思考:recoketMQ设计有何特点?
kafka和Rocketmq都是分布式的消息系统,在集群化部署方面,kafka通过zk进行节点协调,而rocketmq通过自身namesrv进行节点协调,所以在协调节点的设计上rocket显得更加轻,存储方面,在rocketmq中,采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog)来存储,RocketMQ采用混合型存储结构的缺点在于,会存在较多的随机读操作,因此读的效率偏低。同时消费消息需要依赖ConsumeQueue,构建该逻辑消费队列需要一定开销。
主从备份方面:当生产者者向rocketmq写入消息时,会将数据写入集群中的相关master broker上,而每个master broker都有1到多个slave broker, 这样在一定程度上保证master出现了不可恢复的故障时,不丢失数据。 同时如果master宕机了,消费者会自动重连到相应的salve上,不会出现消费停滞,那么同时在master和slave数据同步分为同步复制(有一定的效率损失)和异步复制(数据不一致)
在生产和消费消息方面:在kafka中,每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处,而这种能力实现的底层我想应该就是通过zk来完成的。 在rocketmq中,NameSrv提供。
研究RocketMQ的一个切入点
其实RocketMQ这个技术一共是包含了四个核心的部分:
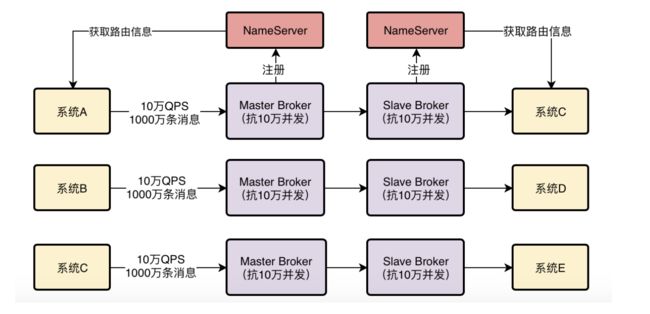
第一块就是他的NameServer,这个东西很重要,他要负责去管理集群里所有Broker的信息,让使用MQ的系统可以通过他感知到集群里有哪些Broker。
第二块就是Broker集群本身了,必须得在多台机器上部署这么一个集群,而且还得用主从架构实现数据多副本存储和高可用。
第三块就是向MQ发送消息的那些系统了,这些系统一般称之为生产者,这里也有很多细节是值得深究的,因为这些生产者到底是如何从NameServer拉取路由信息的?如何选择Broker机器建立连接以及发送消息的?
第四块就是从MQ获取消息的那些系统,这些系统一般称之为消费者。
仔细想想消费者里其实也隐藏了很多的技术细节,比如到底是Broker主动推送消息给消费者?还是消费者自己从Broke里拉取消息?这些也都很值得深究。
那么到底从哪儿入手开始呢?因为自己的思路是边研究边落地,最好是初步搞清楚一些RocketMQ的架构设计细节,然后就申请一些机器开始落地部署了,可以测试测试,然后尝试让一些生产系统开始使用他。
一次关于RocketMQ NameServer设计原理的技术分享
要部署RocketMQ,就得先部署NameServer,那么这个NameServer到底可以部署几台机器呢?
是一台机器?还是可以部署多台机器?如果部署多台机器,他们之间是怎么协同工作的。
NameServer,首先是支持部署多台机器的。也就是说,NameServer是可以集群化部署的。
那为什么NameServer要集群化部署?
最主要的一个原因,就是高可用性。
因为大家都知道,NameServer是集群里非常关键的一个角色,他要管理Broker信息,别人都要通过他才知道跟哪个Broker通信,所以没了他就会很麻烦!
那么如果NameServer就部署一台机器的话,一旦NameServer宕机了,岂不是会导致RocketMQ集群出现故障?
所以通常来说,NameServer一定会多机器部署,实现一个集群,起到高可用的效果,保证任何一台机器宕机,其他机器上的NameServer可以继续对外提供服务!
Broker是把自己的信息注册到哪个NameServer上去?
下一个问题:Broker在启动的时候是把自己的信息注册到哪个NameServer上去的?
有的人可能会猜测,是不是这样,比如一共有10台Broker机器,2个NameServer机器,然后其中5台Broker会把自己的信息注册到1个NameServer上去,另外5台Broker会把自己的信息注册到另外1个NameServer上去。
那么到底是不是这样呢?
答案是:不对
这样搞有一个最大的问题,如果1台NameServer上有5个Broker的信息,另外1个NameServer上有另外5个Broker的信息,那么此时任何一个NameServer宕机了,不就导致5个Broker的信息就没了吗?
所以这种做法是不靠谱的,会导致数据丢失,系统不可用。
因此正确答案是:每个Broker启动都得向所有的NameServer进行注册
也就是说,每个NameServer都会有一份集群中所有Broker的信息。
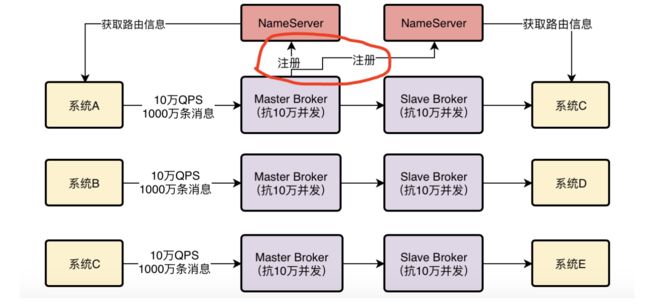
在这个图里就示范了一个Master Broker得向两台NameServer都进行注册的情况,这才是真正的情况。
系统如何从NameServer获取Broker信息?
扮演生产者和消费者的系统们,如何从NameServer那儿获取到集群的Broker信息呢?
他们需要知道集群里有哪些Broker,才能根据一定的算法挑选一个Broker去发送消息或者获取消息。
有两种办法:
第一种办法是这样,NameServer那儿会主动发送请求给所有的系统,告诉他们Broker信息。
这种办法靠谱吗?明显不靠谱,因为NameServer怎么知道要推送Broker信息给哪些系统?未卜先知吗?
第二种办法是这样的,每个系统自己每隔一段时间,定时发送请求到NameServer去拉取最新的集群Broker信息。
这个办法是靠谱的,没有什么明显的缺陷,所以RocketMQ中的生产者和消费者就是这样,自己主动去NameServer拉取Broker信息的。
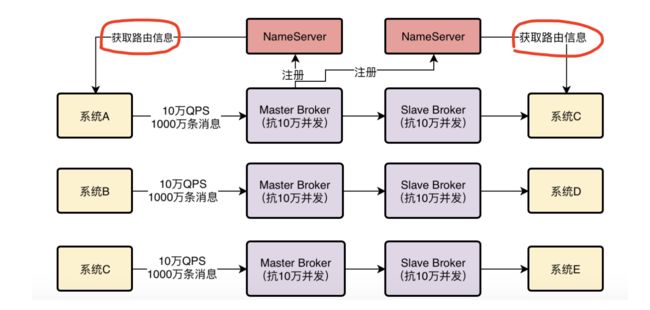
顺便在这里解释一下,图里的路由信息,大致可以理解为集群里的Broker信息以及其他相关的数据信息
通过这些路由信息,每个系统就知道发送消息或者获取消息去哪台Broker上去进行了,这起到一个把消息路由到一个Broker上的效果,所以一般我们把这种信息叫做路由信息。
如果Broker挂了,NameServer是怎么感知到的?
下一个问题,现在一个Broker启动之后向NameServer注册了,每个NameServer都知道集群里有这么一台Broker的存在了,然后各个系统从NameServer那儿也拉取到了Broker信息,也知道集群里有这么一台Broker
但是如果之后这台Broker挂了呢?
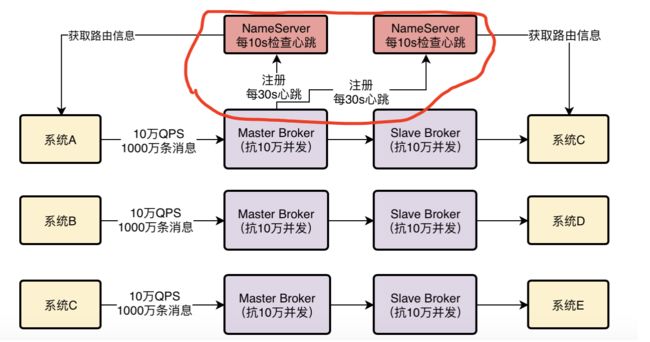
要解决这个问题,靠的是Broker跟NameServer之间的心跳机制,Broker会每隔30s给所有的NameServer发送心跳,告诉每个NameServer自己目前还活着。

每次NameServer收到一个Broker的心跳,就可以更新一下他的最近一次心跳的时间。
然后NameServer会每隔10s运行一个任务,去检查一下各个Broker的最近一次心跳时间,如果某个Broker超过120s都没发送心跳了,那么就认为这个Broker已经挂掉了。
Broker挂了,系统是怎么感知到的?
下一个问题,如果Broker挂掉了,那么作为生产者和消费者的系统是怎么感知到的呢?难道必须得NameServer发送请求给所有的系统通知他们吗?
这个是不现实的,之前已经说过了,NameServer去发送这个东西非常的不靠谱。
但是如果NameServer没有及时通知给那些系统,那么有没有可能出现这样一种情况,刚开始集群里有10个Broker,各个系统从NameServer那里得知,都以为有10个Broker。
结果此时突然挂了一个Broker,120s没发心跳给NameServer,NameServer是知道现在只有9个Broker了。
但是此时其他系统是不知道只有9个Broker的,还以为有10个Broker,此时可能某个系统就会发送消息到那个已经挂掉的Broker上去,此时是绝对不可能成功发送消息的。
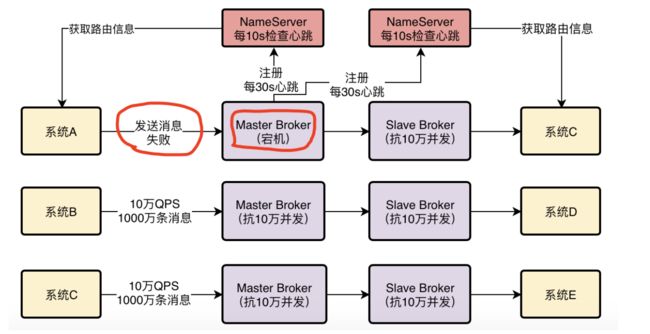
大家可以想一下,如果确实是那个情况,可以有两种解决办法。
首先,你可以考虑不发送消息到那台Broker,改成发到其他Broker上去。
其次,假设你必须要发送消息给那台Broker,那么他挂了,他的Slave机器是一个备份,可以继续使用,你是不是可以考虑等一会儿去跟他的Slave进行通信?
总之,这些都是思路,但是现在我们先知道,对于生产者而言,他是有一套容错机制的,即使一下子没感知到某个Broker挂了,他可以有别的方案去应对。
而且过一会儿,系统又会重新从NameServer拉取最新的路由信息了,此时就会知道有一个Broker已经宕机了。