autograd包是pytorch里执行自动微分的一个包,看了一整天了,一定要搞懂。
直入主题:
首先我们要微分的对象是torch.tensor,定义的时候将requires_grad 设置为True,默认的是false,这时候autograd就会记录tensor的所有操作。通过.backward()计算该tensor的梯度,然后将梯度累积到.grad属性。
.backward()用来计算tensor的导数,如果tensor是一个标量,那么backward()中不需要传递任何参数,如果tensor有多个元素,则需要指定一个gradient参数来指定张量的形状(我还没明白为什么要指定张量的形状)
举例:
import torch
#定义一个3行3列的tensor元素全为1的矩阵
x = torch.ones(3, 3, requires_grad=True)
print(x)

针对这个tensor 做一个加法操作
y = x+2
print(y)
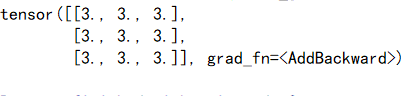
可以看到y有grad_fn属性,是一个AddBackward
继续对y操作
z = y*y*3
out = z.mean()
print(z, out)

从输出可以看到z的grad_fn属性是乘,out的grad_fn属性是Mean,也就是求平均。
刚刚从x到y到z再到out的过程是前向传播。现在我们调用.backward()进行后向传播。
因为out只有一个标量27,所以我们直接调用
out.backward()

这里面涉及到数学公式,我胡乱靠高中链式求导推出来结果一致,就是out.backward()就是out对x求导后的结果,
中间细节只有我能懂哈哈,因为他这个有对矩阵求导,跟高中还有点不一样。(想我高中数学老师)
大致就是这样了,其实只要知道.backward会求导就行了,这个程序是自动去执行的,我们不过管就可以。
完整代码:
import torch
x = torch.ones(3, 3, requires_grad=True)
print(x)
y = x + 2
print(y)
z = y*y*3
out = z.mean()
print(z, out)
out.backward()
print(x.grad)
根据官方教程我们可以再举一个例子看看:
import torch
x = torch.randn(3, requires_grad=True)
y = x * 2
#y.data.norm()就是相当于求y里面所有数的平方和再开平方,也就是p范数。
while y.data.norm() < 1000:
y = y * 2
print(y)
现在y不是一个标量,而是一个向量,里面有三个数。
所以我们不能直接调用.backward()来对x求导。
它是加了一个向量参数。
v = torch.tensor([0.1, 1.0, 0.0001],dtype=torch.float)
y.backward(v)
print(x.grad)
所以呀 就是为什么要加这个向量我不太懂,不过这并不影响我们以后自己搭建神经网络。
给上官网网址:http://pytorchchina.com/2018/06/25/what-is-pytorch/
看不懂的同学可以多看几遍,熟能生巧哦
关注我们,我们会每天坚持推送学到的新知识给你
