目标:
爬取某8的一页商品信息,介于老师给的网址全是转转信息因此我自己选择了一个卖狗的页面(捂脸)
界面如下:(排除了心宠的所有推广)
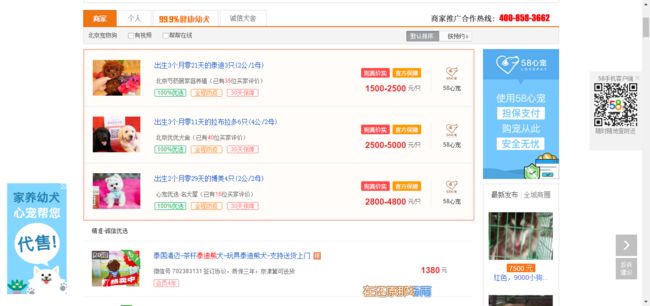
网页截图
我们需要爬取商家和个人两个部分的详情页信息
爬取结果:
个人详情页网址

商家详情页网址
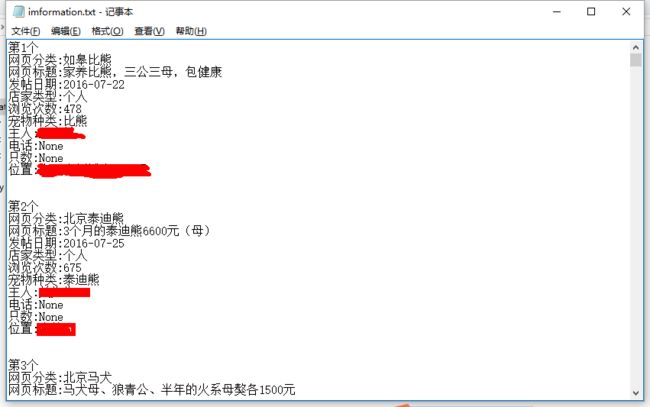
个人部分信息
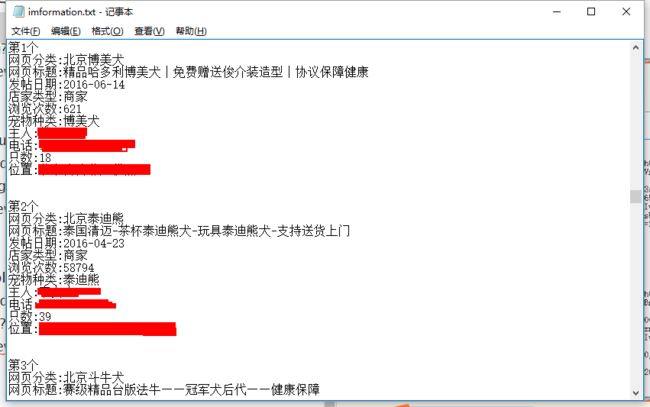
商家部分信息
难点
- 浏览人数的爬取
- 爬取的网址跟跳转的网址不同
- 不同网页完善的信息不同(比如有的有电话有的没有)
- 个人和商家版的详情页元素位置有轻微区别(比如同一个位置会存放不同内容信息)
- 爬取的文本有大量/t/r/n的信息
- 挑战自己爬了下需要点击才能显示的电话号码
代码
from bs4 import BeautifulSoup
import time
import requests
def get_urls(path,name_num):
respond = requests.get(path)
soup = BeautifulSoup(respond.text, 'lxml')
pre_urls = soup.select('''td.t > a[onclick="clickLog('from=pc_cwgou_list_wenzi');"]''')
i = 0
urls = []
file = open('./urls{}.txt'.format(name_num),'a')
for url in pre_urls:
i = i + 1
href = url.get('href')
urls.append(href)
text = url.get_text()
print(i,' ',href,text)
file.write(str(i)+' '+ href +'\n'+text+'\n\n')
file.close()
return urls
def get_views(url):
time.sleep(2)
get_num1 = url.split('x.shtml')
get_num2 = get_num1[0].split('dog/')[-1]
api = 'http://jst1.58.com/counter?infoid={}'.format(get_num2)
headers = {
'Referer':'http://m.58.com/tj/dog/{}'.format(get_num2),
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1'
}
js = requests.get(api,headers = headers)
views = js.text.split('total=')[-1]
return views
def detail (path, count, Hkind_judge) :
respond = requests.get(path)
views = get_views(respond.url)
soup = BeautifulSoup(respond.text,'lxml')
url_kind = soup.select('#header > div.breadCrumb.f12 > span:nth-of-type(4) > a')
kind = soup.select('body > div.content_quanbu > div.zhanshi_top.clearfix > div.zhanshi_top_l.fl.clearfix > div.col_sub.sumary.fl > ul > li:nth-of-type({}) > div.su_con > span:nth-of-type(1)'.format(3 if Hkind_judge == 0 else 4))
title = soup.select('body > div.content_quanbu > div.col_sub.mainTitle > div > h1')
date = soup.select('#index_show > ul.mtit_con_left.fl.clearfix > li.time.fl > span')
num = soup.select('span.zhishu')
pos = soup.select('span.dizhi')
host = soup.select('span.lianxiren > a')
phone = soup.select('#t_phone')
if Hkind_judge == 0:
host_kind = '个人'
elif Hkind_judge == 1:
host_kind = '商家'
else:
host_kind = '未知'
list = [
'网页分类:'+ url_kind[0].get_text() if url_kind else '网页分类:None',
'网页标题:'+ title[0].get_text() if title else '网页标题:None',
'发帖日期:'+ date[0].get_text() if date else '发帖日期:None',
'店家类型:'+ host_kind,
'浏览次数:'+ views,
'宠物种类:'+ kind[0].get_text().replace('\t', '').replace('\n','').replace(' ','') if kind else '宠物种类:None',
'主人:'+ host[0].get_text() if host else '主人:None',
'电话:'+ phone[1].get_text() if len(phone) > 1 else '电话:None',
'只数:'+ num[0].get_text() if num else '只数:None',
'位置:'+ pos[0].get_text() if pos else '位置:None'
]
print(list)
file_path = './imformation.txt'
file = open(file_path, 'a')
file.write('第'+str(count)+'个\n')
for i in list:
file.write(i+'\n')
file.write('\n\n')
file.close()
path1 = 'http://bj.58.com/dog/1/?PGTID=0d3000fc-0000-13b1-ca3b-4d326020e12d&ClickID=1'
path0 = 'http://bj.58.com/dog/0/?PGTID=0d3000fc-0000-13b1-ca3b-4d326020e12d&ClickID=1'
urls0 = get_urls(path0,'0')
count = 0
for url0 in urls0:
time.sleep(2)
count = count + 1
detail(url0,count,Hkind_judge = 0)
urls1 = get_urls(path1,'1')
count = 0
for url1 in urls1:
time.sleep(2)
count = count + 1
detail(url1, count,Hkind_judge = 1)
其实个人和商家两个部分的网址也是可以用format来做到的,我这里一开始贪图简单没有用循环,但是后期发现很多地方要用到0、1两个变量(包括两份网址txt的命名和商品详情里出处的判断)
总结:
说一下上面难点的解决方案
-
浏览人数:
先打开检查,sources,刷个新,可以找到一个js文件,把这个地址复制下来,进行get请求就可以获得这个js浏览量的返回(即数据部分最后的total = xxxx)
这个文件的Infoid一串数字和网址的id是一致的,因此把网址的id取出来,就可以用fomat批量获取js啦
但是我还遇到一个问题,就是照做了之后还是爬不到,返回total=0,这个时候加个Header的Referer试试就可以
 检查界面
检查界面
def get_views(url):
time.sleep(2)
get_num1 = url.split('x.shtml')
get_num2 = get_num1[0].split('dog/')[-1]
api = 'http://jst1.58.com/counter?infoid={}'.format(get_num2)
headers = {
'Referer':'http://m.58.com/tj/dog/{}'.format(get_num2),
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1'
}
js = requests.get(api,headers = headers)
views = js.text.split('total=')[-1]
return views
- 那么问题来了,要得到网址中的id,但是看我的结果txt,发现爬取的第一个网页是和下面不一样,没有一串数字的,这是因为这是跳转前的网址,我们无法判断得到的网址是否还有一次跳转,所以解决方法是取浏览量之前,取已打开详情页的网址进行分析(已跳转完成的)
respond = requests.get(path)
views = get_views(respond.url)
- 不同网页完善的信息不同,所以一旦没有获取到需要的内容,程序会死掉哦~怎么解决这个问题呢,就因为这个调试到了今天(所以迟交了作业,抱歉)
解决方法是要养成每个信息都要判断是否存在的习惯
突然联系到直播的时候老师有个这样的习惯,在每个获取信息输出之前,会
判断列表是否为空,像这样:if list else None
list = [
'网页分类:'+ url_kind[0].get_text() if url_kind else '网页分类:None',
'网页标题:'+ title[0].get_text() if title else '网页标题:None',
'发帖日期:'+ date[0].get_text() if date else '发帖日期:None',
'店家类型:'+ host_kind,
'浏览次数:'+ views,
'宠物种类:'+ kind[0].get_text().replace('\t', '').replace('\n','').replace(' ','') if kind else '宠物种类:None',
'主人:'+ host[0].get_text() if host else '主人:None',
'电话:'+ phone[1].get_text() if len(phone) > 1 else '电话:None',
'只数:'+ num[0].get_text() if num else '只数:None',
'位置:'+ pos[0].get_text() if pos else '位置:None'
]
我用List存放是为了输出的txt格式好看一点,如果要输出其他的要用字典什么的啦
可以看到个人信息页面很多东西都是None因为他们没有写
- 个人和商家版的详情页元素位置有轻微区别,这个导致我爬品种的时候,总是会一部份显示防疫的内容,一部分显示品种
解决办法是判断当前是商家版还是个人版,改变位置,我这里用format(Hkind_judge是主人类型判断...名字奇怪了点哈)
kind = soup.select('body > div.content_quanbu > div.zhanshi_top.clearfix > div.zhanshi_top_l.fl.clearfix > div.col_sub.sumary.fl > ul > li:nth-of-type({}) > div.su_con > span:nth-of-type(1)'.format(3 if Hkind_judge == 0 else 4))
- 爬取的文本有大量/t/r/n的信息,要怎么删除呢?(说的就是品种信息)
删除的方法其实有很多种,我这里用了最粗暴的repla
'宠物种类:'+ kind[0].get_text().replace('\t', '').replace('\n','').replace(' ','') if kind else '宠物种类:None'
- 挑战自己爬了下需要点击才能显示的电话号码
然后我发现并不难,因为这个没有用js控制,直接就放在网页源码,所以只要判断好它的位置就可以,要小心的是所有select结果都是列表,没把握需要的信息在哪里的,就先print出来
这里遇到的问题其实就是有的详情没有给电话,但是得到的列表依然是有一个值的,所以这里不是判断为空,而是判断元素个数是否大于1
'电话:'+ phone[1].get_text() if len(phone) > 1 else '电话:None'
- 变量名比较混乱抱歉,因为会的单词实在不够多(捂脸),然后也忘了爬价格,不过我觉得价格应该也不难,所以就不管了
这一次大作业确实发现了很多之前的网页不存在的问题,做起来比较辛苦,但是好有成就感~
顺便为了保护,每个请求都加了time.sleep(2)保护,但是这个方法速度实在是慢了点 - 嘛这周的作业也要加油了(づ ̄ 3 ̄)づ