文本处理工具
cat
1.cat test1 # 查看test1文本内容
![]()
2.cat -E test1 # -E 查看文本时显示文本中的liux换行符$

3.cat -V test2.txt # -v 查看windows文本时显示Windows中的换行符^M
4.cat -T test1 # -T 显示TAB

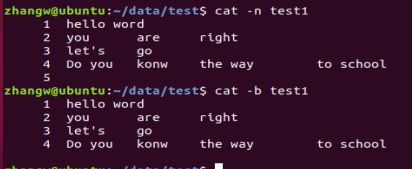
5.cat -n test1 # -n 显示行号

6.cat -b test1 # -b 显示行号,不显示空行
7.cat -s test1 # -s 压缩连续空行为一行

tac
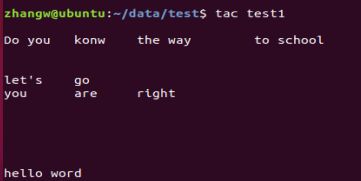
tac test1 # tac的功能只有一个,倒序显示文本内容
rev
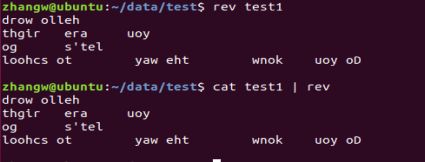
rev test1 # rev的功能只有一个,每行都倒序,【支持管道】
head
1.cat test1 | head -2 # -n 打印文本开头的n行
![]()
2.cat test1 | head -c n # -c n 取一段字符的前n字节

tail
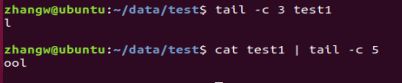
1.-n 打印文本结尾的n行 【支持管道】

2.-c n 取一段字符的后n字节 【支持管道】
cut
cut即是剪切的意思,剪切文本中的内容,一般常用的选项有四个,而,-d,-f,一般连用
1. cat test1 | cut -d' ' -f2 # -d -f 连用 -d后面跟分隔符(' '),-f后面跟列数(2) # 意思是根据分隔符剪切对应列数的内容
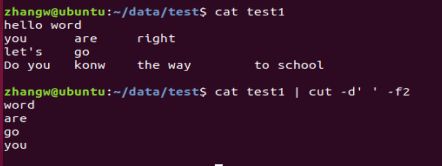
2.-f 后面可以跟范围
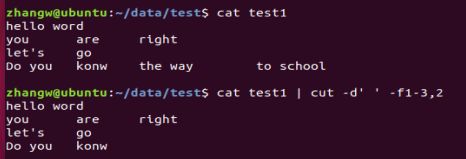
3.-c m/m-n/m-n,k取出字符串中第m/m-n/m-n,k字符
![]()
paste
1.单独使用,合并文件

2. paste -d'Q' test1 test2 # -d'Q',合并后以Q作为分隔符
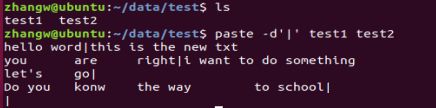
3.paste -s test1 test2 # -s 合并后将多行内容变为一行
![]()
wc
1.wc -l # 显示文本行数
![]()
2.wc -m # 显示文本字符数
![]()
3.wc -c # 显示文本字节数
![]()
4.wc -w # 显示文本单词数
![]()
5.wc -L # 显示文本中最长行的行数
![]()
正则表达式
基本正则表达式(BRE,basic regular expression)
只承认的元字符有^$.[]*其他字符识别为普通字符:\(\)
使用[ ]来查询集合字符
1.[abc] # 匹配一个集合,但只匹配一次,例如:

2.[^abc] # 匹配一个集合取反,也只匹配一次

3.[a-c] # 匹配a-c之间的任意一个字符,只匹配一次

4.[^a-z1-4] # 匹配a-z,1-4之间的任意一个字符取反,只匹配一次

行首与行尾字符^$
任意一个字符.与重复字符*
1. . 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。

2. * 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。

其他特殊字符
() 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。
+ 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。
[ 标记一个中括号表达式的开始。要匹配 [,请使用 \[。
? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。
\ 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。
{ 标记限定符表达式的开始。要匹配 {,请使用 \{。
| 指明两项之间的一个选择。要匹配 |,请使用 \|。
常用正则表达式总结
-
- 数字:^[0-9]*$
- n位的数字:^\d{n}$
- 至少n位的数字:^\d{n,}$
- m-n位的数字:^\d{m,n}$
- 零和非零开头的数字:^(0|[1-9][0-9]*)$
- 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
- 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
- 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
- 汉字:^[\u4e00-\u9fa5]{0,}$
- 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
- 长度为3-20的所有字符:^.{3,20}$
- 由26个英文字母组成的字符串:^[A-Za-z]+$
- 由26个大写英文字母组成的字符串:^[A-Z]+$
- 由26个小写英文字母组成的字符串:^[a-z]+$
- 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
- 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
- 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
- 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
- 禁止输入含有~的字符:[^~\x22]+
- Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
- 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
- URL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
- 手机号码:
^[1][3,4,5,7,8][0-9]{9}$ - 18位身份证:^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{4}$
- 短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
- 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
- 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
- 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
- 日期格式:^\d{4}-\d{1,2}-\d{1,2}
- 中文字符的正则表达式:[\u4e00-\u9fa5]
- IP地址:((\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.){3}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)
vim
vim编辑器是所有Unix及Linux系统下标准的编辑器,是vi的升级版
基本概念
1.命令行模式(command mode)
控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 last line mode。
2.插入模式(Insert mode)
只有在Insert mode下,才可以做文字输入,按ESC键可回到命令行模式。
3.底行模式(last line mode)
将文件保存或退出vi,也可以设置编辑环境,如寻找字符串、列出行号……等。
不过一般我们在使用时把vi简化成两个模式,就是将底行模式(last line mode)也算入命令行模式(command mode)。
基本操作
1.进入vim
在系统提示符号输入vim及文件名称后,就进入vi全屏幕编辑画面
# vim filename
vi之后处于命令行模式,您要切换到插入模式才能够输入文字。
2.切换至插入模式(Insert mode)编辑文件
在命令行模式下按一下字母i就可以进入插入模式,输入文字了。
3.Insert 的切换
处于插入模式,您就只能一直输入文字,如果您发现输错了字!想用光标键往回移动,将该字删除,就要先按一下ESC键转到命令行模式再删除文字。
4.退出vi及保存文件
在命令行模式下,按一下:冒号键进入底行模式,例如:
: w filename (输入w filename将文章以指定的文件名filename保存)
: wq (输入wq,存盘并退出vi)
: q! (输入q!, 不存盘强制退出vi)
命令行模式功能键
1.插入模式
按「i」切换进入插入模式,按"i"进入插入模式后是从光标当前位置开始输入文件;
按「a」进入插入模式后,是从目前光标所在位置的下一个位置开始输入文字;
按「o」进入插入模式后,是插入新的一行,从行首开始输入文字。
2.从插入模式切换为命令行模式
按ESC键。
3.移动光标
vi可以直接用键盘上的光标来上下左右移动,但正规的vi是用小写英文字母「h」、「j」、「k」、「l」,分别控制光标左、下、上、右移一格。
按「ctrl」+「b」:屏幕往"后"移动一页。
按「ctrl」+「f」:屏幕往"前"移动一页。
按「ctrl」+「u」:屏幕往"后"移动半页。
按「ctrl」+「d」:屏幕往"前"移动半页。
按数字「0」:移到文章的开头。
按「G」:移动到文章的最后。
按「$」:移动到光标所在行的"行尾"。
按「^」:移动到光标所在行的"行首"
按「w」:光标跳到下个字的开头
按「e」:光标跳到下个字的字尾
按「b」:光标回到上个字的开头
按「#l」:光标移到该行的第#个位置,如:5l,56l。
4.删除文字
「x」:每按一次,删除光标所在位置的"后面"一个字符。
「#x」:例如,「6x」表示删除光标所在位置的"后面"6个字符。
「X」:大写的X,每按一次,删除光标所在位置的"前面"一个字符。
「#X」:例如,「20X」表示删除光标所在位置的"前面"20个字符。
「dd」:删除光标所在行。
「#dd」:从光标所在行开始删除#行
5.复制
「yw」:将光标所在之处到字尾的字符复制到缓冲区中。
「#yw」:复制#个字到缓冲区
「yy」:复制光标所在行到缓冲区。
「#yy」:例如,「6yy」表示拷贝从光标所在的该行"往下数"6行文字。
「p」:将缓冲区内的字符贴到光标所在位置。注意:所有与"y"有关的复制命令都必须与"p"配合才能完成复制与粘贴功能。
6.替换
「r」:替换光标所在处的字符。
「R」:替换光标所到之处的字符,直到按下「ESC」键为止。
7.恢复上一次操作
「u」:如果您误执行一个命令,可以马上按下「u」,回到上一个操作。按多次"u"可以执行多次回复。
8.更改
「cw」:更改光标所在处的字到字尾处
「c#w」:例如,「c3w」表示更改3个字
9.跳至指定的行
「ctrl」+「g」列出光标所在行的行号。
「#G」:例如,「15G」,表示移动光标至文章的第15行行首。
Last line mode下命令简介
在使用「last line mode」之前,请记住先按「ESC」键确定您已经处于「command mode」下后,再按「:」冒号即可进入「last line mode」。
1.列出行号
「set nu」:输入「set nu」后,会在文件中的每一行前面列出行号。
2.跳到文件中的某一行
「#」:「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,再回车,就会跳到文章的第15行。
3.查找字符
「/关键字」:先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往后寻找到您要的关键字为止。
「?关键字」:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往前寻找到您要的关键字为止。
4.保存文件
「w」:在冒号输入字母「w」就可以将文件保存起来。
5.离开vi
「q」:按「q」就是退出,如果无法离开vi,可以在「q」后跟一个「!」强制离开vi。
「qw」:一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件。
vi命令列表
h 左移光标一个字符
l 右移光标一个字符
k 光标上移一行
j 光标下移一行
^ 光标移动至行首
0 数字"0",光标移至文章的开头
G 光标移至文章的最后
$ 光标移动至行尾
Ctrl+f 向前翻屏
Ctrl+b 向后翻屏
Ctrl+d 向前翻半屏
Ctrl+u 向后翻半屏
i 在光标位置前插入字符
a 在光标所在位置的后一个字符开始增加
o 插入新的一行,从行首开始输入
ESC 从输入状态退至命令状态
x 删除光标后面的字符
#x 删除光标后的#个字符
X (大写X),删除光标前面的字符
#X 删除光标前面的#个字符
dd 删除光标所在的行
#dd 删除从光标所在行数的#行
yw 复制光标所在位置的一个字
#yw 复制光标所在位置的#个字
yy 复制光标所在位置的一行
#yy 复制从光标所在行数的#行
p 粘贴
u 取消操作
cw 更改光标所在位置的一个字
#cw 更改光标所在位置的#个字
w filename 储存正在编辑的文件为filename
wq filename 储存正在编辑的文件为filename,并退出vi
q! 放弃所有修改,退出vi
set nu 显示行号
grep
grep是linux下一个强大的搜索工具,缺点是不能对搜索结果进行修改
1.查找指定进程,-c统计查找结果个数
![]()
2.查看多个文件相同的部分
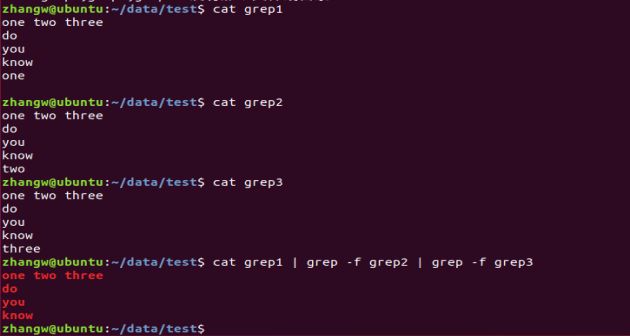
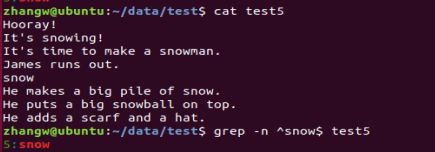
3.从单个和多个文件查找指定内容并显示行号
![]()
4.指定字符查找开头,非开头,结尾的内容
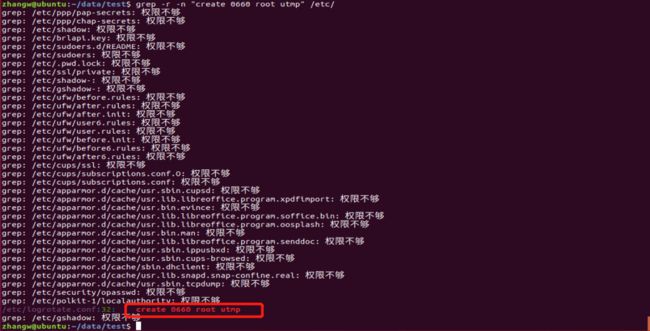
5.过滤指定文件下所有包含指定字符内容
sed
常用参数:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g
sed的工作流程:
1:sed默认不编辑原文件,而是逐行操作,复制一份到指定内存(pattern space,模式空间)
2:pattern space内进行模式匹配,即和指定条件做匹配
不满足模式:输出到标准输出STDOUT
满足模式:进行指定的模式操作,再输出到STDOUT
3:第二个特殊的内存空间 :保持空间(hold space),临时保存操作在另一处内存
4:当执行pattern space和 hold space相关选项时候会进行之间的数据流编辑操作
5:最后根据操作执行hold space空间操作,选择性显示到STDOUT
应用实例:
1.指定行区间查找以root开头的内容
![]()
2.显示第一次匹配到back到最后一行输出
![]()
3.显示第一次匹配到syn到下一行输出
![]()
4.文本逆向排序输出

5.显示行号,屏蔽空行和不屏蔽空行
屏蔽空行:sed '=' passwd
不屏蔽空行:sed '/./=' passwd

6.显示文件总行数
![]()
7.显示奇数行

8.显示偶数行

9.文件中每行内容逆向显示

10.将数字按科学计数法(个十百)显示

11.删除1-5行内容

12.删除奇数行
![]()
13.删除空行

14.将root全部替换为mysql

15.将root替换为nginx,如果对应行中未出现sbin

awk
awk是通过列来匹配,sed是通过行来匹配,awk支持for循环嵌套,拓展性强
常用命令选项:
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
-v var=value 赋值一个用户定义变量,将外部变量传递给awk
-f scripfile 从脚本文件中读取awk命令
-m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
内置变量:
FS 保存或设置分隔符,例如FS=",";
$N 指定分隔符的第N个字段,例如$1,$5代表第一列和第三列;
$0 当前读入整行的文本内容;
NF 记录当前处理行的字段个(列)数;
NR 记录当前处理行的数量;
FNR 保存当前处理行在原文本内的行号;
FILENAME 当前处理的文本名;
ENVIRON 调用shell环境变量。
1.列基本查询
$0代表所有列,$1代表第一列

2.当前内容过滤

3.统计每行有多少列

4.分别统计多个文件有多少行

5.统计uid小于30和大于30的用户各有多少
![]()
6.统计指定字段(root)出现的次数
![]()