原文链接
补充推荐 类比的很贴切,看完会对ES机制有个整体的把握。
倒排索引为什么比B-Tree快?
| ID | Name | Age | Sex |
|---|---|---|---|
| 1 | Kate | 24 | Female |
| 2 | John | 24 | Male |
| 3 | Bill | 29 | Male |
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name
| Term | Posting List |
|---|---|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age
| Term | Posting List |
|---|---|
| 24 | [1,2] |
| 29 | 3 |
Sex
| Term | Posting List |
|---|---|
| Female | 1 |
| Male | [2,3] |
Posting List
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int数组,存储了所有符合某个term的文档id。
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学,爱回答问题的小明马上就举手回答:我知道,id是1,2的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排序,二分法查找term,logN的查找效率,就像通过字典树查找一样,这就是Term Dictionary。
现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树
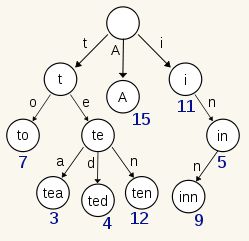
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。

Term Index → Term Directionary → Posting List
term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系。再结合FST的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
What is FST(Finite-State Transducer) ?
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
假设我们现在要将mop, moth, pop, star, stop, top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map

- ⭕️表示一种状态
- →表示状态的变化过程,上面的字母/数字表示状态变化和权重。
- 将单词分成单个字母通过⭕️和→表示出来,0权重不显示。
- 如果⭕️后面出现分支,就标记权重
- 最后整条路径上的权重加起来就是这个单词对应的序号。
FST以字节的方式存储所有的term,这种压缩方式可以有效缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
压缩技巧
Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。
小明喝完咖啡又举手了:"posting list不是已经只存储文档id了吗?还需要压缩?"
嗯,我们再看回最开始的例子,如果Elasticsearch需要对同学的性别进行索引(这时传统关系型数据库已经哭晕在厕所……),会怎样?如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。 Elasticsearch是如何有效的对文档id压缩的呢?
增量编码压缩,将大数变小数,按字节存储
首先,Elasticsearch要求posting list是有序的(为了提高搜索的性能,再任性的要求也得满足),这样做的一个好处是方便压缩,看下面这个图例:

鼓掌!
原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。
Roaring bitmaps
说到Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有某个posting list:
[1,3,4,7,10]
对应的bitmap就是:
[1,0,1,1,0,0,1,0,0,1]
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性:
将posting list按照65535为界限分块,比如第一块所包含的文档id范围在0~65535之间,第二块的id范围是65536~131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。

细心的小明这时候又举手了:"为什么是以65535为界限?"
程序员的世界里除了1024外,65535也是一个经典值,因为它=2^16-1,正好是用2个字节能表示的最大数,一个short的存储单位,注意到上图里的最后一行“If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”,如果是大块,用节省点用bitset存,小块就豪爽点,2个字节我也不计较了,用一个short存着方便。
why 4096?
联合索引
上面都是单field索引,如果多个field索引的联合查询,倒排索引如何满足快速查询的要求?
- 利用
跳表(Skip list)的数据结构快速做“与”运算,或者 - 利用上面提到的
bitset按位“与”
假设有下面三个posting list需要联合索引:

如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset,就很直观了,直接按位与,得到的结果就是最后的交集。
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
- 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
- 同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
- 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询