- Go语言中没有前置++、--运算符
if number := 4; 100 > number {
number += 3
} else if 100 < number {
number -= 2
} else {
fmt.Println("OK!")
}
- 这里的
number := 4被叫做if语句的初始化子句。它应被放置在if关键字和条件表达式之间,并与前者由空格分隔、与后者由英文分号;分隔,个人不建议这样写,因为容易造成标识符的重声明。
// 程序所属包,每个.go文件必须要有package关键字
package main // 包名尽量与文件目录名一样
// 导入依赖包
import (
. "fmt"
"time"
)
func main() {
a := -1
if a > 0 {
Println("a > 0 !!!")
}else if a < 0 {
Println("a < 0 !!!")
}else {
Println("a == 0 !!!")
}
b := 1
switch b {
case 1:
Println("1...")
case 2:
Println("2...")
case 3:
Println("3...")
default:
Println("以上都不满足条件!!!")
}
var c interface{}
c = "学习Go语言"
switch c.(type) { // 判断变量c的类型
case int:
Println("变量c为整型")
case string:
Println("变量c为字符串型")
default:
Println("以上都不满足条件!!!")
}
// a < 0 !!!
// 1...
// 变量c为字符串型
// 循环语句
for i := 1; i < 5; i++ {
Println("Go...")
}
arr := [] string{"香蕉","苹果","雪梨"}
// for-each循环遍历数组,若只要value,且不使用key,只需将key变量改成下划线_,否则会报错
for key, value := range arr {
Print(key)
Println("--->" + value)
}
// goto 语句
// goto One // 只跳转执行一次
Println("这里是中间代码块!!!")
One:
Println("这里是代码块一!!!")
time.Sleep(1 * time.Second)
// 若放在此处,则进入死循环
// goto One
}
Go命令基础
-
go run:用于运行命令源码文件,只能接受一个命令源码文件以及若干个库源码文件作为文件参数。其内部操作步骤是:先编译源码文件再运行。 - 常用标记的使用:
1、-a:强制编译相关代码,无论它们的编译结果是否已是最新的;
2、-n:打印编译过程中所需运行的命令,但不真正执行它们;
3、-p n:并行编译,其中n为并行的数量(其值最好设置成本机逻辑CPU的个数);
4、-v:列出被编译的代码包的名称;
5、-a -v:列出所有被编译的代码包的名称;
6、-work:显示编译时创建的临时工作目录的路径,并且不删除它;
7、-x:打印编译过程中所需运行的命令,并执行它们。 -
go build:用于编译源码文件或代码包;编译非命令源码文件不会产生任何结果文件;编译命令源码文件会在该命令的执行目录中生成一个可执行文件。
1、执行该命令且不追加任何参数时,它会试图将当前目录作为代码包并编译;
2、执行该命令且以代码包的导入路径作为参数时,该代码包及其依赖会被编译;
3、执行该命令且以若干源码文件作为参数时,只有这些文件会被编译; -
go install:用于编译并安装代码包或源码文件。
1、安装代码包会在当前工作区的pkg/<平台相关目录>下生成归档文件;
2、安装命令源码文件会在当前工作区的bin目录或$GOBIN目录下生成可执行文件;
3、执行该命令且不追加任何参数时,它会试图将当前目录作为代码包并安装。
4、执行该命令且以代码包的导入路径作为参数时,该代码包及其依赖会被安装;
5、执行该命令且以命令源码文件及相关库源码文件作为参数时,只有这些文件会被编译并安装。 -
go get:用于从远程代码仓库上下载并安装代码包。
1、受支持的代码版本控制系统有:Git、Mercurial(hg)、SVN、Bazaar;
2、指定的代码包会被下载到$GOPATH中包含的第一个工作区的src目录中;
3、-d:只执行下载动作,而不执行安装动作;
4、-fix:在下载代码包后先执行修正工作,而后再进行编译和安装;
5、-u:利用网络来更新已有的代码包及其依赖包; - 标识符可以是任何Unicode编码可以表示的
字母字符、数字、下划线"_"。不过,首字母不能是数字或下划线。 - 用于
声明变量的关键字var,用于声明常量的关键字const。注意:对于常量不能出现只声明不赋值的情况。 - 在Go语言里,浮点数的相关部分只能由
10进制表示法表示,而不能由8进制表示法或16进制表示法表示。比如,03.7表示的一定是浮点数3.7。指数部分由“E”或“e”以及一个带正负号的10进制数组成。比如,3.7E-2表示浮点数0.037。又比如,3.7E+1表示浮点数37。complex64类型的值由两个float32类型的值分别表示复数的实数部分和虚数部分;而complex128类型的值会由两个float64类型的值分别表示复数的实数部分和虚数部分。 -
byte是uint8的别名类型,而rune则是int32的别名类型。 - 一个
rune类型的值即可表示一个Unicode字符。Unicode是一个可以表示世界范围内的绝大部分字符的编码规范。用于代表Unicode字符的编码值也被称为Unicode代码点。一个Unicode代码点通常由“U+”和一个以十六进制表示法表示的整数表示。例如,英文字母“A”的Unicode代码点为“U+0041”。 -
rune类型的值需要由单引号包裹。
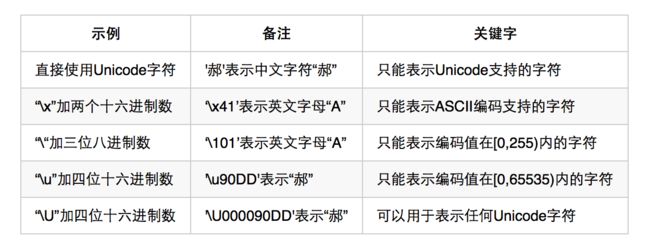
几种形式表示rune类型值
- 在rune类型值的表示中支持几种特殊的字符序列,即:
转义符。它们由“\”和一个单个英文字符组成。
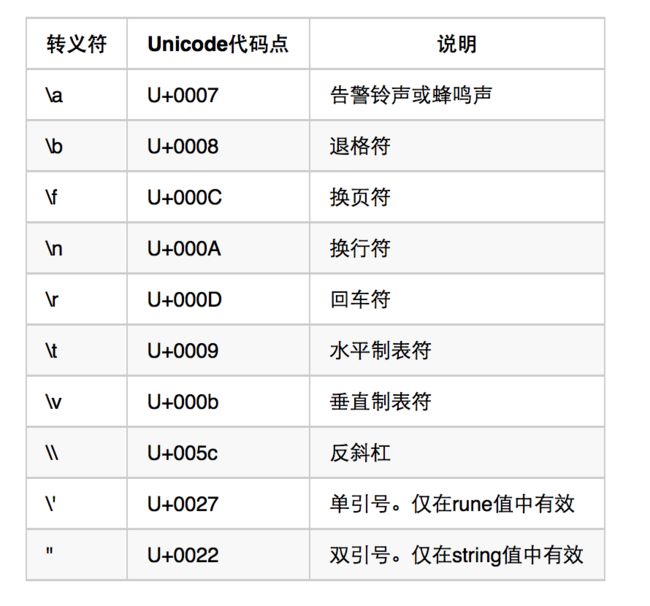
特殊的字符序列
- 一个字符串(字符序列)会被Go语言用Unicode编码规范中的UTF-8编码格式编码为
字节数组。 - 字符串的表示法有两种,即:
原生表示法和解释型表示法。若用原生表示法,需用反引号“`”把字符序列包裹起来。若用解释型表示法,则需用双引号“"”包裹字符序列。注意:字符串值是不可变的。
package main
import (
"fmt"
)
func main() {
// 声明一个string类型变量并赋值
var str1 string = "\\\""
// 这里用到了字符串格式化函数。其中,%q用于显示字符串值的表象值并用双引号包裹。
fmt.Printf("用解释型字符串表示法表示的 %q 所代表的是 %s。\n", str1, `\"`)
}
// 输出结果:用解释型字符串表示法表示的 "\\\"" 所代表的是 \"。
数组类型
- 声明一个数组类型别名:
type arr [3]int。注:类型声明语句由关键字type、类型名称和类型字面量组成。 - 注:
len是Go语言的内建函数的名称。该函数用于获取字符串、数组、切片、字典或通道类型的值的长度(所占的字节数)。 使用len()函数获取数组的长度:var length = len(numbers) - 声明一个数组:
var numbers2 [5]int - 声明并初始化一个数组:
var numbers = [3]int{1, 2, 3}
切片类型
- 切片(Slice)与数组一样,可以容纳
若干类型相同元素的容器。与数组不同的是,无法通过切片类型来确定其值的长度。切片的底层数组:每个切片值都会将数组作为其底层数据结构。 -
类型字面量:用于表示某个类型的字面表示(或称标记方法)。相对的,用于表示某个类型的值的字面表示可被称为值字面量,或简称为字面量。 - 表示切片类型的字面量如:
[]int或者[]string,其与数组的类型字面量的唯一不同是不包含代表其长度的信息。 - 切片类型别名的声明:
type MySlice []int - 切片值的表示:
[]int{1, 2, 3} - 作为切片表达式求值结果的
切片值的长度总是为元素上界索引与元素下界索引的差值(左闭右开区间)。 - 除了长度,切片值以及数组值还有另外一个属性——
容量。 -
数组值的容量总是等于其长度。而切片值的容量则往往与其长度不同。为了获取数组、切片或通道类型的值的容量,可以使用内建函数cap,例如:var capacity2 int = cap(slice2) - 注意:
切片类型属于引用类型。它的零值为nil,即空值。若只声明一个切片类型的变量而不为它赋值,那么该变量的值将会是nil。例如:var slice3 []int,那么它的值会是nil。
package main // 包名尽量与文件目录名一样
// 导入依赖包
import (
. "fmt"
)
func main() {
var arr = []int32{1, 2, 3, 4, 5, 9, 8, 7}
var num [5]int8 // 只声明一个数组类型的变量,默认赋值为零值
for i := 1; i < 5; i++ {
Print(num[i])
if i != 4 {
Print(" ")
} else {
Println("")
}
}
Println("原数组中的元素如下:")
var len1 = len(arr)
for i := 0; i < len1; i++ {
Print(arr[i])
if i == len1 - 1 {
Println("")
}else {
Print(" ")
}
}
Println("以下是获取的切片值:")
var slice1 = arr[1 : 4] // 左闭右开:[1, 3]
for index, value := range slice1 { // for-each循环
Println(index, value)
}
var n1, n2 = 1, 1.1
// 格式化输出:%v,用于表示true or false
Printf("%v\n", n1 == int(n2)) // 使用的输出函数是Printf()
var numbers1 = [5]int{1, 2, 3, 4, 5}
println("数组的长度为:", len(numbers1))
slice2 := numbers1[2 : len(numbers1)]
Println("切片的长度为", len(slice2))
// 一个切片值的容量即为它的第一个元素值在其底层数组中的索引值与该数组长度的差值的绝对值。
var slice3 []int
println(slice3)
// for index, key := range slice3 {
// Println(index, key)
// }
}
- 切片的第三个正整数参数:
容量上界索引。意义:在于可以把作为结果的切片值的容量设置得更小。换句话说,它可以限制我们通过这个切片值对其底层数组中的更多元素的访问。 - 使用内建函数
append()对切片值进行扩展:slice1 = append(slice1, 6, 7)。一旦扩展操作超出了被操作的切片值的容量,那么该切片的底层数组就会被自动更换。 - slice = slice[low : high : max] : low为截取的
起始下标(含), high为截取的结束下标(不含high),max为切片保留原切片的最大下标(不含max);即新切片从老切片的low下标元素开始,len = high - low,cap = max - low;high 和 max一旦在老切片中越界,就会发生runtime err,slice out of range。另外若省略第三个参数,则第三个参数默认和第二个参数相同,即len = cap。
package main // 包名尽量与文件目录名一样
// 导入依赖包
import (
. "fmt"
)
func main() {
var num1 = [...]int{1, 2, 3, 4, 5}
var slice1 = num1[1 : 3 : 4] // 切片的长度为3,实际容量是4
Println("切片的长度为:", len(slice1))
Println("切片的容量为:", cap(slice1))
slice1 = slice1[: cap(slice1)] // 获取相同容量的切片长度4
Println("切片的长度为:", len(slice1))
Println("切片的容量为:", cap(slice1))
slice1 = append(slice1, 6, 7, 11)
Println("切片的长度为:", len(slice1))
Println("切片的容量为:", cap(slice1))
var slice2 = []int{0, 0, 0}
copy(slice1, slice2) // 切片slice2前三个元素会将slice1前三个元素覆盖
Println("切片的长度为:", len(slice1))
Println("切片的容量为:", cap(slice1))
// for-each循环遍历
for k, v := range slice1 {
Println(k, v)
}
}
字典类型
- 字面量:
map[K]T,K”意为键的类型,而“T”则代表元素(或称值)的类型。注意:字典的键类型必须是可比较的,它不能是切片、字典或函数类型。!!! - 定义并初始化一个字典:
mm := map[int]string{1: "a", 2: "b", 3: "c"} - 运用索引表达式取出字典中的值:
b := mm[2] - 向mm添加一个键值对:
mm[4] = "" - 对于字典值来说,若不存在索引表达式欲取出的键值对,那么就以它的
值类型的空值(或称默认值)作为该索引表达式的求值结果。 - 判断字典中是否存在一个键值对:
e, ok := mm[5]。第二个求值结果是bool类型,用于表明字典值中是否存在指定的键值对。在上例中,变量ok必为false。 - 使用内建函数
delete()删除键值对:delete(mm, 4),其中4为键,有则删除,无则不做。 - 与切片类型相同,字典类型属于
引用类型。它的零值为nil。
通道类型
- 通道(Channel)是Go语言中一种非常独特的数据结构。它可用于在
不同Goroutine之间传递类型化的数据,并且是并发安全的。 -
Goroutine(也称为Go程序)可被看做是承载可被并发执行的代码块的载体。它们由Go语言的运行时系统调度,并依托操作系统线程(又称内核线程)来并发地执行其中的代码块。 - 通道类型的表示方法:
chan T。 与其它的数据类型不同,我们无法表示一个通道类型的值。因此,我们也无法用字面量来为通道类型的变量赋值。我们只能通过调用内建函数make来达到目的。 - make函数可接受两个参数:第一个参数是代表了
将被初始化的值的类型的字面量(比如chan int),而第二个参数则是值的长度。例如:初始化一个长度为5且元素类型为int的通道值,make(chan int, 5)。实际上make函数也可以被用来初始化切片类型或字典类型的值。确切地说,通道值的长度被称为其缓存的尺寸。 - 声明一个通道类型的变量(带缓冲的通道),并为其赋值:
ch1 := make(chan string, 5),使用接收操作符<-向通道值发送数据:ch1 <- "value1";从ch1那里把接收到的字符串赋给一个变量:value := <- ch1。 - 与针对
字典值的索引表达式一样,针对通道值的接收操作也可以有第二个结果值:value, ok := <- ch1。目的:为了消除与零值有关的歧义。这里的变量ok的值同样是bool类型的。它代表了通道值的状态,true代表通道值有效,而false则代表通道值已无效(或称已关闭)。 - 使用内建函数
close()关闭通道值:close(ch1) - 另外,在通道值有效的前提下,针对它的
发送操作会在通道值已满(其中缓存的数据的个数已等于它的长度)时被阻塞。另一方面,针对有效通道值的接收操作会在通道值已空(其中没有缓存任何数据)时被阻塞。 - 与
切片和字典类型相同,通道类型属于引用类型。它的零值即为nil。
package main // 包名尽量与文件目录名一样
// 导入依赖包
import (
. "fmt"
)
func main() {
ch2 := make(chan string, 1)
// 下面就是传说中的通过启用一个Goroutine来并发的执行代码块的方法。
// 关键字 go 后跟的就是需要被并发执行的代码块,它由一个匿名函数代表。
// 在这里,我们只要知道在花括号中的就是将要被并发执行的代码就可以了。
go func() {
ch2 <- ("已到达!")
}()
var value string = "数据"
value = value + (<- ch2) // 从通道那里接收值
Println(value) // 数据已到达!
}
- 通道有
带缓冲和非缓冲之分。缓冲通道中可以缓存N个数据,在初始化一个通道值的时候必须指定这个N。相对的,非缓冲通道不会缓存任何数据。发送方在向通道值发送数据时会立即被阻塞,直到有某一个接收方已从该通道值中接收了这条数据。 - 非缓冲的通道值的初始化方法:
make(chan int, 0)。 注意:给予make函数的第二个参数值是0。 - 以数据在通道中的
传输方向为依据来划分通道。默认情况下,通道都是双向的,即双向通道。如果数据只能在通道中单向传输,那么该通道就被称作单向通道。 - 我们在初始化一个通道值时
不能指定它为单向。但是,在编写类型声明时,我们却是可以这样做的。例如:type Receiver <-chan int。 类型Receiver代表了一个只可从中接收数据的单向通道类型。这样的通道也被称为接收通道。相对应的,声明一个发送通道类型,应为:type Sender chan<- int。我们可以把一个双向通道值赋予上述类型的变量,就像这样:
var myChannel = make(chan int, 3)
var sender Sender = myChannel
var receiver Receiver = myChannel
但是,反之则是不行的,像下面这样的代码是通不过编译的:
var myChannel1 chan int = sender
- 单向通道的主要作用是
约束程序对通道值的使用方式。
package main // 包名尽量与文件目录名一样
// 导入依赖包
import (
"fmt"
"time"
)
type Sender chan<- int // 发送通道
type Receiver <-chan int // 接收通道
func main() {
var myChannel = make(chan int, (0)) // 创建一个非缓冲通道
// 由于创建的是非缓冲通道,只有当接收方已从该通道值中接收了这条数据,发送方才能向通道值发送数据
// 因此输出结果为:
// Received! 6
// Sent!
var number = 6
// 并发程序
go func() {
var sender Sender = myChannel
sender <- number // 只向通道发送数据
fmt.Println("Sent!")
}()
go func() {
var receiver Receiver = myChannel
fmt.Println("Received!", <-receiver) // 只从通道中接收数据
}()
// 让main函数执行结束的时间延迟1秒,
// 以使上面两个代码块有机会被执行。
time.Sleep(time.Second)
}