1、Why TensorFlow?
网上有关介绍太多了,我就不多说了,这里主要注重使用。

2、Programing model
2.1、Big Idea:
将数值的计算转化为图(computational graph),任何tensorflow的计算都是基于图的。
2.2、Graph Nodes:
图中的结点是有输入和输出的操作(operations),input的数量可以任意,output只有一个。
2.3、Graph Edges:
图的边是在结点见浮动的张量(tensors),tensors可以理解为n-维数组。
2.4、Advantages:
使用flow graphs作为deep learning framework的优点是可以通过简单少量的operations来构建复杂模型,使梯度的计算容易很多。当你在编写比较大的模型时,自动微分将会帮助到你。
2.5、Another Way To Think It:
每一个operation可以理解为在某一点可以执行的函数。
2.6、举个详细使用的栗子:
下面这个图展示了只有一个隐藏层的神经网络在Tensorflow中的计算,我们以Relu作为激活函数。

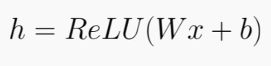
- W: 待训练的参数
- X: input
- b: bias
下面将介绍一下上图中出现的几个结点:
1、Variables:
W 和 b 参数作为TensorFlow中的Variables,在训练的过程中你需要调整这些参数,使得你的loss function最小,这些变量是有状态的结点,在图中多种的计算结点之间保持他们的状态,所谓保持状态就是指它们的值会被存下来,因此想要复原数据很容易,并且可以随时输出他们当前的值(current value),这些变量还有一些其他的features,可以在训练或者训练结束后持久化到disk中,因此可以允许不同的公司不同的组织去使用这些大型模型训练好的参数,并且默认进行梯度更新。
W 和 b这些变量也是operations。
2、Placeholders:
是一些在执行的过程中才会被赋值的结点,如果你网络的input 需要依赖一些其他外界的数据。
比如你不想用真实的值来计算。placeholders是你在训练过程中可以加入数据的地方。对于placeholders,我们不用对其进行任何初始化,我们只定义一个data type,并且赋值一个给定大小的tensor,我们的计算图就可以知道怎么去计算,甚至不用存储任何的数据。
3、Mathematical operations:
用于矩阵的乘法,加法,ReLu函数的计算。
4、废话少说,上代码!!! :
# 导入tensorflow包
import tensorflow as tf
# 创建一个有100个值的vector,作为bias, 默认为0
b=tf.Variable(tf.zeros((100,)))
# 创建并出示化权重,一个784*100 的矩阵,矩阵的初始值在-1到1之间
W=tf.Variable(tf.random_uniform((784,100),-1,1))
#为输入创建一个placeholder,不需要任何数据,只需要定义数据类型为一个32位浮点数,shape 为100*784
x=tf.placeholder(tf.float32,(100,784))
# tensorflow mathematical operations
h=tf.nn.relu(tf.matmul(x,W)+b)
关于h我想说:和numpy中很像,就是调用了tensorflow mathematical operations,我们没有真的乘某个数值,而仅仅在图中创建了一个符号来表示他,所以你不能输出该值,因为x只是一个placeholder,没有任何真值。我们现在只为我们的model创建了一个骨架。
5、说好的图呢 :
看了半天,这不和numpy手撸一样吗,其实作为程序员我们只要心里有着种抽象的概念就好,底层确实是以这种结点来实现的,如果你想看到,可以调用
tf.get_default_graph().get_operations()
你将会看到如下内容:

6、怎么跑这个例子呢? :
目前为止,我们已经定义了一个graph,我们需要把这个graph部署到一个session中,一个session可以绑定到一个具体的执行环境中(CPU或者GPU)
接着刚才的代码,我们在后面补充三行:
import numpy as np
import tensorflow as tf
b=tf.Variable(tf.zeros((100,)))
W=tf.Variable(tf.random_uniform((784,100),-1,1))
x=tf.placeholder(tf.float32,(100,784))
h=tf.nn.relu(tf.matmul(x,W)+b)
#创建session对象,初始化相关的参数
sess=tf.Session()
# initialize b 和 w
sess.run(tf.initialize_all_variables())
# 第一个参数是图中结点的输出,第二个参数是给placeholder赋的值,是一个map,定义每个结点的具体值
sess.run(h,{x : np.random.random(100,784)})
更多的关于Session的使用方法:
#自己创建一个session,不使用默认的session,使用完记得关了
sess=tf.Session()
sess=tf.run(train_step)
sess.close()
with tf.Session() as sess:
#使用这个创建的session计算结果
sess.run(train_step)
#不用close,with体帮我们进行资源的回收
#with体使用默认的session
sess=tf.Session()
with sess.as_default():
print(train_step.eval())
#也是使用默认的session
sess=tf.Session()
print(train_step.eval(session=sess))
#定义一个可交互式的session,自动将会话注册为默认会话
sess=tf.InteractiveSession()
train_step.eval()
sess.close()
#用自己的参数配置session
config=tf.ConfigProto(allow_aoft_placement=True,
log_device_placement=True)
sess1=tf.InteractiveSession(config=config)
sess2=tf.Session(config=config)
6、损失函数的创建 :
通过prediction 和 labels 创建loss node
# neural network的最后一步,用softmax做一个逻辑回归
prediction=tf.nn.softmax(...)
label=tf.placeholder(tf.float32,[100,10])
# 损失函数,用label乘上logP在列上的值
cross_entropy=-tf.reduce_sum(label* tf.log(prediction),axis=1)
7、如何计算梯度?:
tf.train.GradientDescentOptimizer创建了一个Optimizer是TensorFlow中定义的一个抽象类,它的每个子类,可以作为一个特定的学习算法,默认是梯度下降。在我们的图上面加了一个optimization operation,当我们执行这个train_step方法时(sess.run(train_step,feed_dict={x: batch_x, label: batch_label})),将会应用所有的梯度到模型中的变量中。这是因为minimize函数做了两件事情,首先是计算cross_entropy的梯度,然后进行梯度更新。
# 梯度下降,learning rate 为0.5,minimize方法的参数是一个需要被梯度下降的结点。
train_step= tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
7、训练模型?:
sess=tf.Session()
sess.run(tf.initialize_all_variables())
# 创建一个learning schedule, iterate 1000 次
for i in range(1000):
batch_x, batch_label = data.next_batch()
sess.run(train_step,feed_dict={x: batch_x, label: batch_label})
3、变量共享
当你在使用Tensorflow时,你想在一个地方初始化所有的变量,比如我想多次实例化我的graph或者我想在GPU集群上训练,我们需要共享变量。有以下两个解决方案:
其中一个方法是创建一个map,在需要使用的地方调用key获得value。但缺点是它大破了封装的思想。
TensorFlow的variable scope解决了这个问题,它为我们提供了一个提供了一个命名空间,避免了冲突。
with tf.variable_scope("hello world"):
v=tf.get_variable("v",shape=[1])
# v.name== " hello world/v:0"
with tf.variable_scope("hello world" reuse=True):
v=tf.get_variable("v",shape=[1])
# 可以找到共享的变量v
with tf.variable_scope("hello world" reuse=False):
v=tf.get_variable("v",shape=[1])
# CRASH hello world/v:0 已经存在了
4、官方demo (Official Demo):
MNIST手写体识别
4.1、基于Softmax逻辑回归
利用softmax regression,训练一个手写体分类:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tempfile
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 定义一个placeholder,
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
#定义一个用于存储正确标示的占位符
y_=tf.placeholder("float",[None,10])
#交叉熵损失函数
cross_entropy=-tf.reduce_sum(y_*tf.log(y))
#梯度下降进行训练
train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init=tf.initialize_all_variables()
sess=tf.Session()
sess.run(init)
#随机梯度下降
for i in range(1000):
batch_xs, batch_ys=mnist.train.next_batch(100)
print(sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys}))
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,"float"))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
4.2、基于CNN神经网络
# 利用CNN,训练一个手写体分类
"""Functions for downloading and reading MNIST data."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tempfile
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
from tensorflow.examples.tutorials.mnist import input_data
# 将系统默认的session作ion
sess = tf.InteractiveSession()
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 正确答案
y_ = tf.placeholder('float', [None, 10])
# 定义函数用于初始化权值,和bias
def weight_initialize(shape):
# 标准差为一,初始化权值
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initail = tf.constant(0.1, shape=shape)
return tf.Variable(initail)
x = tf.placeholder('float', [None, 784])
# 卷积
def conv2d(x, W):
#tf.nn.conv2d提供了一个非常方便的函数来实现卷积层向前传播的算法,这个函数的第一个输入为
#当前层节点矩阵,这个矩阵是一个四维矩阵,后面的三个维度对应一个节点矩阵,第一个维度对应一个
#输入batch.比如在输入层,input[0,:,:,:]表示第一张图片,input[1,:,:,:]表示第张图片二,tf.nn.conv2d
#第二个参数提供了卷积层的权重,第三个参数为步长,步长第一维,和最后一维固定是1,最后一个参数是填充方法
#SAME表示全0填充,VALID表示不添加
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 池化
def max_pool_2x2(x):
#ksize提供了过滤器的大小为2*2
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 卷积层第一层
W_conv1 = weight_initialize([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 卷积层第一层的relu和池化
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 5*5*32
# 卷积层第二层
W_conv2 = weight_initialize([5, 5, 32, 64])
b_conv2 = bias_variable([64])
# 卷积层第二层的relu和池化
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 全连接层的weight和bias
W_fc1 = weight_initialize([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
# output层
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# 使用dropout防止过拟合
# 过拟合概率
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 1024个神经元*10个输出
W_fc2 = weight_initialize([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2))
# 定义一个损失函数
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))
# 初始化所有变量
sess.run(tf.initialize_all_variables())
for i in range(2000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0
})
print("step %d, train accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: [0.5]})
print("test accuracy %g" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
训练结果如下:

别着急,我还要再废话一下:对于上面的实现,我们发现在网络层数增多的情况下,变量的命名可能会重复,造成错误,为了保证代码的可读性,我们可以采用如下的方式表示一个层的计算:
#第一个卷积层的参数
CONV1_DEEP=32
CONV1_SIZE=5
NUM_CHANNAL=1
#第二个卷积层的参数
CONV2_DEEP=64
CONV2_SIZE=5
#全连结层的节点
FC_SIZE=512
#第一个卷积层的实现
with tf.name_scope("Layer1-conv1"):
#定义权值,实际weight的名称为Layer1-conv1/weight
weight=tf.get_variable("weight",[CONV1_SIZE,CONV1_SIZE,NUM_CHANNAL,CONV1_DEEP],
initializer=tf.truncated_normal(stddev=0.1))
#定义bias
conv1_bias=tf.get_variable("bias",[CONV1_DEEP],initializer=tf.constant_initializer(0.1))
conv1=tf.conv2d(x, weight, strides=[1, 1, 1, 1], padding='SAME')
relu1=tf.nn.relu(tf.matmul(x,weight))
#第一个卷积层的池化
with tf.name_scope("Max-pooling"):
pool=tf.nn.max_pool(relu1,ksize=[1,1,1,1],strides=[1,2,2,1],padding='SAME')
#如果在构造大型网络的过程中,如果一个层用6行代码,还是太臃肿,这时候可以使用更简洁的
#TensorFlow-Slim工具来处理
net=slim.conv2d(input,32,[3,3])
5、总结:
- TensorFlow 每个结点都对应着梯度操作
- Computational graphy 很容易backwards每一个结点。
- 这些都是自动完成的。
- TensorFlow也把复杂的计算放在python之外完成,但是为了避免前面说的那些开销,它做了进一步完善。Tensorflow不单独地运行单一的复杂计算,而是让我们可以先用图描述一系列可交互的计算操作,然后全部一起在Python之外运行。