 用在音频或者是视屏)
- TEXT(clob) LONGTEXT(longclob)大文本(小说)
-
时间日期
- DATE/DATETIME/TimeStamp
- 日期类型(YYYY-MM-DD) (YYYY-MM-DD HH:MM:SS),TimeStamp表 示时间戳,它可用于自动记录insert、update操作的时间
9、 相关函数
-
时间日期相关函数
 image.png
image.png
select addtime(‘02:30:30’,‘01:01:01’);注意:字符串、时间日期的引号问题
select date_add(entry_date,INTERVAL 2 year) from student;//增加两年
select addtime(time,‘1 1-1 10:09:09’) from student;//时间戳上增加,注意年后没有 -
字符串相关函数
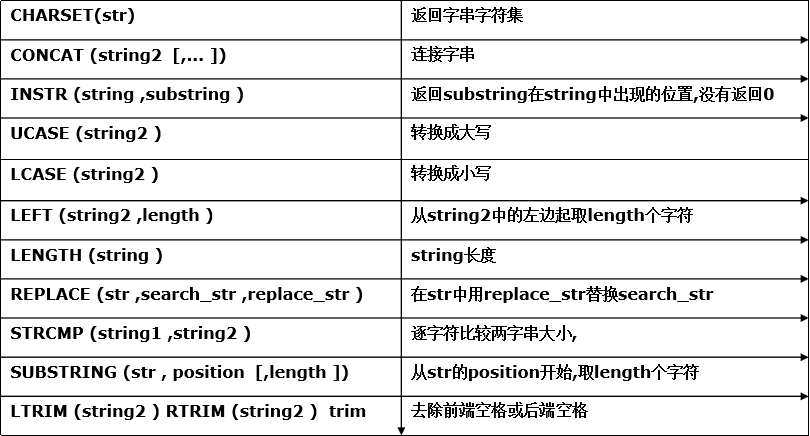 image.png
image.png -
数学相关函数
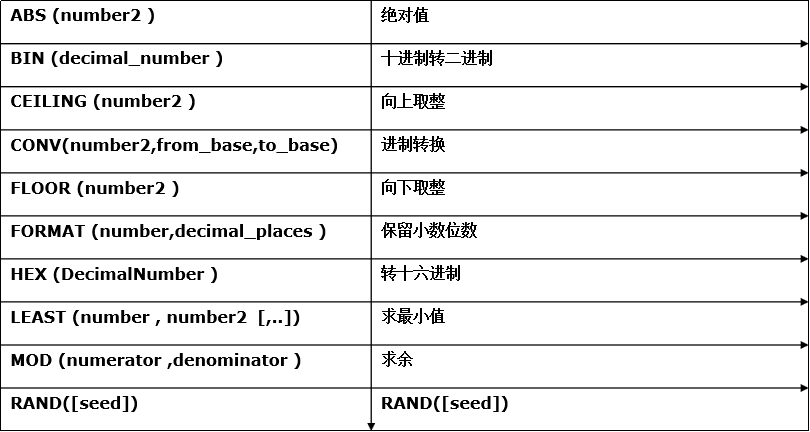 image.png
image.png
- 数据库备份:
mysqldump -u root -psorry test>D:\test.sql - 数据库恢复:
- 创建数据库并选择该数据库
- SOURCE 数据库文件
- 或者:
mysql -u root -psorry test