Hive:
分区表有哪几类
Hive中追加导入数据的4种方式是什么?
Hive中到处数据有几种方式?如何导出数据
Canal
Canal通过配置就可以把数据传到Kafka,如何配置?不用写代码
Canal对了数据怎么办
数据库
表的权限管理
数仓
日活、周活、月活比例
Java & Scala
JVM运行时数据区
JVM的GC机制
JVM调优
Scala于Java语言相比较,有什么优势?
Spark
Spark的Shuffle于MR Shuffle有何区别
Spark程序的定时开启与关闭
实时
SparkStreaming
Flink
watermark
状态一致性
状态计算
事务写入(Transactional Writes)
事务(Transaction)
- 应用程序中一系列严密的操作,所有操作必须成功完成;否则在每个操作中所作的所有更改都会被撤消
- 具有原子性:一个事务中的一系列的操作要么全部成功,要么一个都不做
实现思想
构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中
面试题:
1 Flink-Kafka端对端的状态一致性问题,如何保持
2 Kafka的事务性配置参考
Atlas
官网链接:http://atlas.apache.org/0.8.4/QuickStart.html
Atlas是什么?
Apache Atlas为组织提供开放式元数据管理和治理功能,用以构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队,提供围绕这些数据资产的协作功能。
架构原理图
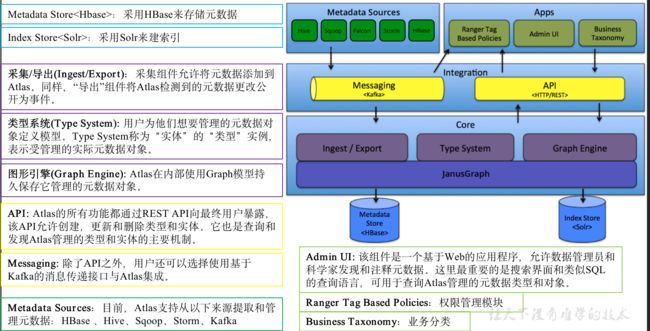
Atlas的工作流程?哪一块都提供了什么功能?
管理的元数据类型有哪些?
当需求不能被满足时:官网提供源代码,支持二次开发(提供REST AP,所有功能都会向用户提供)
安装及使用
安装环境准备:
JDK8、Hadoop、Zookeeper、Kafka、HBase、Solr、Hive、
Azkaban(进行工作调度后,查看表、字段之间的血缘依赖关系)、
Atlas0.8.4
在/opt/module/atlas/路径,将Hive元数据导入到Atlas
Oozie介绍
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。我们会使用hPDL(一种XML流程定义语言)来描述这个图。
hPDL是一种很简洁的语言,只会使用少数流程控制和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是一些机制,通过它们工作流会触发执行计算或者处理
Oozie和Azkaban的区别:
两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
工作流定义:Oozie是通过xml定义的而Azkaban为properties来定义。
部署过程:Oozie的部署相对困难些,同时它是从Yarn上拉任务日志。
Azkaban中如果有任务出现失败,只要进程有效执行,那么任务就算执行成功,这是BUG,但是Oozie能有效的检测任务的成功与失败。
操作工作流:Azkaban使用Web操作。Oozie支持Web,RestApi,Java API操作。
权限控制:Oozie基本无权限控制,Azkaban有较完善的权限控制,供用户对工作流读写执行操作。
Oozie的action主要运行在hadoop中而Azkaban的actions运行在Azkaban的服务器中。
记录workflow的状态:Azkaban将正在执行的workflow状态保存在内存中,Oozie将其保存在Mysql中。
出现失败的情况:Azkaban会丢失所有的工作流,但是Oozie可以在继续失败的工作流运行
调度工具性能对比:
Apache Oozie,其配置工作流的过程是编写大量的XML配置,而且代码复杂度比较高,不易于二次开发。ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。
如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。
Azkaban和Oozie的具体调度
Azkaban的工作流的创建特别方便,直接通过web界面创建工程,然后提交任务。(创建job的的文件必须是以.job的文件,并且上传的文件是以zip压缩包的形式进行上传)。
在hue当中操作ooize的操作:
Hue是一个可快速开发和调试Hadoop生态系统各种应用的一个基于浏览器的图形化用户接口。
Hue可实现对oozie任务的开发,监控,和工作流协调调度 。使的oozie的操作变得更加的简单快捷。
参考链接:
https://www.cnblogs.com/gxgd/p/8671271.html ----主要介绍了两者的区别
https://blog.csdn.net/bingdianone/article/details/87908146#Azkaban_267 --详细的介绍了常见配置使用
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。 它有如下功能特点: 1.Web用户界面 2.方便上传工作流 3.方便设置任务之间的关系 4.调度工作流 5.认证/授权(权限的工作) 6.能够杀死并重新启动工作流 7.模块化和可插拔的插件机制 8.项目工作区 9.工作流和任务的日志记录和审计
Azkaban介绍
调度工具介绍:(azkaban 和oozie)
各任务单元之间存在时间先后及前后依赖关系。为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行
shell脚本程序
java程序
mapreduce程序
hive脚本等
工作流调度:一个完整的数据分析系统通常都是由大量任务单元组成:
工作流调度工具:(azkaban 和oozie的对比)
实际运行: 实际上,最优的解决方案应该是最符合实际设计需求的方案,在时间应用中,可能有足够大的内存,那么直接将数据扔到内存中一次性处理即可,也可能机器有多个核,这样可以采用多线程处理整个数据集。
第五种方法采用最小堆。首先读入前10000个数来创建大小为10000的最小堆,建堆的时间复杂度为O(mlogm)(m为数组的大小即为10000),然后遍历后续的数字,并于堆顶(最小)数字进行比较。如果比最小的数小,则继续读取后续数字;如果比堆顶数字大,则替换堆顶元素并重新调整堆为最小堆。整个过程直至1亿个数全部遍历完为止。然后按照中序遍历的方式输出当前堆中的所有10000个数字。该算法的时间复杂度为O(nmlogm),空间复杂度是10000(常数)。
第四种方法是Hash法。如果这1亿个书里面有很多重复的数,先通过Hash法,把这1亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,然后通过分治法或最小堆法查找最大的10000个数。
第三种方法是分治法,将1亿个数据分成100份,每份100万个数据,找到每份数据中最大的10000个,最后在剩下的10010000个数据里面找出最大的10000个。如果100万数据选择足够理想,那么可以过滤掉1亿数据里面99%的数据。100万个数据里面查找最大的10000个数据的方法如下:用快速排序的方法,将数据分为2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大堆个数N小于10000个,就在小的那堆里面快速排序一次,找第10000-n大的数字;递归以上过程,就可以找到第1w大的数。参考上面的找出第1w大数字,就可以类似的方法找到前10000大数字了。此种方法需要每次的内存空间为10^64=4MB,一共需要101次这样的比较。
第二种方法为局部淘汰法,该方法与排序方法类似,用一个容器保存前10000个数,然后将剩余的所有数字——与容器内的最小数字相比,如果所有后续的元素都比容器内的10000个数还小,那么容器内这个10000个数就是最大10000个数。如果某一后续元素比容器内最小数字大,则删掉容器内最小元素,并将该元素插入容器,最后遍历完这1亿个数,得到的结果容器中保存的数即为最终结果了。此时的时间复杂度为O(n+m^2),其中m为容器的大小,即10000。
最容易想到的方法是将数据全部排序,然后在排序后的集合中进行查找,最快的排序算法的时间复杂度一般为O(nlogn),如快速排序。但是在32位的机器上,每个float类型占4个字节,1亿个浮点数就要占用400MB的存储空间,对于一些可用内存小于400M的计算机而言,很显然是不能一次将全部数据读入内存进行排序的。其实即使内存能够满足要求(我机器内存都是8GB),该方法也并不高效,因为题目的目的是寻找出最大的10000个数即可,而排序却是将所有的元素都排序了,做了很多的无用功。
有1亿个浮点数,如果找出期中最大的10000个?
针对top K类问题,通常比较好的方案是分治+Trie树/hash+小顶堆。即先将数据集按照Hash方法分解成多个小数据集,然后使用Trie树活着Hash统计每个小数据集中的query词频,之后用小顶堆求出每个数据集中出现频率最高的前K个数,最后在所有top K中求出最终的top K。
在大规模数据处理中,经常会遇到的一类问题:在海量数据中找出出现频率最好的前k个数,或者从海量数据中找出最大的前k个数,这类问题通常被称为top K问题。例如,在搜索引擎中,统计搜索最热门的10个查询词;在歌曲库中统计下载最高的前10首歌等。
1亿条数据,10M内存,求TopN
怎么解决
Kafka中
Spark中
Hive中
数据倾斜
经典场景问题
如何配置定时的工作流调度任务和邮件通知
使用过什么ETL清洗工具?
集群
Web界面的端口号:21000