概要
Jan Hosang的建议目标区域总数性文章"What makes effective proposals?"距今有3年了。这三年中产生了一些基于深度卷积网络(可以说,全都是fully conv nets)的object segmentation proposal方法。这些方法产生的分割结果是mask,稍作处理可以得到bbox形式的detection proposal。本文列举其中主要的object segmentation proposal方法。(似乎也叫做instance semantic segmentation?)
已经列举的方法包括:
- DeepMask
- SharpMask
- FPN
- Mask R-CNN
- FastMask
接下来打算写的方法包括: - MNC(Instance-aware Semantic Segmentation via Multi-task Network Cascades)
- InstanceFCN(Instance-sensitive Fully Convolutional Networks)
- FCIS(Fully Convolutional Instance-aware Semantic Segmentation)
本篇不求写的很细,主要按各个算法的关联性、发展关系,把DeepMask/SharpMask/FPN/MaskRCNN/FastMask算法进行简要解读,其中Mask R-CNN只考虑RPN-mask分支。其实这些算法都是Instance-aware sementic segmentation.
DeepMask/SharpMask这两篇文章都是用卷积网执行分割来产生segmentation proposal也即mask的,但是又不仅仅是mask而是同时产生了objectness score,某种程度上可以认为是selective search, mcg等grouping proposal methods的升级版本。两篇文章都是Dollar组出品,无论是行文还是思路都可以感受到Dollar的存在。
DeepMask

要解决什么问题
两阶段的Object Detection已经被证明是成功的检测框架(比如R-CNN,Faster R-CNN系列),而其中第一阶段产生的object proposal则起到了连接两阶段的作用,proposal的好坏非常重要。本文就是提出一种新的Object Proposal方法DeepMask。
相关工作
这个DeepMask是要和谁来PK呢?一方面是bbox作为结果的object detection proposal,这类算法输出的proposal是两个坐标点表示的矩形框盖住的区域,那么像Dollar自己早期的EdgeBoxes,随后被Kuo等人级联一个AlexNet来rerank给改进了,再后来被ShaoqingRen的RPN这个全卷积的sliding widnows建议区域方法干掉了。那么DeepMask就是要对标RPN了。
另一方面要PK的,同时也算是baseline的存在的算法:Selective Search是基于superpixel来聚合出proposal的,MCG是基于Edge Contour来聚合出proposal的,还有Rigor和Geodesdic这两个不是很了解的但是也是这一类的,它们都是产生segmentation格式的proposal,当然也同时有手工设计而算出的object score。相比之下,DeepMask是直接从raw pixel而没有(显式地)使用边缘、超像素等底层特征,是end2end的。
具体方法
其实backbone网络就是一个FCN,只不过增加一个计算objectness score的小分支:
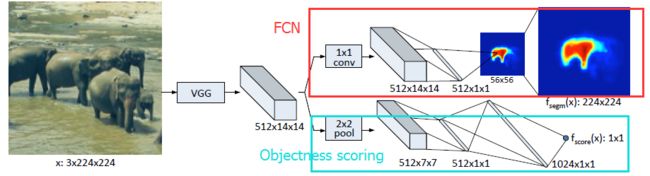
因此整个网络的Loss函数就是mask的loss与objectness loss的和,只不过需要一个lambda来调解:

注意,虽然网络是产生segmentation proposal也即是mask,但是用opencv的findcontour函数就能得到bbox了,得到的bbox就是detection proposal,就可以和EdgeBox、DeepBox等进行比较了。遗憾的是,没有比较RPN,不知道是比不过还是另有原因。
对比结果
Dollar最喜欢画这种华丽丽的曲线了:
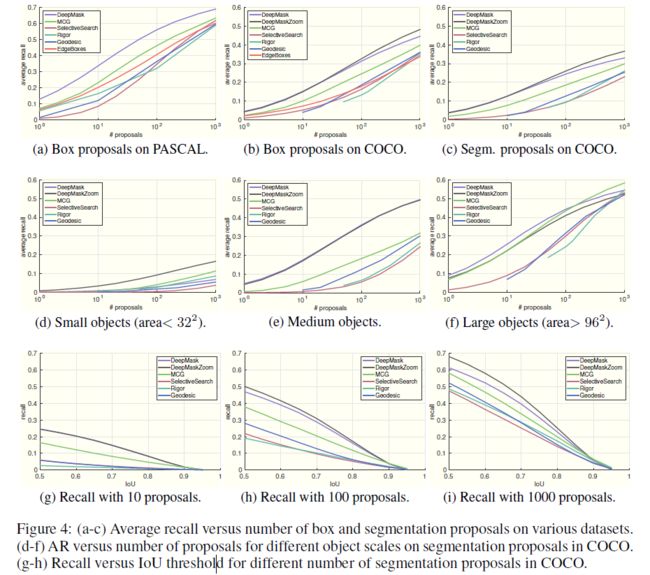
曲线图都有了,表格数据还难么:
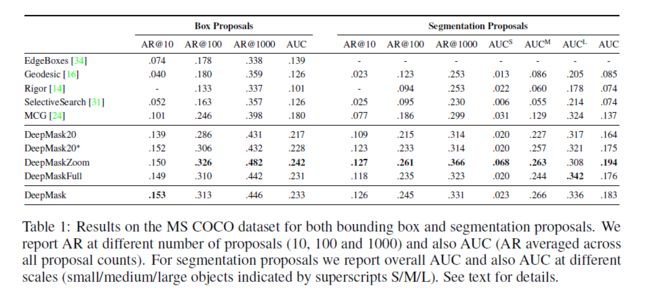
速度上,COCO的图是1.6s一张来做inference, 1.2s一张pascal voc的图。这需要GPU的支持。这速度和Geodestic相比基本差不多,但是既然用了GPU也就说不上优势了。后续的SharkMask改进则比较快。
另外,训练需要5天,on a K40m。可以说,这份工作虽然有开创性,但是我等小弱不想复现啊,太慢了。
SharpMask
总体情况
SharpMask是DeepMask的直接延续工作,原班人马出演(哦不,乱入了一个Tsung-Yi Lin):

要解决什么问题
既然是DeepMask的二代,那么一方面也是解决DeepMask的问题,就是用卷积网产生segmentation proposal(mask)从而提升detection性能(好吧,提升性能是后话,这个算法只负责提升propsal质量);另一方是解决DeepMask的痛点,就是精度还不不够高,速度还不够快。
相关工作
一个算法在baseline基础上提了哪些改进,这些改进的竞争方法就是最related work了。SharpMask想提升精度,方法是多层特征融合,因此它的enemy就是基于FCN做特征融合的一票算法了,再直白一点就是做跨层特征融合的算法都是对手。
其实,这部分related work,和DeepMask本身的网络结构要一起说,才清晰:
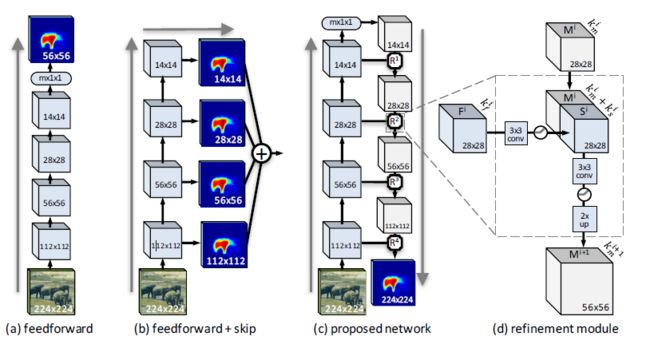
(a)是最naive的一杆到底直愣愣的DeepMask的做法,只有最后一层特征,这层特征肯定是空间信息不足,导致各种细节例如边界或纹理上的预测是不准确的;
(b)是带skip-connection的特征融合方法,是DCNN语义分割开门红算法FCN,以及DCNN边缘检测开门红算法HED的做法,是说每个stage都产生旁路输出,来把stage内产生的特征做放大,然后这些放大的特征再拼接在一起(这样看来,HED和FCN很像,不过考虑到两者都是15年的同期作品还是很有水准的)。(c)SharpMask使用的网络结构,(d)是(c)里面的放大结构。其实这个结构就是“史前FPN”嘛:
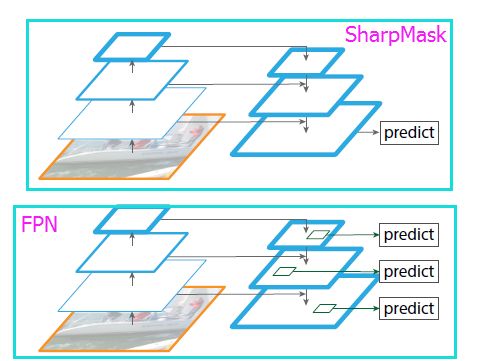
至于具体在related work中作者写了什么,有一大段是讲怎么把特征放大的,各种Deconvolution的方法。
提出的方法
前面已经画出了SharpMask的整体网络结构了。再深入,如果要直观点,那就是head部分的结构了,也就是最后接近各种loss的地方的各种层了:
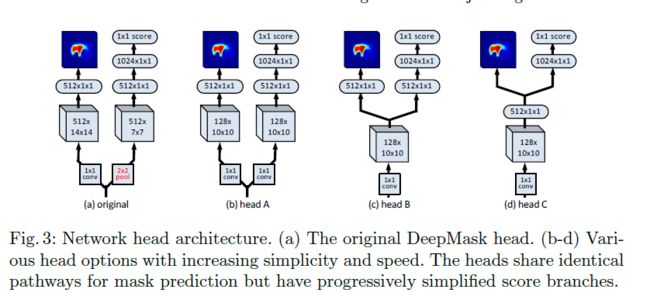
其中(a)是DeepMask还是很naive,(b)则开始把卷积核数量从512改成128,(c)则进一步把两路上的卷积核合并,(d)则更进一步把再深一层的卷积核合并。从这个结构来看,我的连蒙带猜的理解是,虽然multi-task会导致特征不稳定,但是我多放几个层就能一定程度上增加稳定性。。。
结果


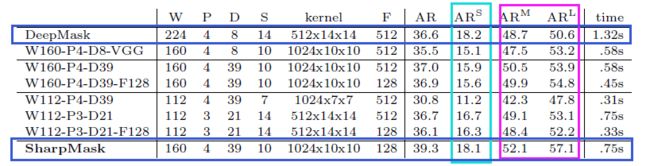
从这个表格显示的数据来看,AR@S没啥变化的,AR@M和AR@L是有提升的;另外就是速度变快了。实际上,SharpMask的推理速度为0.75s,训练时间为2天,比DeepMask快了一倍。(不过我能说还是很慢吗。)
也有和EdgeBoxes和RPN进行比较:

从RPN到SharpMask,提升还是不小的。
FPN

既然SharpMask是FPN的前奏,FPN是基于RPN的改进,干脆把FPN的评测结果贴过来把:
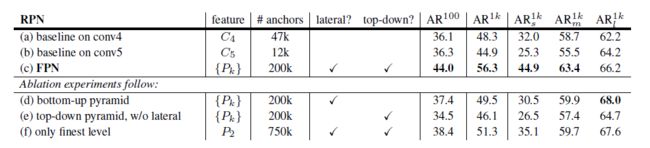
其中baseline on conv5应该就是原版RPN了,只不过用的backbone网络是resnet50而不是vgg16。可以看到FPN比RPN提升了很多,而且主要是在small和medium尺度上的提升。
在FPN文章中,FPN还用于mask的预测,然后和DeepMask/SharpMask/InstanceFCN对比:
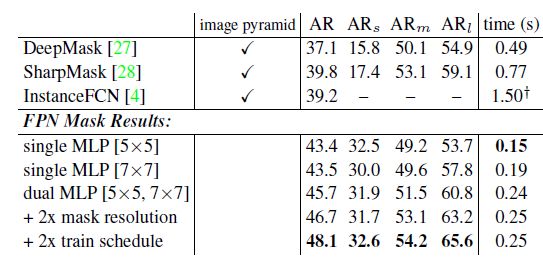
看到这里,我不禁怀疑,Mask R-CNN这个在Faster R-CNN基础上增加mask分支的改进,真的像各种膜拜Kaiming的小菜鸟们想想的那么难、那么有innovation吗?早就在FPN里面做过了啊,最多是说同时执行这两个分支,但是你不觉得multi-task本身也不是新鲜玩意儿吗?因为RPN本身就是一个multi-task,同时执行cls和reg。
Mask R-CNN

看完了FPN,再来看Mask R-CNN,我想说,这个改进其实不难想到吧,毕竟FPN中已经出现过一大半了,只不过把mask和cls、reg同时做而已:
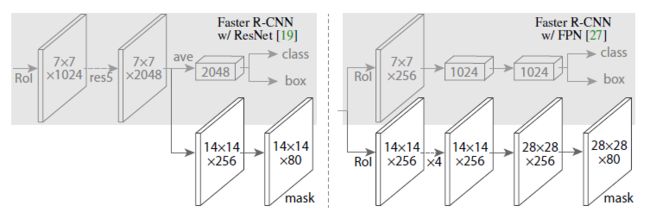
当然,Mask R-CNN还有RoI Align这种好用的trick,以及给出ResNeXt作为backbone网络的对比结果。
FastMask

这次是Face++的工作,是改进SharpMask
解决的问题
好些个顶会论文(如过不是全部的话),只夸自己的好处,不说自己的坏处,或者说提出的算法的缺点只在犄角旮旯提那么一句,而展示提出的算法的图(占据很大空间和视觉显著性区域)里面,则放大别人算法的缺点,放大自己算法的优点,抹掉自己算法的缺点。
吐槽完毕,来说FaskMask解决的问题:多尺度的问题。DeepMask/SharpMask/InstanceFCN都是这个毛病,网络的输入,在inference的时候一定要multi-scale的,也就是构造图像金字塔的。图像金字塔相比于single-scale image的好处,看起来是增加精度,但是你不觉得很反直觉吗?一张图本身难道不应该包含了多个尺度吗?一张图里面有大物体和小物体,但是人眼看到它们的时候应该是同时看到并识别的对不对?
提出的算法
顺着“改掉图像金字塔输入为单尺度输出”的思路,提出了FastMask:在网络里面加入neck结构,然后只用single scale image作为输入即可:
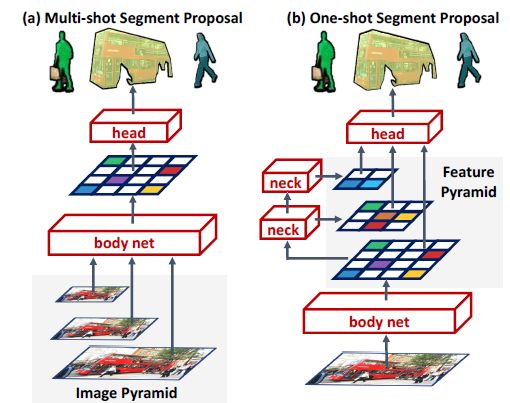
其中(a)multi-shot segment proposals说的就是DeepMask/SharpMask/InstanceFCN之流;(b)则是提出的结构,其中脖子(neck)结构是用残差块的结构来实现的:

另外值得一提的是Attentional Head,之前在ZJU的论文分享会上也特意提到了这个结构带来的细节上的精度提升,主要猜测是因为网络的feature map尺度稀疏,相差2倍(而不是像DeepMask那样的输入的图像金字塔可以自由的去缩放,然后使用了sqrt(2)为缩放因子)。网络结构原理是这样的:

结果
单纯从数据上看其实提升不大,甚至个别指标干不过别家:
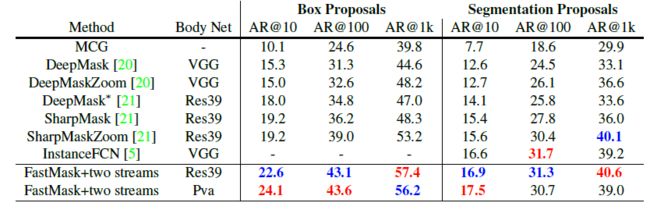
但是速度上很生猛:
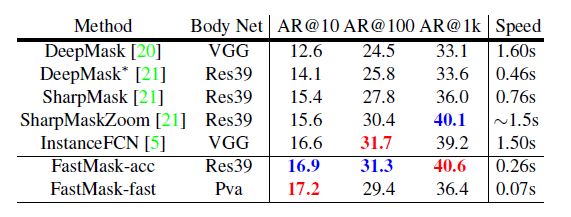
看到了没,别家用1.5s干完的事,Fastmask的fast版本(用了pva作为后端)只需要0.07,如果是res39为后端则也只需要0.26s。