介绍
“The world’s best economies are directly linked to a culture of encouragement and positive feedback.”
你能猜到上面那句话是谁说的吗?这并不是某位总统或首相,当然也不是像Raghuram Rajan那样的顶尖经济学家说出来的。
这句话是由我们的机器产生的!是的,你没听错,这是一个在OpenAI的GPT-2框架上训练的自然语言处理(NLP)模型训练“说出”了这句话。所以你现在觉得机器学习的状态完全在另一个层次上了吗?
在NLP真正的黄金时代,OpenAI的GPT-2改变了我们处理文本数据的方式。ULMFiT和谷歌的BERT轻松地为NLP爱好者打开了大门,而GPT-2则打破了这一局面,使NLP任务(主要是文本生成)的工作变得更加容易。
在本文中,我们将使用GPT-2构建我们自己的文本生成器。
有没有一点小期待呢?让我们开始进入正文。我们将首先直观理解GPT-2,然后直接进入Python构建文本生成模型。
另外,如果你是一个狂热的NLP追随者,我想你会喜欢下面关于NLP最新发展的指南和教程:
8个优秀的预训练模型
Transformers介绍
PyTorch-Transformers介绍
StanfordNLP介绍
OpenAI的GPT-2框架有什么新特性?
自然语言处理(NLP)在过去的几年里以惊人的速度发展,机器现在能够理解句子背后的语境,当你思考这个问题时,你会发现这是一个真正具有里程碑意义的成就。
由OpenAI开发的GPT-2是一个预训练语言模型,我们可以使用它来完成各种NLP任务,比如:
- 文本生成
- 语言翻译
- 建立问答系统等等
语言模型(LM)是现代自然语言处理的重要任务之一。语言模型是预测文档中下一个单词或字符的概率模型。

GPT-2是OpenAI最初的NLP框架GPT的继承者,完整的GPT-2模型有15亿个参数,几乎是GPT参数的10倍。正如你可能已经猜到的那样,GPT-2给出了最先进的结果(稍后我们将会看到)。
这个预训练的模型包含了从Reddit的出站链接中收集的800万个网页的数据。让我们花一分钟来了解一下GPT-2是如何工作的。
架构
GPT-2的架构是基于谷歌在他们的论文“Attention is all you need”中提出的非常著名的Transformers概念。Transformers提供了一种基于编码器和解码器的机制来检测输入输出依赖关系。
在每个步骤中,模型在生成下一个输出时,将前面生成的符号作为额外的输入使用。
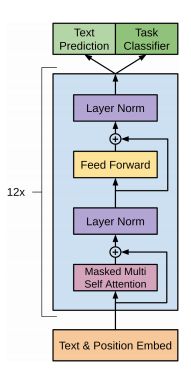
除了有更多的参数和Transformers层外,GPT-2只有少量架构修改:
- 模型使用更大的上下文和词汇量
- 在最后一个self-attention块之后,添加了一个额外的normalization层
- 与“building block”类型的残差学习单元类似,将层规范化移动到每个子块的输入。它在权重层之前应用批量标准化,这与原来的“bottleneck”类型不同
"GPT-2在各种领域特定的语言建模任务上取得了最先进的成绩。我们的模型不是针对任何特定于这些任务的数据进行训练的,而是作为最终测试对它们进行评估,这就是所谓的zero-shot设置。当对相同的数据集进行评估时,GPT-2的性能优于针对领域特定数据集(如Wikipedia、news、books)训练的模型。"
--OpenAI团队
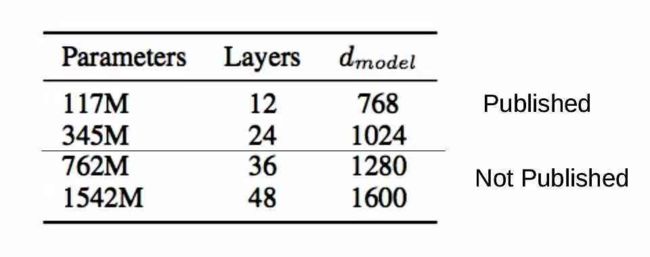
训练了四种不同参数的模型,以适应不同的场景:
GPT-2能够基于小的输入语句生成整篇文章,这与早期的NLP模型形成了鲜明的对比,早期的NLP模型只能生成下一个单词,或者在一个句子中找到缺失的单词。
下面是GPT-2如何与其他类似的NLP模型进行比较:
| Base model | pre-training | Downstream tasks | Downstream model | Fine-tuning | |
|---|---|---|---|---|---|
| GPT | Transformer decoder | unsupervised | model-based | task-agnostic | pre-trained layers + top task layer(s) |
| BERT | Transformer encoder | unsupervised | model-based | task-agnostic | pre-trained layers + top task layer(s) |
| GPT-2 | Transformer decoder | unsupervised | model-based | task-agnostic | pre-trained layers + top task layer(s) |
如何配置GPT-2所需环境:
我们将使用具有3.45亿个参数的中型模型。你可以从官方的OpenAI GitHub存储库下载预培训的模型。
首先,我们需要通过输入下面的语句来克隆存储库(我建议使用Colab notebook而不是本地机器来加快计算速度):
!git clone https://github.com/openai/gpt-2.git
注意,我们需要更改目录。为此,我们将使用os类的chdir():
import os
os.chdir("gpt-2")
接下来,选择我们所需要的模型。在本例中,我们将使用一个包含3.45亿个参数的中型模型。
这个模型需要使用GPU支持的TensorFlow来使它运行得更快。让我们在notebook上安装TensorFlow:
!pip3 install tensorflow-gpu==1.12.0
在进入建模部分之前,我们想要满足一些基本的需求。在克隆下来的文件夹中,你将找到一个文件- requirements.txt。文件包括以下四个库,这些库是这个模型必须要使用的:
- fire>=0.1.3
- regex==2017.4.5
- requests==2.21.0
- tqdm==4.31.1
安装所有这些库只需一行代码:
!pip3 install -r requirements.txt
就是这样,我们都已经配置好的我们的环境。在我们进入构建文本生成器之前还需进行最后一步的操作,就是下载中型预训练模型!同样,我们可以用一行代码做到这一点:
!python3 download_model.py 345M
根据你的网络带宽,这将花费一些时间。一旦下载完成了,我们需要用以下代码进行编码:
!export PYTHONIOENCODING=UTF-8
用Python实现GPT-2来构建我们自己的文本生成器
你准备好了吗?因为这是我们最终要实现的事情:使用GPT-2在Python中构建我们自己的高级文本生成器了!所以让我们开始吧。
首先,像之前一样使用chdir()移动到src文件夹:
os.chdir('src')
然后,导入所需的库:
import json
import os
import numpy as np
import tensorflow as tf
import model, sample, encoder
注意:model、sample和encoder是GPT-2文件夹的src子文件夹中出现的Python文件:
def interact_model(
model_name,
seed,
nsamples,
batch_size,
length,
temperature,
top_k,
models_dir
):
models_dir = os.path.expanduser(os.path.expandvars(models_dir))
if batch_size is None:
batch_size = 1
assert nsamples % batch_size == 0
enc = encoder.get_encoder(model_name, models_dir)
hparams = model.default_hparams()
with open(os.path.join(models_dir, model_name, 'hparams.json')) as f:
hparams.override_from_dict(json.load(f))
if length is None:
length = hparams.n_ctx // 2
elif length > hparams.n_ctx:
raise ValueError("Can't get samples longer than window size: %s" % hparams.n_ctx)
with tf.Session(graph=tf.Graph()) as sess:
context = tf.placeholder(tf.int32, [batch_size, None])
np.random.seed(seed)
tf.set_random_seed(seed)
output = sample.sample_sequence(
hparams=hparams, length=length,
context=context,
batch_size=batch_size,
temperature=temperature, top_k=top_k
)
saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(os.path.join(models_dir, model_name))
saver.restore(sess, ckpt)
while True:
raw_text = input("Model prompt >>> ")
while not raw_text:
print('Prompt should not be empty!')
raw_text = input("Model prompt >>> ")
context_tokens = enc.encode(raw_text)
generated = 0
for _ in range(nsamples // batch_size):
out = sess.run(output, feed_dict={
context: [context_tokens for _ in range(batch_size)]
})[:, len(context_tokens):]
for i in range(batch_size):
generated += 1
text = enc.decode(out[i])
print("=" * 40 + " SAMPLE " + str(generated) + " " + "=" * 40)
print(text)
print("=" * 80)
让我们一个一个地来理解这些参数:
- model_name:这表示我们使用的是哪个模型。在本例中,我们使用具有3.45亿个参数或权重的GPT-2模型
- seed: 整数seed用于随机数生成器,固定seed用于再现结果
- nsamples: 这表示在输出中生成的示例文本的数量
- batch_size: 这只影响速度/内存,也必须除以nsamples
注意:要生成多个示例,你需要更改nsamples和batch_size的值,并且还必须保持它们相等
- length: 它表示生成的文本中标记的数量。如果长度为零,则标记的数量由模型超参数决定
- temperature: 这控制了玻尔兹曼分布的随机性。较低的temperature导致较低的随机性。当temperature接近于零时,该模型将变得具有确定性和重复性。更高的temperature导致更高的随机性
- top_k: 这个参数控制多样性。如果top_k的值设置为1,这意味着每个步骤(标记)只考虑一个单词。如果top_k被设置为40,这意味着每一步要考虑40个单词。0(默认值)是一个特殊的设置,意思是没有限制。top_k = 40通常是一个好值
- models_dir: 它表示包含模型子文件夹的父文件夹的路径(包含
文件夹)
现在,是时候见证最先进的语言模型所产生的结果了。让我们运行这个函数并生成一些文本:
interact_model(
'345M',
None,
1,
1,
300,
1,
0,
'/content/gpt-2/models'
)
现在将要求你输入一个字符串。这是我所输入的内容:
I went to a lounge to celebrate my birthday and
而下面是GPT-2文本生成器的输出结果:
I called Donna and told her I had just adopted her. She thought my disclosure was a donation, but I’m not sure if Donna met the criteria. Donna was a genuinely sweet, talented woman who put her life here as a love story. I know she thanked me because I saw her from the photo gallery and she appreciated my outrage. It was most definitely not a gift. I appreciate that I was letting her care about kids, and that she saw something in me. I also didn’t have much choice but to let her know about her new engagement, although this doesn’t mean I wasn’t concerned, I am extremely thankful for all that she’s done to this country. When I saw it, I said, “Why haven’t you become like Betty or Linda?” “It’s our country’s baby and I can’t take this decision lightly.” “But don’t tell me you’re too impatient.” Donna wept and hugged me. She never expresses milk, otherwise I’d think sorry for her but sometimes they immediately see how much it’s meant to her. She apologized publicly and raised flagrant error of judgment in front of the society of hard choices to act which is appalling and didn’t grant my request for a birth certificate. Donna was highly emotional. I forgot that she is a scout. She literally didn’t do anything and she basically was her own surrogate owner. August 11, 2017 at 12:11 PM Anonymous said…
Incredible!当我第一次看到这个结果时,我无言以对。令人难以置信的细节处理水平和语法——几乎没法相信它完全是由一台机器生成的,难道不是吗?
你也可以继续操作输入其他句子,并在评论中分享你得到结果。
关于GPT-2潜在误用的说明
GPT-2因其可能的恶意使用而出现在新闻报导中。你可以想象这个NLP框架是多么强大。它很容易被用来生成假新闻,或者坦白地说,任何假文本,而人类无法意识到其中的区别
考虑到这些,OpenAI并没有发布完整的模型。相反,他们发布了一个小得多的模型。最初的模型是在40GB的互联网数据上训练的,有15亿个参数。OpenAI发布的两个示例模型有1.17亿个参数和3.45亿个参数。
结语
在本文中,我们使用了具有3.45亿参数的中型模型。这些小型的模型就能够产生如此令人印象深刻的结果,那想象一下一个包含15亿个参数的完整模型能产生什么,是不是觉得既可怕又刺激。