作为小白,推荐系统小白,机器学习小白,本白近期非脱产学习状态下利用不到两个月进行了推荐系统入门学习。写下第一篇,用以归纳近期所学,以下为目前阶段浅薄理解,希望可以与各位交流,向大家学习。文中引用借鉴之源均列于文末,非常感激前辈们的分享。如文中有理解偏差,望请提出!
本文结构如下:
Part 1 Introduction 简要介绍推荐系统
Part 2 Algorithms Deep Dive 对矩阵分解系列算法和深度学习系列算法进行整理
Part 3 Main Focus 对主要关注和实现的两个算法(DIN,xDeepFM)进行总结
Part 1 Introduction
Annotation:以下仅考虑个性化推荐系统,“物品”代表待推荐集合(商品,新闻,广告等),也可以理解为待与用户交互的信息
1.概述
个性化推荐系统的意义在于缓解信息过载问题,发掘长尾物品,实现用户与企业的共赢。物品所代表的即是信息,推荐通过一种算法能力,按照一定规则将用户与信息联系起来。具体而言,个性化推荐系统即进行TopN推荐,即向用户展示其最有可能进行交互的N个物品。评分预测问题/CTR(Click-Through Rate)预估问题是个性化推荐系统的核心问题
2.分类
(1)基于内容(Content-based)
根据用户过去交互(喜欢)的物品推荐相似的物品。主要特点为可以找到用户独特的小众喜好,可解释性好
基本过程:
1.Item Representation:为每个物品抽取一些特征来表示该物品
2.Profile Learning:利用用户物品交互信息表示该用户
3.Recommendation Generation:通过比较用户的表示和物品的表示为用户推荐一组相关性最大的物品
(2)基于协同过滤(Collaborative Filtering)
1.基于内存:需要建立并维护User-Item矩阵
基于用户的协同过滤(User-based CF):首先构建UI矩阵,根据UI矩阵来计算用户维度的相似度,选择特定用户最相似的k个用户,推荐给特定用户列表中还没有发生过行为而在相似度列表中产生过行为的高频物品
基于物品的协同过滤(Item-based CF):首先构建UI矩阵,根据UI矩阵来计算物品维度的相似度,选择特定物品最相似的k个物品构成推荐列表,推荐给特定用户列表中还没有发生过行为的物品
2.基于模型
基本问题:利用已有的部分稀疏数据来预测空白的物品和用户之间的评分关系,找到最高评分的物品推荐给用户。
关联算法/聚类算法/分类算法/回归算法/矩阵分解/隐语义模型/神经网络/图模型
(3)混合推荐(Hybrid)
类似于机器学习中的集成学习,通过多个推荐算法的结合,得到一个更好的推荐算法。例如:建立多个推荐算法模型,最后用投票法决定最终的推荐结果。理论上混合推荐结果不会比任何一种单一推荐算法差,但是算法(时间)复杂度会显著提高,在特定的的评价指标下混合推荐结果并不一定由于单一推荐算法
(4)基于人口统计学(Demographic-based)
根据系统用户的基本信息发现用户的相关程度后进行推荐
(5)基于规则(Rule-based)
基于最多用户点击,基于最多用户浏览等,属于大众型的推荐算法
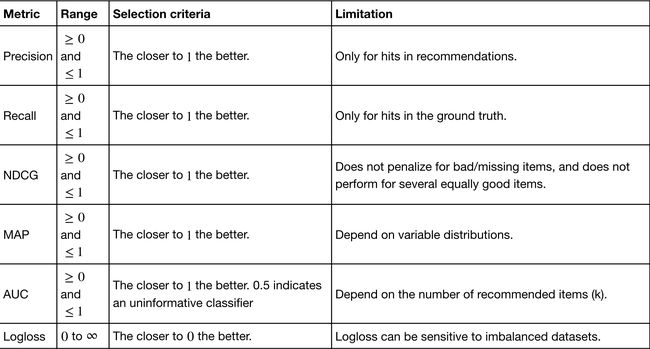
3.评价指标
(1)Rating Metrics

(2)Ranking Metrics
4.工业级应用
工业级应用中需要分级达成TopN推荐:首先将物品进行多路召回(初步筛选)产生候选集,再进行评分预测/CTR预估并排序生成TopN推荐。
Part 2 Algorithms Deep Dive
1.矩阵分解系列算法
(1)传统SVD
为评分矩阵,为用户隐因子矩阵,为物品隐因子矩阵,为奇异值矩阵(对角矩阵,每个元素非负,逐渐减小),因此我们可以用前k个元素表示它。传统SVD分解要求矩阵是稠密的,因此通常先用均值或其他统计学方法将其填充后再进行传统SVD分解降维,稠密矩阵的存储需要非常大的空间,同时计算复杂度也很高
(2)Funk-SVD (Latent Factor Model)
将分解为两个低秩的用户项目矩阵,借鉴线性回归的思想,通过最小化数据的平方来寻求最优的用户和物品的隐含向量表示,为了避免过拟合加入L2正则化,用SGD等方法寻求最优解即可
用户对物品的预测值:
损失函数:
后续提出的三种改进方法均仅对进行优化
(3)BiasSVD
对于一个评分系统,有些固有属性与用户物品无关,用户有些属性与物品无关,物品有些属性与用户无关,因此需要加入偏置项(训练集中所有记录的评分的全局平均数)以及用户偏置项和物品偏置项
(4)SVD++
用户除了对于项目的显式历史评分记录外,浏览记录或者收藏列表等隐反馈信息同样可以从侧面一定程度上反应用户的偏好
为用户所产生隐反馈的物品集合,为隐藏的对于项目的个人喜好偏置,是一个需要学习的参数,是一个经验公式
(5)TimeSVD++
用户的兴趣或者偏好并不是一成不变的,而是随着时间而动态变化,在假设物品的隐含表示不随时间变化的情况下,假设用户的偏置,物品的偏置,以及用户的隐含因子表示随时间而动态变化
2.深度学习系列算法
(1)神经网络观点看FM
为了进一步去除重复项和特征平方项,得到如下公式
为因子分解后的二阶组合特征的权重矩阵,是将离散系数特征通过矩阵乘法降维成一个低维稠密向量。即FM首先是对离散特征进行嵌入,之后通过对嵌入后的稠密向量进行内急来进行二阶特征组合,最后再与线性模型的结果求和进而得到CTR(Click-Through Rate)

(2)FM考虑领域(Field)信息
FM的一个核心步骤就是嵌入,但是这个嵌入过程没有考虑领域信息,这使得同领域内的特征也被当做不同领域特征进行两两组合。由此考虑可以将特征具有领域关系的特点作为先验知识加入到神经网络的设计中去,同领域的特征嵌入后直接求和作为一个整体嵌入向量,进而与其他领域的整体嵌入特征进行两两组合,之后再进行二阶特征的向量内积。本质上考虑邻域信息等同于考虑了邻域内信息的相似性,即给FM加入正则。同时,这些嵌入后的同领域特征可以拼接起来作为更深的神经网络输入,达到降维的目的

(3)Embedding+Multi-Layer Perceptron
Embedding+MLP是对于分领域离散特征进行深度学习CTR预估的通用框架,深度学习在特征组合挖掘即特征学习方面具有很大的优势。究其过程,首先要将不同领域的one-hot特征进行embedding,使其降维成低维稠密特征,然后将这些特征向量拼接成一个隐含层,之后再不断堆叠全连接层(MLP),最后得出CTR
其问题在于只学习高阶特征组合,对于低阶特征组合不够兼容,而且参数较多,学习较困难

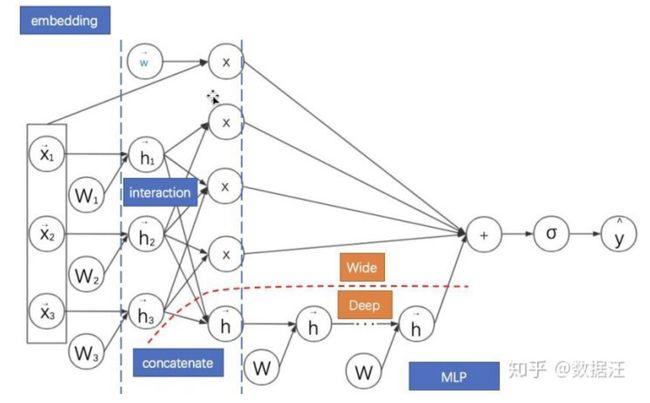
(4)Wide&Deep
把单输入层的Wide部分和经过多层感知机的Deep部分连接起来一起输入最终的输出层。其中Wide部分主要是让模型具有记忆性(Memorization),单层的Wide部分善于处理大量稀疏的id类特征,便于让模型直接‘记住’用户的大量历史信息;Deep部分的主要作用是让模型具有‘泛化性’(Generalization),利用MLP表达能力强的特点,挖掘藏在特征背后的数据模式。最终利用LR输出层将二者结合成统一的End-to-end模型

尽管Wide&Deep模型中Wide部分仍然需要手工特征组合,但是其对于之后模型有重大影响:大量深度学习模型采用了两部分甚至更多部分组合的形式,利用不同网络结构挖掘不同的信息后进行组合,充分结合了不同网络结构的特点。例如:已经得到广泛应用的DeepFM模型即是将Wide&Deep模型的Wide部分进行改进,如下图可以清晰看出广义Wide&Deep模型的基础性作用
(5)地基之上的百花齐放
*1*基于深度学习的CTR预测模型按模型内部组件的功能可以划分为以下四个模块:输入模块,嵌入模块,特征提取模块,预测输出模块

*2*一些经典模型的极简概括:
FM其实是对嵌入特征进行两两内积实现特征的二阶(低阶组合);FNN在FM的基础上引入了MLP,但仍需要预训练;DeepFM通过联合训练、嵌入特征共享来兼顾FM部分(Wide部分)与MLP部分(Deep部分)不同的特征组合机制;NFM,PNN则是通过改造向量积的方式来延迟FM的实现过程,在其中添加非线性成分来提升模型表现力;AFM则更进一步,直接通过子网络来对嵌入向量的两两逐元素乘积进行加权求和,以实现不同组合的差异化,本质上仍然是延迟FM实现的一种方式;DCN则是将FM进行高阶特征组合的方向上进行推广,并结合MLP的全连接式的高阶特征组合机制;Wide&Deep是兼容手工特征组合与MLP的特征组合方式,是许多模型的基础框架;Deep Cross是引入残差网络机制的前馈神经网络,给高维的MLP特征组合增加了低维的特征组合形式
*3*切中肯綮的一张图

Part 3 Main Focus
由于各位前辈已经深入解读过这两篇论文,本白理解肯定是没有各位前辈深刻的,一些内容由于实际跑代码的设备不行也没有真正体会到工程问题的精髓,在这里就不强行解读了,通过阅读百家之言,我贴出来我认为质量比较高的论文解读地址,本部分仅对模型进行概述,并使用DeepCTR进行样例实现
DeepCTR是一个使用keras实现了多个基于深度学习的CTR预估模型的包,结构明细,非常适合从统一的观点来观察多种基于深度学习的CTR预估模型,并进行简单的实验和比较
setup方法详见:GitHub - shenweichen/DeepCTR: Easy-to-use,Modular and Extendible package of deep-learning based CTR models.
1. Deep Interest Network(DIN)
论文地址:[1706.06978] Deep Interest Network for Click-Through Rate Prediction
解读地址:CTR预估专栏 | 一文搞懂阿里Deep Interest Network - 掘金
(1)概述
深度兴趣网络(DIN)针对电子商务领域的CTR预估问题,重点在于充分挖掘用户历史行为数据中的信息。在互联网电商领域中,用户的兴趣具有两个重要特点:Diversity(用户兴趣非常广泛)和Local Activation(针对于一则信息,用户点击与否取决于历史行为数据中的一小部分而非全部)。同时,由于实际应用场景中数据量庞大,因此对模型训练造成了一定困难。针对以上问题,这篇论文给出了解决方法:1.使用用户兴趣分布来表示用户多种多样的兴趣爱好;2.引入Attention机制来实现Local Activation;3.针对于模型训练,提出了DICE激活函数和自适应正则,显著提升了模型性能与收敛速度
(2)使用DeepCTR的样例实现
DIN_by_lilv
其中使用的是人工生成的简单样例数据,如果感兴趣的话可以换成亚马逊数据集试一下,最好使用Musical Instruments Subset,其数据量单机跑比较合适
历史行为数据,物品属性数据,DIN_preprocessing_by_lilv(数据预处理)
2. xDeepFM
论文地址:[1803.05170] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
解读地址:https://blog.csdn.net/roguesir/article/details/80106672
(1)概述
xDeepFM主要是针对DCN的改进。例如FNN、PNN和DeepFM,其缺点是模型学习出的是隐式的交互特征,其形式是未知的、不可控的;同时它们的特征交互是发生在元素级(bit-wise)而不是特征向量之间(vector-wise),这一点违背了因子分解机的初衷。DCN模型,旨在显式(explicitly)地学习高阶特征交互,其优点是模型非常轻巧高效,但缺点是最终模型的表现形式受限制于一种特殊的向量扩张,同时特征交互依旧是发生在元素级上。为了实现自动学习显式的高阶特征交互,同时使得交互发生在向量级上,xDeepFm提出了压缩交互网络Compressed Interaction Network(CIN)。CIN是一种类似于RNN+CNN的结构,也是本篇论文的主要贡献
(2)使用DeepCTR的样例实现
xDeepFM_by_lilv
References
项亮-《推荐系统实践》
https://blog.csdn.net/nicajonh/article/details/79657317
协同过滤推荐算法总结 - 刘建平Pinard - 博客园
recommenders/evaluation.ipynb at master · microsoft/recommenders · GitHub
业界 | 从FM推演各深度CTR预估模型(附代码) - 知乎
DeepCTR:易用可扩展的深度学习点击率预测算法包 - 知乎
Deep Learning 可以用来做推荐系统吗? - 知乎