这个标题有点哗众取宠了。文科汪是不假,不过我有三年的移动(iOS)开发经验。
不过之前也没有接触过「机器学习」,所以也尽量深入浅出,希望真的是文科生也看得懂。
学习资源简介
机器学习的相关学习资料汗牛充栋,很多有意学习的朋友被淹没在浩瀚的资料中,不明所以。因此,找到适合自己程度的资料是很关键的。
最近在coursera上学习了一个关于机器学习方面的入门课程Machine Learning Foundations: A Case Study Approach(机器学习基础:个案研究法)。是华盛顿大学的一门线上公开课。
这个课程的特别之处,是从具体的案例(项目)入手,去介绍机器学习、深度学习。比起纯讲理论、晦涩难懂的课程,友好太多。(之前看吴恩达的机器学习课程,就没有坚持看完——我程度太低)。这个课程从以下5个案例(项目)展开,分别介绍相关理论知识:
- 预测房价(Predicting house prices)
- 引出Regression(回归)
- 从产品评论中判断买家态度(Analyzing the sentiment of product reviews)
- 引出Classification(分类)
- 检索维基百科的文章(Retrieving Wikipedia articles)
- 引出Clustering(聚类)
- 推荐歌曲(Recommending songs)
- 引出Collaborative fitering(协同过滤)
- 利用深度学习给图片分类(识别图片)(Classifying images with deep learning)
- 引出Deep learning(深度学习)、Neural networks(神经网络)
主要概念及环境搭建
什么是机器学习
「机器学习(Machine Learning)」这个词,1959年由美国的计算机科学家Arthur Samuel提出。
但是看完维基百科晦涩的定义后,也没搞清楚「机器学习(Machine Learning)」的具体定义。就用coursera课程中的一张流程图来理解什么是机器学习。
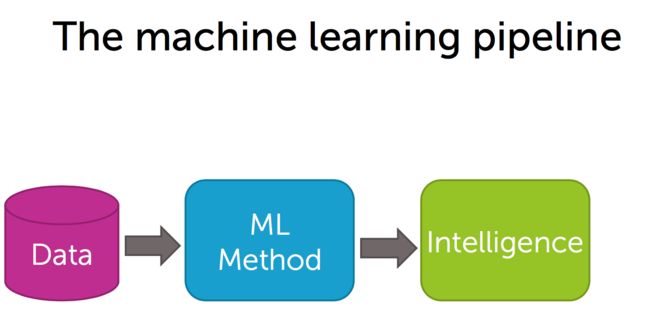
从这张流程图可以看到,首先,要有数据,把数据喂给某个算法(或者叫模型)进行「学习」,使其具有解决某种问题的能力(智力),我把这个过程,理解为「机器学习」。
以前的软件,是程序员写好一系列的规则,运行的时候按照这些规则来执行、解决问题。而软件加入「机器学习」之后,可以从喂入的数据中发现规则、学习规则,然后解决问题,这样看起来,软件就比以前显得智能多了。
可以看到,数据是前提条件,这也解释了为什么「机器学习」在1959年提出,到现在才「火」起来,因为现在各行各业产生的数据,都数字化了,产生了足够多的数据来应用到「机器学习」中。
吴恩达在接受WSJ采访是也说过类似的观点:
你所在的行业或者你关注的行业是否会受到AI的影响,这里有一个模式或许有用。首先:这个行业资料已数字化,意味着活动流程转移到计算机上。这就产生了数据,给了AI运用数据更加智能化处理业务的机会。
什么是深度学习,与机器学习的异同
「深度学习(Deep Learning)」,首先,它还是属于「机器学习」的范畴,是一种特殊的「机器学习」。接下来也是通过课程中的两张图来简单理解(这是个人理解,并不一定准确):
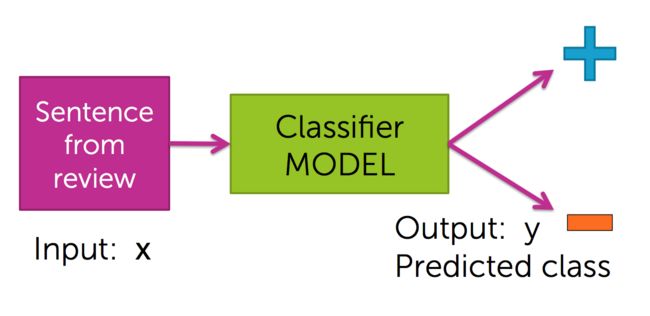
可以看到,上面这张图,是传统的「机器学习」过程:1.喂数据;2.学习(训练模型/算法);3.解决问题(这里解决的实际问题,是通过买家对产品的评论,判断买家是正面评价还是负面评价——后面会详细介绍)
传统的「机器学习」,是直接抽取数据的某些「特征(属性)」(这些「特征」被称为是「线性」的),最终形成问题的解决方案。
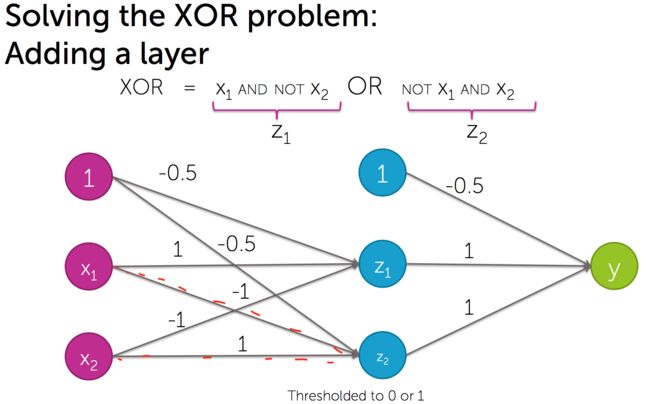
而有些问题(课程举例的是「XOR问题」),不能通过传统的「机器学习」解决,也就是说不能直接从「线性」的「特征」得出问题的解决方案。
这时候,「非线性特征(non-linear features)」提供了问题的解决方向,而「『神经网络(neural networks)』则提供了一种非线性的数据表现形式」。
如上图,我们不能直接通过数据的「特征」(x1, x2)得到问题的答案,所以对数据的「特征」进行多层次的变换,得到一些「非线性特征」(z1, z2)——「神经网络」中的一层——最终形成问题的解决方案。
图片中的这种数据结构,叫做「图(graphs)」,「神经网络」就是用这种数据结构来表示的。图片中的是一个3层的神经网络,中间还可以有若干层。
「神经网络」,本质上就是对数据进行多层次的变换。
综上,我们把上面这个过程,叫做深度学习——个人理解。另外,因为「深度学习」是构建在「神经网络」基础之上的,所以也有人将「深度学习」和「神经网络」等同起来。
备注:「深度学习」又叫「hierarchical learning(分层学习、多层次学习)」,我觉得这种叫法更能直观反映这个学习过程。
环境搭建及基本操作
Python
此课程使用编程语言Python(python的中文意思:大蟒蛇)
Python可以很方便地操作数据,并有很多第三方工具可供使用,让你可以轻松构建想要的应用程序。(R语言是另一种可供替代的语言)
iPython Notebook
Python的编程环境。界面如下(操作系统:macOS):
GraphLab Creat和SFrame
GraphLab Creat和SFrame都是Python下的应用于「机器学习」的库(框架)。用来处理大量数据。
GraphLab Creat,是Carlos Guestrin教授(此公开课的讲师之一)在2009年写的一个开源框架,最初用于机器学习,后被广泛用于数据挖掘(data-mining)
Carlos Guestrin教授,在2013年创建了一间叫Turi的公司,以继续GraphLab项目。这间公司在2016年8月5日被Apple以2亿美金收购。
安装
环境安装,不在此赘述,可以参考官网:Install GraphLab Create(需要先注册,下载使用。免费使用一年)
也在在线使用:Install GraphLab Create on AWS for Coursera Students
基本操作:
- 启动GraphLab Create:
import graphlab
这样,就可以使用GraphLab Creat中的所有工具了,包括SFrame和将要用到的算法。
快捷键shift + enter 就可以跳到下一行(新建一行)。
- 加载数据,支持多种格式的数据,CSV(逗号分隔文件):
sf = graphlab.SFrame('people-example.csv')
备注:people-example.csv文件要放在同一目录下(people-example.csv文件,就是一个表格类型的数据文件)。
- 显示数据:
sf或者sf.head()。直接输入变量名,接着敲Shift+回车,这样就会显示前面几行了(一个表格)。显示后面几行数据:sf.tail() - 可视化数据:直接用
show()函数,比如sf.show()即可用图表方式查看数据。这种情况下,图表会显示在一个新的页面上。
如果想直接iPython Notebook中看到可视化的数据,需要进行如下设置graphlab.canvas.set_target('ipynb') 这样就可以在当前页面看到可视化的数据了,无需跳转到其他页面。
sf['age'].show(view = 'Categorical'),表示显示「age」这一列,并以「分类排序(Categorical)」的形式显示。
检索数据
查看某一列的数据
sf['Country']计算某一列的平均值
sf['age'].mean()查看某列的最大值
sf['age'].max()创建新的一列:
sf['Full Name'] = sf['First Name'] + '' + sf['Last Name']。「Full Name」是新建列的名称,等号后面是新建列的内容。
在机器学习中,经常要将一些列进行转换,建成新的一列,这个过程叫做「feature engineering」。上面代码,就增加了一个「Full Name」特征。
一些运算
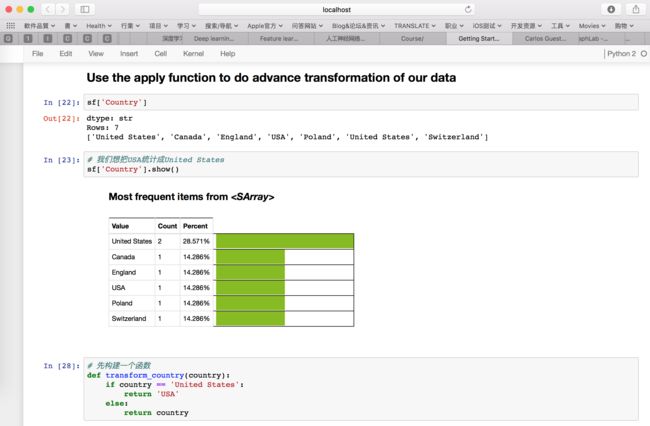
sf['age'] + 2:age列年龄都加2sf['age'] * sf['age']:age列年龄相乘Apply()函数,让你不用for循环,就能改变每一行(需要改变的)。(实现:将Country列中的所有USA改为United States)
先编写函数
def transform_country(country):
if country == 'USA'
return 'United States'
else:
return country
应用函数,并赋值给Country列(这样,每一行的USA就都会转换为United States了)
sf['Country'] = sf['Country'].apply(transform_country)
案例一:regression, linear regression(回归、线性回归)
这个案例,和吴恩达课程中的一样——预测房价。
假设我们有一组房子的数据,包括房子面积、房价、房间个数、洗手间个数等属性。如何通过这些数据,预测未知房子的房价?
如何实现?
正常情况下,我们想到利用一个坐标(Y轴是售价,X轴是房子面积),然后把所有已知数据标上去,然后「输入」你要预测房子的面积,你就会在Y轴得到一个大概的价格。如下图:
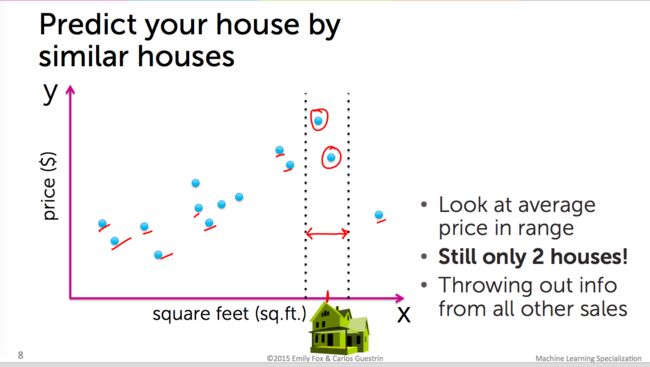
以上这种预测是简单、原始、不精确的。这时我们聪明的科学家想到了另一种解决问题的途径——利用统计学常用的分析数据的方法——「线性回归」,利用方程式,得到一条线,这样会得到更为精确的结果。如下图:
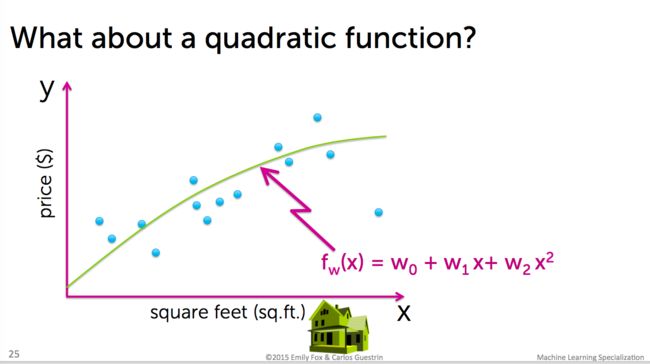
当然,这里问题就会变成:如何找到(「拟合」出)哪条最为精确的线?其中会涉及「二次方程」、「Residual sum of squares(RSS)(残差平方和/最小平方法)」等等概念,我们这里暂且忽略,有兴趣的可看课程详细了解。
当我们努力得出一条线(或者叫构造了一个(预测房价的)模型),如何确认这个模型的准确性呢?
这时候我们会把上面提到的那组真实的房价数据,划分为两部分,一个叫训练集(training set),一个叫测试集test set。训练集用于训练模型,测试集用于评价模型的准确性,并根据测试结果,按需调整模型的参数,使模型更准确。

具体到代码:
- 将数据随机分为训练集和测试集:
train_data, test_data = sales.random_split(.8, seed = 0)
- 利用训练集构建(训练)模型:
predict_house_price_model = graphlab.linear_regression.create(train_data, target = 'price', features = ['sqft_living'])
可以看到,利用GraphLab中linear_regression的create()函数,输入训练集,即可构建预测房价的模型。非常方便。
另外,最后一个参数features,传入的是一个数组,而现在,这个数组只有一个元素,就是房子的面积。为了获取更精确的预测结果,我们可以加入更多的特征,比如房子的房间数量,洗手间数量(课程中也有构建一个多特征的预测模型,并比较了两个模型的误差)。
- 评估模型的准确性:
predict_house_price_model.evaluate(test_data)
利用evaluate()函数,输入test_data作为参数,即可评估模型的准确性。
- 预测某个房子的房价
predict_house_price_model.predict(house1)
所以,总结一下,把机器学习应用到房价预测中的流程:
- 拿到一组数据,并将其划分为「训练集」和「测试集」;
- 利用「线性回归」方法,传入「训练集」构建一个预测房价的模型(俗称「喂数据」);
- 利用「测试集」,评估模型的准确性(误差)。并根据准确性,对模型进行必要的调整;
- 应用模型预测房价。
示意图如下:
案例二:Classification(分类)
案例二需要解决的问题是:如何从购物评论中,判断这个评价是好评还是差评?
课程中,利用分类(Classification)来解决此类问题,示意图如下:
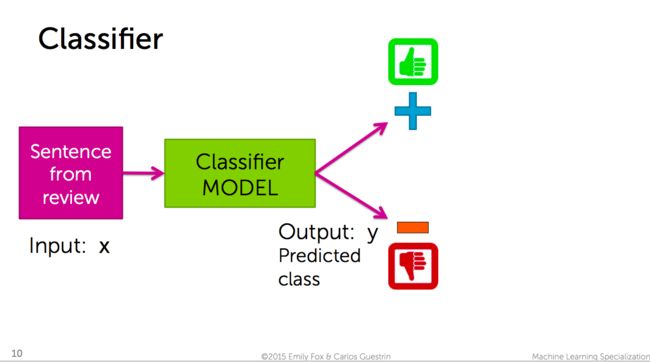
另外,「分类」可以判断多种类型(比如判断一篇文章是关于「体育」的,「金融」的,还是「科技」的)。
「分类」的其他应用领域:判断邮件是否为垃圾邮件;判断图片属于哪类型——其实就是我们熟知的图片识别了(后面会介绍到);判断一个人的健康状况……
Decision Boundary/决策边界
因为「分类」问题的数据,是离散的(区别于预测房价的数据,是线形的),所以会有一个Decision Boundary/决策边界的术语,如下示意图:
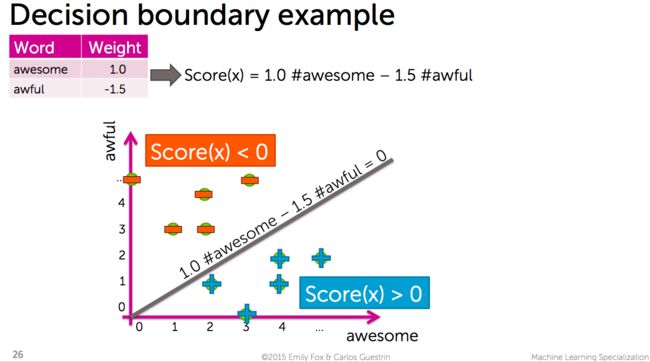
你可以理解为,决策边界上的评论,不是差评,也不是好评。
因此,我们也把这种「分类器」,成为「线性分类器(Linear calssifiers)」
看看代码:
- 将数据随机分为训练集和测试集:
train_data,test_data = products.random_split(.8, seed=0)
- 利用训练集构建(训练)模型:
sentiment_model = graphlab.logistic_classifier.create(train_data,
target='sentiment',
features=['word_count'],
validation_set=test_data)
- 评估模型:
sentiment_model.evaluate(test_data, metric='roc_curve')
- 应用模型:
sentiment_model.predict(giraffe_reviews, output_type='probability')
通过代码可以看出,应用机器学习解决分类问题,和案例一中是相仿的,都是利用「训练集」「喂」数据给模型,得出预测模型,并对其进行调整,以提高其精确性;最后再应用模型解决实际问题。
案例三:Clustering(聚类)
这个案例要解决的问题是:查找相似的文章(想象你在手机看着一篇自己喜欢的文章,计算机要找相似的文章给你)。所以,问题就变成:检索文章的相似度。
而本质上,这其实是一个多元化分类问题(Multiclass classification problem)(课程介绍「分类」时有提及)。
我们要把若干文章进行分组——科学家用一个术语表示这个过程——「聚类(Clustering)」。(分为体育新闻、世界新闻、娱乐新闻等等几大类)
而区别于上面讲的「线性回归」,「Clustering(聚类)」是一个「Unsupervised learning(无监督学习)」,因为我们的运算不需要任何(给定的)标签。
输入:这里的Training Data是文档,文档id,文档文本等这些东西。
输出:模型输出的是聚类标签(cluster label)
但是没有Test Data验证模型的准确性。所以依靠的是一个叫做「Voronoi tessellation/沃罗诺伊图」这样一个东西来做评估。
示意图:
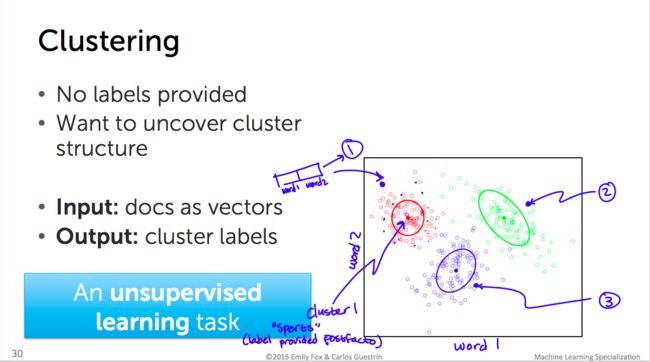
案例会引出「词袋模型(Bag of words model)」、「tf-idf」、「最邻近搜索(Nearest neighbor search)」等等这些术语,都是应用于检索文章相似度的,有兴趣可以看课程详细章节。
看看代码:
- 为整个文集people增加一列word_count
people['word_count'] = graphlab.text_analytics.count_words(people['text'])
- 利用
tf_idf()函数,得出tf_idf值
(暂时将tf_idf理解为一个「可以增加生僻词、关键词的权重,使评估文档相似性更加准确」的算法)
tfidf = graphlab.text_analytics.tf_idf(people['word_count'])
- 构建Nearest neighbor search模型
(Nearest neighbor search算法的Output返回的是一个集合,包含最相似的文章)
knn_model = graphlab.nearest_neighbors.create(people, features = ['tfidf'], label = 'name')
- 应用模型(检索到相似的文章)
knn_model.query(obama)
返回的结果类似如下:
与Barack Obama这篇文章「距离」越近的,表示文章相似度越高。
| reference_label | distance | rank |
|---|---|---|
| Barack Obama | 0.0 | 1 |
| Joe Biden | 0.794117647059 | 2 |
| Joe Lieberman | 0.794685990338 | 3 |
| Kelly Ayotte | 0.811989100817 | 4 |
| Bill Clinton | 0.813852813853 | 5 |
案例四:Collaborative Fitering(协同过滤)
这个案例要解决的问题是:制作一个商品推荐系统,推荐使用者需要的商品。
课程给出了几种解决方案:
- Solution 0: Popularity
最简单的解决方案:市面上流行什么,就推荐什么。
缺点:不够个性化。
- Solution 1: Classification model
「分类」,案例二介绍过的。
利用用户信息、购物历史、商品信息等其他信息作为参数,做一个二元「分类器(Classifier)」,判断购物者是否会想购买此商品。
优点:可以做到个性化;可以将购物情景(节日等)作为特征考虑进去……
缺点:特征可能不可用。
- Solution 2: People who bought this also bought...
这个方案,利用一种叫做「协同过滤/Collaborative filtering」的方法为用户做推荐,但前提是:有其他人的历史购物记录、产品推荐实例、用户和商品的一般化关系。
这个方法,引出了「协同矩阵/co-occurrence matrix」:保存了人们一同购买的产品的信息。
缺点:没有利用到用户特征、商品特征;「冷启动(Cold start problem)问题」——就是一个新注册用户,或者上架了一件新商品,没办法做推荐。
- Solution 3: Discovering hidden structure by matrix factorization
这种方案,引入「矩阵因子分解(Matrix factorization)」这个方法,是一种推理方式。通过把这个矩阵因式分解的方式来逼近它自身。
但是「Matrix factorization」还是没办法解决「Cold start problem」这个问题
所以,将各种模型结合起来提高性能的方法,能超越任何一种单一模型所能达到的性能,这是一种常见并且十分有效的技术。
看看代码(构建歌曲推荐系统):
- 将数据随机分为训练集和测试集:
train_data,test_data = song_data.random_split(.8,seed=0)
- 利用训练集构建一个简单的推荐模型(根据流程程度来推荐)
popularity_model = graphlab.popularity_recommender.create(train_data,
user_id='user_id',
item_id='song')
- 利用训练集构建一个更具个性化的推荐模型
personalized_model = graphlab.item_similarity_recommender.create(train_data,
user_id='user_id',
item_id='song')
- 应用模型
personalized_model.recommend(users=[users[0]])
- 比较两个模型的表现
if graphlab.version[:3] >= "1.6":
model_performance = graphlab.compare(test_data, [popularity_model, personalized_model], user_sample=0.05)
graphlab.show_comparison(model_performance,[popularity_model, personalized_model])
else:
%matplotlib inline
model_performance = graphlab.recommender.util.compare_models(test_data, [popularity_model, personalized_model], user_sample=.05)
评估推荐模型的性能,用一个叫做「precision recall curve(精度-召回率曲线)」来评价(横轴是recall,纵轴是precision)。
曲线和横纵坐标围成的区域的面积越大,表现越好。如下图:
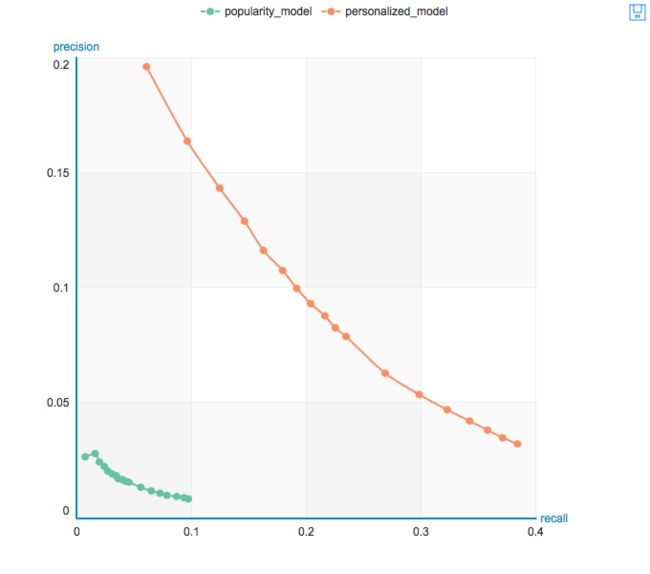
可以看到,personalized_model的表现是比popularity_model表现好的。
案例五:Deep learning(深度学习)
这个案例要解决的问题是:图像识别——具体是「基于展示照片的相似度选购商品」。
上面「主要概念」已经介绍过,有些问题利用传统的机器学习无法解决(课程中的「XOR」问题做引子),换言之就是不能直接从「线性」的「特征」得出问题的解决方案。需要用到「非线性的数据表现形式/non-linear features」,而「神经网络」,提供了一种非线性的数据表现形式/non-linear features。(示意图见上面「主要概念介绍」)
第一个让神经网络大显身手的领域:计算机视觉——分析图像和视频。
计算机视觉中,「image feature」相当于「local detector/局部探测器」,这些「探测器」结合起来就能做出预测(图像识别)
例子:识别一张人脸:鼻子探测器、左眼探测器、右眼探测器、嘴巴探测器……如果所有探测器都探测到对应的东西,就可以预测这是一张人脸。
但是实际中是没有「鼻子探测器」这些东西的。实际是应用「image feature」:collections of locally interesting points——Combined to bulid classifiers。就是一些局部特征探测器/detectors of local features。
在以前,这些局部特征探测器都是手工完成的(SIFT features)。
而「神经网络」方法,可以自动去发现和识别这些特征。「神经网络」在不同的层里,抓取图像特征,做到自动学习。(深度学习令人振奋之处,就是它能从图片中学习一些非常复杂的特征——识别德国交通信号灯准确率:99.5%;识别谷歌那些门牌号数字准确率:97.8%)。
「神经网络」的局限:
- 需要大量精确的数据
- 计算代价昂贵
- 很难调整:因为太多层,太多参数,太太太复杂。(所以如果仓促把过多的选择和计算开销搅在一起,会很难搞清楚,到低哪个「神经网络」比较适用。)
为解决这一问题,引进「深度特征/deep features」:能够帮助我们建立「神经网络」——甚至你没有很多数据的时候。
Deep features = Deep learning + Transfer learning(迁移学习)
「深度特征」提供了一个很好的途径,让我们在仅有很少数据的情况下,构建高准确率的预测模型(分类器),如下示意图:(代码实践中,图像识别的准确率,由47%提高到78%)
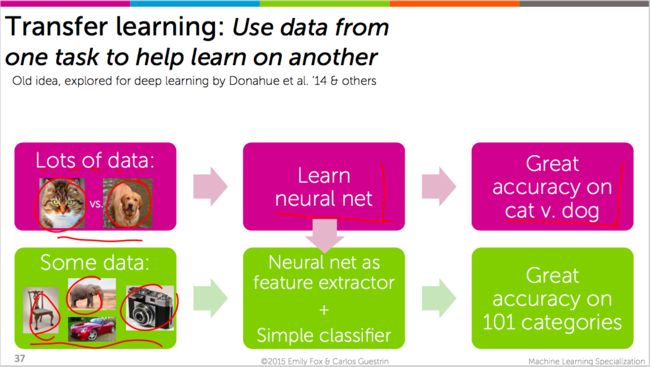
看看代码:
- 加载图片数据,将数据随为训练集和测试集:
image_train = graphlab.SFrame('image_train_data/')
image_test = graphlab.SFrame('image_test_data/')
- 利用训练集,用「原始的照片像素」构建一个分类器模型(识别图像):
注意:「feature」是「图片像素」,并没有用到「deep feature」
# 在sentiment analysis中有用过「logistic_classifier()」函数
# create:代表创造模型
# 参数1:训练集
# 参数2:目标——数据集中label那一列
# 参数3:会用到哪些特征(image_array保存的是数据的元素像素)
raw_piexl_model = graphlab.logistic_classifier.create(image_train, target = 'label',
features = ['image_array'])
# 上面的代码表示:用原始的照片像素建立一个分类器
- 应用模型识别图片:
# 利用原始像素模型预测前三张图片(结果是三张都识别错了)
raw_piexl_model.predict(image_test[0:3])
- 评估模型识别图片的准确率:
# 调用evaluate()函数评估模型的准确率
raw_piexl_model.evaluate(image_test)
运行后,可以看到'accuracy': 0.47825,,只有48%左右的准确率,很不理想
- 提取「深度特征(Deep features)」
# 用graphlab的load_model()函数,载入一个deep_learning_model,这个是已经训练好/pre-trained的了(载入即可)。
# 「imagenet_model」是模型载入的数据,有150张照片,1000个标签。
deep_learning_model = graphlab.load_model('imagenet_model')
# 在image_train中添加一列deep_features;
# extract_features()函数用来提取「深度特征/deep features」,传入的参数,就是将提取出来的特征,要用到哪个数据集中。
image_train['deep_features'] = deep_learning_model.extract_features(image_train)
以上两行代码,就是用来做「迁移学习/transfer learning」的(用网上训练的特征,应用到image_train数据集中)
- 利用训练集,用「深度特征」构建(训练)模型:
# 构建另一个有别于基于像素进行预测的模型deep_features_model
# 也是用logistic_classifier的create()函数构建
# 参数1:训练集
# 参数2:会用到哪些特征(deep_features是刚刚通过「迁移学习」得到的)
# 参数3:目标——数据集中label那一列
deep_features_model = graphlab.logistic_classifier.create(image_train,
features = ['deep_features'],
target = 'label')
- 应用deep_features_model识别图片(3张都识别正确了):
deep_features_model.predict(image_test[0:3])
并且准确率提高到'accuracy': 0.7765,,78%左右。
篇幅有限,此案例要解决的问题——「基于展示照片的相似度选购商品」,思路就是利用「最邻近搜索(Nearest neighbor search)」算法(「聚类」中有涉及)、「深度特征」构建模型,再利用这个模型输入图片,就会输出类似的图片。代码可参考:tjaskula/Coursera。
学识有限,课程中有很多概念、方法也还没有消化,谬误在所难免,也不求你斧正了。权当科普文一览。