
文本情感分析
文本情感分析(也称为意见挖掘)是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。
通常来说,情感分析的目的是为了找出说话者/作者在某些话题上或者针对一个文本两极的观点的态度。这个态度或许是他或她的个人判断或是评估,也许是他当时的情感状态(就是说,作者在做出这个言论时的情绪状态),或是作者有意向的情感交流(就是作者想要读者所体验的情绪)。
书籍评论数据
我们将使用从豆瓣网收集的《解忧杂货店》书籍相关评论数据,书籍整体评分在8.5分,大多数都是4星或者5星。选取该书籍的原因主要在于收集足够的样本进行建模,考虑该书籍是东野圭吾的热门小说,主页显示接近40w的评价,短评约13w,初略估计每个星类别都有几千的评论。当然这本书的内容也是挺不错的,有兴趣的读者可以去看看哦。。
收集的数据包含文本评论和对应的星级评分,文本评论用来做情感分类的输入数据,豆瓣评分用来表示该评论是“正面”还是“负面”。豆瓣的评分包含1~5星的打分,为了简化建模过程,我们将评论打分处理成二分类,评分1分和2分的评论标记为“负面”,评分4分和5分的评论标记为“正面”,3分归类为中性评论,所以不包含在数据集中。这里就不讨论3分不包含数据集中的处理方式,有兴趣的读者可以看看3分的相关评论。


加载数据集
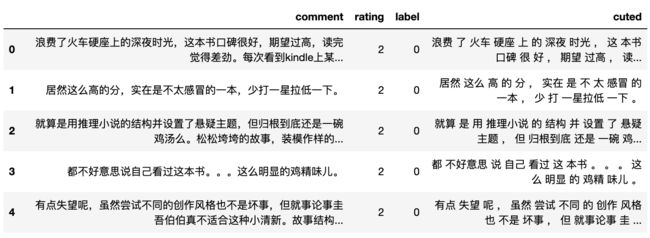
使用Pandas可以很方便的读取评论数据,我们用Jupyter notebook来执行代码,方便我们查看数据情况。加载数据集后查看前五条数据,对于中文文本有时候会出现编码问题,确认目前数据没有发生该问题。
import pandas as pd
# 读取评论数据集
df = pd.read_excel('data/comment.xlsx')
df.head()

数据探索
接下来我们查看整个数据集的记录数以及每个评分的记录数。总共有4352条评论,其中一半为1分或2分,一半为4分或5分。原始数据中绝大部分评论数据的评分都是4分或5分,为了防止训练模型的时候因数据集分类数量差异导致模型“记忆”更多的“正面”评论,经过处理使得目前使用的数据集二分类各占一半。
## 查看数据形状
print(df.shape)
# 查看分数分布
print(df['rating'].value_counts())
(4352, 2)
2 1735
5 1250
4 926
1 441
最后,检查数据集有无缺失值,遍历后所有列均没有缺失值。
# 查看有无空值
for col in df.columns:
print(col, ':', len(df[df[col].isnull()]))
id : 0
comment : 0
rating : 0
数据预处理
由于这是一个二分类问题,我们需要将评分转化为只含两种标签的数据。rating列大于3的标记为1,其余标记为0,并指定新的label列。
df['label'] = df['rating'].map(lambda x: 1 if x > 3 else 0)
中文分词
用于机器学习文本最简单且最常用的方法是使用词袋(bag-of-words)表示。为了表示词袋需要将评论分成一个个单词,并计算每个单词在评论中出现的频次。这种表示方法有个缺点,即舍弃了文本中的大部分结构,段落、句子、格式。英文每个单词都用空格隔开比较好处理,对于中文句子我们需要使用分词库将句子分割成单词,不同分词库具体案例可以看我之前写过的文章《Python中文分词及词频统计》。
这里我们使用jieba分词库进行快速分词,由于可能有全数字的文本评论会导致文本分词报错,这里先进行类型转换。
import jieba
# jieba分词
df['comment'] = df['comment'].map(str)
df['cuted'] = df['comment'].map(lambda x: ' '.join(jieba.cut(x)))
训练集和测试集
为了验证数据准确率,对于文本数据同样需要进行划分数据集。大写X表示输入,小写y表示输出。sklearn机器学习库的train_test_split可以很方便进行划分数据集,默认25%做为测试集,random_state指定随机种子保证每次划分的结果是一致的。
# 输入和输出
X = df['cuted']
y = df['label']
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 查看训练集
X_train.shape
CountVectorizer类可以实现文本的词袋表示,实例化对象后进行拟合,vocabulary_属性可以看到词表,每个单词对应的索引,不是频次。从打印的信息可以看到我们总共有7349个单词。
from sklearn.feature_extraction.text import CountVectorizer
# 变换器
vect = CountVectorizer()
vect.fit(X_train)
# 词表数量
print(len(vect.vocabulary_))
# 打印词表
print(vect.vocabulary_)

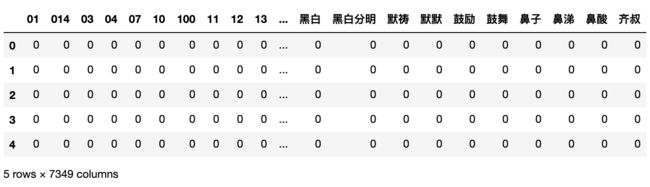
我们可以调用transform方法来创建词袋的稀疏矩阵,矩阵中每个特征对应词表中的单词,如果没有这个单词会用0进行填充。
words_matrix = pd.DataFrame(vect.transform(X).toarray(),
columns=vect.get_feature_names())
words_matrix.head()
构建模型
在提取特征后,我们通过构建LogisticRegression逻辑回归分类器来拟合训练集数据,并使用交叉验证对LogisticRegression进行评估模型的性能。我们的得到的交叉验证分数是81.9%,这对于二分类模型来说还是比较合理的。通常在这种多维特征的数据进行拟合分类逻辑回归都有不错的效果。
iimport numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# 交叉验证评估模型
scores = cross_val_score(LogisticRegression(),
vect.transform(X_train), y_train, cv=5)
print('平均交叉验证准确率:{:.3f}'.format(np.mean(scores)))
平均交叉验证准确率: 0.819
去除停用词
回过头看我们会发现单词特征中包含很多数字及其他如“的”、“哦”等单词,这些单词在大多数情况下对于我们目前的案例没有提供有效的信息量,所以需要从原来的词袋中删除掉以提高模型的性能,对于这些特定词我们称之为停用词。这里使用哈工大的停用词表,创建函数读取词表并删除换行符,输出停用词列表。
def stopwords_list():
with open('哈工大停用词表.txt') as f:
lines = f.readlines()
result = [i.strip('\n') for i in lines]
return result
stopwords = stopwords_list()
重新构建单词矩阵,max_df参数表示舍弃最频繁的单词,min_df参数表示每个词必须要在3个评论中出现,stop_words参数对于中文需要指定停用词列表,最后使用正则表达式去掉所有数字,处理完后可以看到单词由7349个减少到1931个。
vect = CountVectorizer(max_df=0.8, min_df=3, stop_words=stopwords,
token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b')
vect.fit(X_train)
words_matrix = pd.DataFrame(vect.transform(X_train).toarray(),
columns=vect.get_feature_names())

再次评估新的词袋模型,似乎准确率上没有提升,这是对于几千样本的数据。在几万样本的情况下,通常单词特征会有几万个,这个时候采用去除停用词是可以明显降低数据中的噪声,提高模型的准确率。不过这里不要担心我们继续优化。
# 训练模型
lr.fit(vect.transform(X_train), y_train)
print('测试集准确率:{:.3f}'.format(lr.score(vect.transform(X_test), y_test)))
测试集准确率:0.812
用tf-idf缩放数据
tf-idf 是一种用于资讯检索与文本挖掘的常用加权技术。tf-idf 是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随著它在文件中出现的次数成正比增加,但同时会随著它在语料库中出现的频率成反比下降。tf-idf 加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了 tf-idf 以外,互联网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
scikit-learn 在两个类中实现了 tf-idf 方法:TfidfTransformer 和 TfidfVectorizer, 前者接受 CountVectorizer 生成的稀疏矩阵并将其变换, 后者接受文本 数据并完成词袋特征提取与 tf-idf 变换。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(TfidfVectorizer(min_df=3), LogisticRegression())
pipe.fit(X_train, y_train)
scores = cross_val_score(pipe, X_train, y_train, cv=5)
print('平均交叉验证准确率:{:.3f}'.format(np.mean(scores)))
平均交叉验证准确率:0.828
我们可以看到使用 tf-idf 代替仅统计词数对性能有所提高。我们还可以查看 tf-idf 找到的最重要的单词。tf-idf较低的词要么在评论中经常出现,要么就是很少出现,tf-idf较大的词往往在评论中经常出现。
vectorizer = pipe.named_steps['tfidfvectorizer']
# 找到每个特征中最大值
max_value = vectorizer.transform(X_train).max(axis=0).toarray().ravel()
sorted_by_tfidf = max_value.argsort()
# 获取特征名称
feature_names = np.array(vectorizer.get_feature_names())
print("tfidf较低的特征:\n{}".format(feature_names[sorted_by_tfidf[:20]]))
print()
print("tfidf较高的特征:\n{}".format( feature_names[sorted_by_tfidf[-20:]]))

评估模型
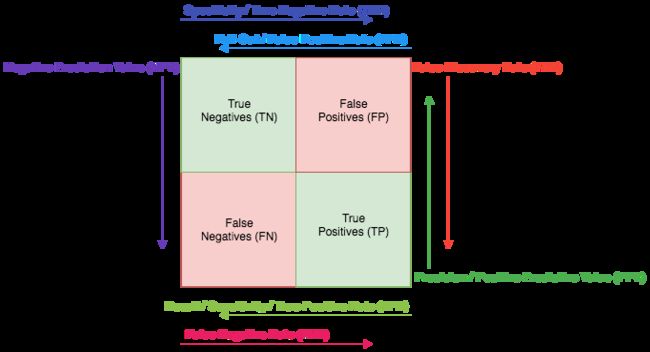
最后我们在使用测试集验证模型的准确率,可以看到模型最终在测试集上有81.4%的准确率,前面做的交叉验证仅仅只是在训练集上。另外,模型混淆矩阵上看到模型在负类上的准确率为448 / (448 + 99) = 0.81.9,正类上的准确率为438 / (438 + 103) = 0.81。
from sklearn import metrics
# 预测值
y_pred = pipe.predict(X_test)
print('测试集准确率:{:.3f}'.format(metrics.accuracy_score(y_test, y_pred)))
print('测试集准确率:{:.3f}'.format(pipe.score(X_test, y_test)))
metrics.confusion_matrix(y_test, y_pred)
测试集准确率:0.814
测试集准确率:0.814
array([[448, 103], [ 99, 438]])
豆瓣评分的思考
前段时间“流浪地球”电影刷分的事件闹得沸沸扬扬,那些高分改评论的内容实际上可以使用机器学习进行修正,即如果发现评论内容判定为正面情感,而评分给出1分或2分则表示该评论与评分很可能不相符,针对这种数据可以对该评论的星级评分进行降权,权重可以根据评分的人数进行调整。当然使用简单的机器学习系统还是要依靠大量的样本数据、合理的模型以及合理的参数,80%的准确率相当于有可能20%的误判。当然我们还有其他技巧可以再次提高我们模型的准确率,例如使用预训练好的词嵌入向量和使用更加高级的深度学习模型,期待我们的再次相会吧~