scrapy框架简介
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
scrapy架构图
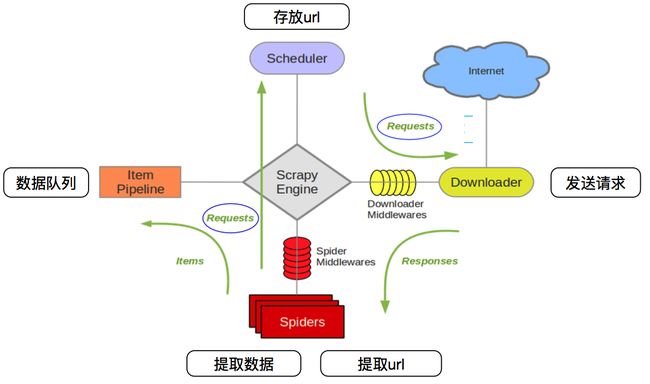
crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
-
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
 b96.png
b96.png
新建scrapy项目
1、创建爬虫项目,命令:scrapy startproject 项目名称
2、创建爬虫文件,命令:scrapy genspider 文件名称 域名
创建完成后会自动生成一些文件
目标网站分析需要提取的数据,在item.py文件中添加字段
Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误
在爬虫文件中会,默认生成下列代码
import scrapy
class TestSpider(scrapy.Spider):
# 爬虫名称
name = 'test'
# 设置允许爬取的域(可以指定多个)
allowed_domains = ['baidu.com']
# 设置起始url(设置多个)
start_urls = ['http://baidu.com/']
def parse(self, response):
'''
是一个回调方法,起始url请求成功后,会回调这个方法
:param response: 响应结果
:return:
'''
pass
在parse方法中做数据的提取
def parse(self, response):
'''
在parse回调方法中
step1;提取目标数据
step2;获取新的url
:param response: 请求的响应结果
:return:
'''
print(response.status)
#response.xpath(): 使用xpath语法,得到的是selectorlist对象
# response.css(): 使用css选择器,得到的是selectorlist对象
# extract(): 将selector 序列化为unicode字符串
# step1;提取目标数据
# 获取分类列表
tags = response.xpath('//div[@class="Taright"]/a')
# tags = response.css('.Taright a')
for tag in tags:
# 实例化一个item,用来存储数据
tag_item = ChinazspidertagItem()
# 获取网站分类的名称
# tagname = tag.xpath('./text()')[0].extract()
tagname = tag.xpath('./text()').extract_first('')
tag_item['tagname'] = tagname
# 使用css取值(文本)
# tagname = tag.css('::text').extract_first('')
# 获取网站分类的首页url地址
# first_url = tag.xpath('./@href')[0].extract()
first_url = tag.xpath('./@href').extract_first('')
tag_item['firsturl'] = first_url
# css取值(属性)
# first_url = tag.css('::attr(href)').extract_first('')
print(tag_item)
# print(type(tagname),type(first_url))
# print(tagname,first_url)
# 将获取到的数据交给管道处理
yield tag_item
# http://top.chinaz.com/hangye/index_yule_yinyue.html
# http://top.chinaz.com/hangye/index_yule_yinyue_2.html
'''
url,设置需要发起请求的url地址
callback=None,设置请求成功后的回调方法
method='GET',请求方式,默认为get请求
headers=None,设置请求头,字典类型
cookies=None,设置cookies信息,模拟登录用户,字典类型
meta=None,传递参数(字典类型)
encoding='utf-8',设置编码
dont_filter=False, 是否去重,默认为false,表示去重
errback=None, 设置请求失败后的回调
'''
yield scrapy.Request(first_url,callback=self.parse_tags_page)
关于yeild函数介绍
简单地讲,yield 的作用就是把一个函数变成一个 generator(生成器),带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,带有yeild的函数遇到yeild的时候就返回一个迭代值,下次迭代时, 代码从 yield 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行, 直到再次遇到 yield。
通俗的讲就是:在一个函数中,程序执行到yield语句的时候,程序暂停,返回yield后面表达式的值,在下一次调用的时候,从yield语句暂停的地方继续执行,如此循环,直到函数执行完。
Item pipeline(管道文件)使用
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
验证爬取的数据(检查item包含某些字段,比如说name字段)
查重(并丢弃)
将爬取结果保存到文件或者数据库中
item pipiline组件是一个独立的Python类,其中process_item()方法必须实现:
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
# doing something
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
- 启用一个Item Pipeline组件 为了启用Item Pipeline组件,必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置,就像下面这个例子:
ITEM_PIPELINES = {
#'mySpider.pipelines.SomePipeline': 300,
"mySpider.pipelines.JobboleprojectPipeline":300
}
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内(0-1000随意设置,数值越低,组件的优先级越高)
定制图片下载管道
在settings.py中设置 IMAGES_STORE 设置为一个有效的文件夹,用来存储下载的图片
IMAGES_STORE = '/xxx/xxx/xxx'
import pymysql, scrapy,os,pymongo
from scrapy.contrib.pipeline.images import ImagesPipeline
from chinazspider.items import ChinazprojectWebInfoItem,ChinazspidertagItem
from scrapy.utils.project import get_project_settings
#os.rename()
# 获取settimgs.py文件中的设置信息
images_store = get_project_settings().get('IMAGES_STORE')
class Chinazprojectimagepipeline(ImagesPipeline):
# 实现两个方法
def get_media_requests(self, item, info):
'''
根据图片的url地址,构造requset请求
:param item:
:param info:
:return:
'''
# 判断item来自哪个模块
if isinstance(item, ChinazprojectWebInfoItem):
# 获取图片地址
image_url = 'http:' + item['coverimage']
print('获取图片地址', image_url)
yield scrapy.Request(image_url)
# 如果有多个图片地址
# image_urls = 'http:' + item['coverimage']
# return [scrapy.Request(x) for x in image_urls]
#
def item_completed(self, results, item, info):
'''
图片下载之后的回调方法
:param results: [(True/False,{'path':'图片下载之后的存储路径','url':'图片url地址','ckecksum':'hash加密的一个字符串'})]
:param item:
:param info:
:return:
'''
if isinstance(item, ChinazprojectWebInfoItem):
paths = [result['path'] for status, result in results if status]
print('图片下载结果', results)
if len(paths) > 0:
print('图片下载成功')
# 使用rename方法修改图片名称
os.rename(images_store+'/'+paths[0],images_store+'/'+item['title']+'.jpg')
image_path = images_store+'/'+item['title']+'.jpg'
print('修改之后图片路径:',image_path)
item['localimagepath'] = image_path
else:
# 如果没有成功获取到图片,将这个item丢弃
from scrapy.exceptions import DropItem
raise DropItem('没有获取到图片,遗弃item')
return item
爬虫数据持久化
方式一:将数据存入mongodb
settings.py文件: 设置文件,在这里设置User-Agent,激活管道文件等...
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
MONGODB 主机名
MONGODB_HOST = '127.0.0.1'
MONGODB 端口号
MONGODB_PORT= 27017
数据库名称
MONGODB_DBNAME = "Douban"
存储数据的表名称
MONGODB_SHEETNAME= "doubanmovies"
往mongodb数据库中插入数据
class Chinazprojectpipeline(object):
def __init__(self):
# 创建mongodb的数据库连接
mongo_client = pymongo.MongoClient(
host='127.0.0.1',port=27017
)
# 获取要操作的数据库
self.db = mongo_client['chinaz']
@classmethod
def from_crawler(cls,crawler):
MONGO_HOST = '127.0.0.1'
MONGO_PORT = 27017
MONGO_DB = 'chinaz'
def process_item(self, item, spider):
'''
:param item:
:param spider:
:return:
'''
# 往哪个集合下插入数据
col_name = item.get_mongodb_collectionname()
col = self.db[col_name]
# 往集合下插入什么数据
dict_data = dict(item)
try:
col.insert(dict_data)
print('数据插入成功')
except Exception as err:
print('插入数据失败',err)
def close_spider(self,spider):
self.mongo_client.close()
print(spider.name,'爬虫结束了')
方式二:将数据存入mysql数据库
settings.py文件: 设置文件,在这里设置User-Agent,激活管道文件等...
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
关于数据库的相关配置
MYSQL_HOST = '127.0.0.1'
MYSQL_PORT = 3306
MYSQL_USER = ''
MYSQL_PWD = ''
MYSQL_DB = ''
pipelines.py管道文件
往数据库里插数据
class ChinazspiderPipeline(object):
def __init__(self):
'''
初始化方法
'''
# self.file = open('chinaz.json','a')
# 创建数据库链接
self.client = pymysql.Connect(
'127.0.0.1', 'root', 'czj1234',
'chinaz', 3306, charset='utf8'
)
# 创建游标
self.cursor = self.client.cursor()
def open_spider(self, spider):
'''
爬虫启动的时候回调用一次
:param spider:
:return:
'''
print('爬虫开启')
pass
def process_item(self, item, spider):
'''
这个方法必须实现,爬虫文件中所有的item 都会经过这个方法
:param item: 爬虫文件传递过来的item对象
:param spider: 爬虫文件实例化的对象
:return:
'''
# 存储到本地json文件
data_dict = dict(item)
# import json
# json_data = json.dumps(data_dict,ensure_ascii=False)
# self.file.write(json_data+'\n')
# 使用isisinstance判断item要存储的表
# if isinstance(item,ChinazprojectWebInfoItem):
# print('网站信息')
# tablename = 'webinfo'
# elif isinstance(item,ChinazspidertagItem):
# print('网站分类信息')
# tablename = 'tags'
# #
# # 往数据库里写
# sql = """
# insert into %s(%s)
# values (%s)
# """ % (tablename,','.join(data_dict.keys()), ','.join(['%s'] * len(data_dict)))
sql,data = item.get_insert_sql_data(data_dict)
try:
self.cursor.execute(sql, list(data_dict.values()))
self.client.commit()
except Exception as err:
self.client.rollback()
print(err)
# 如果有多个管道文件,一定要return item , 否则下一管道无法接收到item
print('经过了管道')
return item
def close_spider(self, spider):
'''
爬虫结束的时候调用一次
:param spider:
:return:
'''
# self.file.close()
self.client.close()
self.cursor.close()
print('爬虫结束')
异步插入数据库
import pymysql
twisted是一个异步的网络框架,这里可以帮助我们
实现异步将数据插入数据库
adbapi里面的子线程会去执行数据库的阻塞操作,
当一个线程执行完毕之后,同时,原始线程能继续
进行正常的工作,服务其他请求。
from twisted.enterprise import adbapi
#异步插入数据库
class DoubanPipeline(object):
def __init__(self,dbpool):
self.dbpool = dbpool
#使用这个函数来应用settings配置文件。
@classmethod
def from_crawler(cls, crawler):
parmas = {
'host':crawler.settings['MYSQL_HOST'],
'user':crawler.settings['MYSQL_USER'],
'passwd':crawler.settings['MYSQL_PASSWD'],
'db':crawler.settings['MYSQL_DB'],
'port':3306,
'charset':'utf8',
}
# **表示字典,*tuple元组,
# 使用ConnectionPool,起始最后返回的是一个ThreadPool
dbpool = adbapi.ConnectionPool(
'pymysql',
**parmas
)
return cls(dbpool)
def process_item(self, item, spider):
#这里去调用任务分配的方法
query = self.dbpool.runInteraction(
self.insert_data_todb,
item,
spider
)
#数据插入失败的回调
query.addErrback(
self.handle_error,
item
)
#执行数据插入的函数
def insert_data_todb(self,cursor,item,spider):
insert_str,parmas = item.insertdata()
cursor.execute(insert_str,parmas)
print('插入成功')
def handle_error(self,failure,item):
print(failure)
print('插入错误')
#在这里执行你想要的操作
def close_spider(self, spider):
self.pool.close()
通用爬虫
- CrawlSpider它是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则Rule来提供跟进链接的方便的机制,从爬取的网页结果中获取链接并继续爬取的工作
- 创建通用爬虫文件命令: scrapy genspider -t crawl 爬虫文件 域名
例:chinaz
class ChinazSpider(CrawlSpider):
# 爬虫名称
name = 'chinaz'
# 设置允许爬取的域
allowed_domains = ['chinaz.com']
# 设置起始url
start_urls = ['http://top.chinaz.com/hangyemap.html']
# rules:存放定制的规则获取连接的规则对象(可以是一个列表也可以是一个元组)
# 根据规则提取到的所有链接,都会由crawlspider 构建request对象并且交给引擎处理
'''
LinkExtractor:设置提取链接的规则(正则表达式)
allow=(), : 设置允许提取的目标url
deny=(), : 设置不允许提取的目标url(优先级比allow高)
allow_domains=(), :设置允许提取url的域
deny_domains=(), : 设置不允许提取url的域(优先级比allow_domains高)
restrict_xpaths=(),:根据xpath语法,定位到某一标签下提取链接
restrict_css=(),:根据css选择器,定位到某一标签下提取链接
unique=True, :如果出现多个相同的url,只会保留一个
strip=True:默认为true,表示去除url首尾空格
'''
'''
link_extractor,:link_extractor对象
callback=None, :设置回调函数
follow=None, :是否设置跟进
process_links=None, :可以设置回调函数,对所有提取到的url进行拦截
process_request=identity:可以设置回调函数,对request对象进行拦截
'''
#http://top.chinaz.com/hangye/index_yule_yinyue.html
#http://top.chinaz.com/hangye/index_shopping_dianshang.html
rules = (
# 规则对象
Rule(LinkExtractor
(allow=r'http://top.chinaz.com/hangye/index_.*?html',
restrict_xpaths=('//div[@class="Taright"]','//div[@class="ListPageWrap"]')),
callback='parse_item',
follow=True),
)